今天OS课上老师提到影响缺页次数的因素中有一个是 程序的局部性越好,越不容易缺页,并举了个关于双重for循环顺序的选择问题作为例子。
我回去也查询资料研究了一下这个问题。
何为程序的局部性(locality)
程序的局部性原理是指程序在执行时呈现出局部性规律,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。也就是说,程序倾向于引用邻近于其他最近引用过得数据项,或者最近引用过的数据项本身。我的理解就是:通过利用“缓存”来提高程序运行效率
程序的局部性又通常有两种不同的形式:时间局部性(temporal locality)和空间局部性(spatial locality).
时间局部性:被引用过一次的存储器位置在未来会被多次引用
空间局部性:如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。也就是说靠近当前正在被访问内存的内存内容很快也会被访问。
理论分析
先以一维数组为例,考虑对程序数据引用的局部性。
借用《深入理解计算机系统》书中的例子进行分析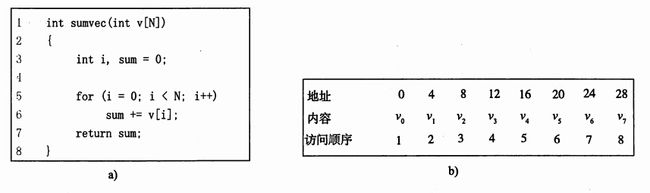
sumvec函数中数组v的元素是被顺序读取的,一个接一个,按照它们存储在存储器中的顺序。(假设地址从0开始).因此对于变量V,函数有很好的空间的局部性。因此这个函数有良好的局部性。
向上面例子中按顺序、连续的对v的引用,称为步长为1的引用模式(相对于元素大小)。同理,在一个连续的向量中,每隔k个元素对向量进行访问,称为步长为k的引用。一般来说,随着步长的增加,空间局部性会下降。
再考虑二维数组
图中函数是对一个二维数组求和(M=2,N=3)。双重嵌套循环按照行优先的顺序读取数组的元素。因此函数具有良好的空间局部性,因为它按照数组被存储的行优先顺序来访问这个数组,因此得到的是一个步长为1的引用模式和良好的空间局部性。从而使得程序运行效率得到提高。
但我们更换读取顺序的时候,交换i和j的循环。如下图所示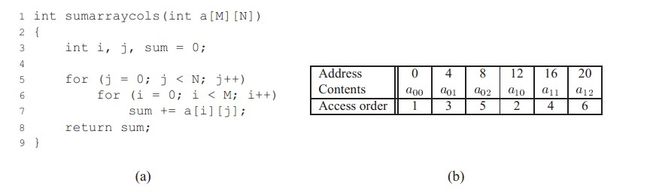
这时候发生了巨大的变化!函数的空间局部性变得很差,因为他按照列顺序来扫描数组,而不是按照行顺序。因为C数组在存储器中是按照行顺序的,结果这里就得到的是步长为N的引用模式。从而使得程序效率降低。
代码实例测试
实例
#include
#include
#include
int main()
{
int a[500][500];
int i,j;
clock_t start, finish;
double duration;
start = clock();
for (int k = 0; k < 1000; k++)//循环放大时间
{
for(i=0; i<500; i++)
{
for(j=0; j<500; j++)
{
a[i][j]=i;
}
}
}
finish = clock();
duration = (double)(finish - start) / CLOCKS_PER_SEC;
printf( "%f seconds\n", duration );
start = clock();
for (int k = 0; k < 1000; k++)//循环放大时间
{
for(j=0; j<500; j++)
{
for(i=0; i<500; i++)
{
a[i][j]=i;
}
}
}
finish = clock();
duration = (double)(finish - start) / CLOCKS_PER_SEC;
printf( "%f seconds\n", duration) ;
return 0;
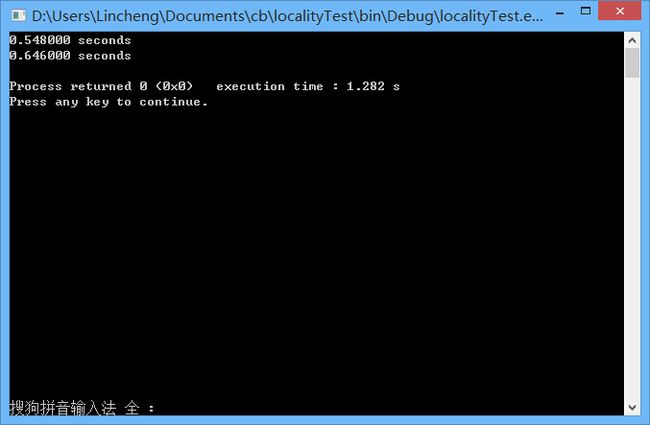
} 运行结果1
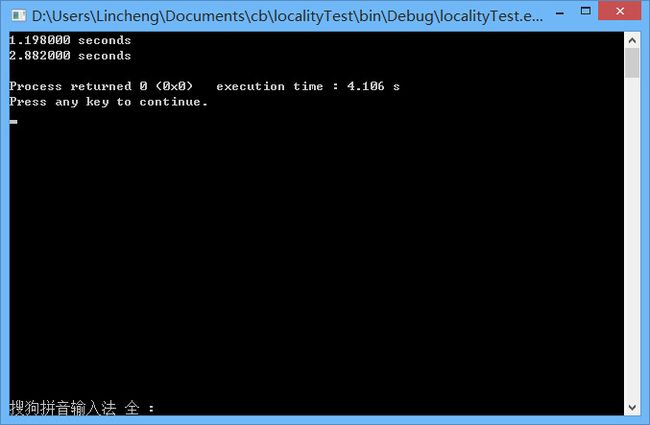
可以发现当行列数相同的时候,按照行顺序扫面的效率要高一些。也符合之前的理论分析.
运行结果2
当我把数组定义改为a[10][10000]的时候,测试结果如下,依旧为行顺序扫描效率较高。
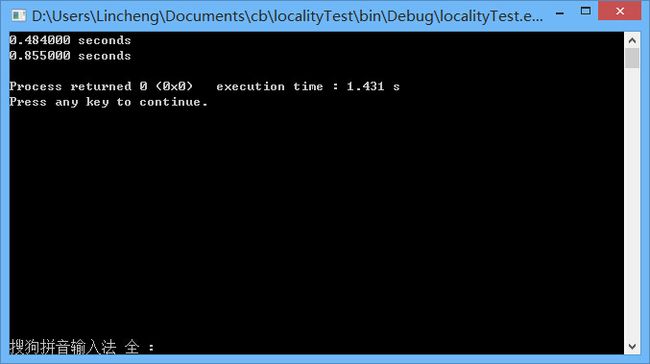
运行结果3
数组改为a[10000][10]后,测试结果如下,依旧为行顺序扫描效率较高。
小结
通过对双重循环不同循环顺序的效率分析,初步理解了局部性原理。也就是说现代的计算机体系的存储技术至少都用了局部存储思想,即CPU提取内存的一个位置的数据放到cache中的同时,也会把其附近的数据也提取到cache中,如果内存以行优先存储方式(注意这个前提!),则提取Array[0][0]位置的数据的同时,则也会顺便把"Array[0][1], Array[0][2],tArray[0][3], Array[0][4]..."等数据提取出来存放在缓存中。这样在后边连续的几次循环中均可以命中缓存,从而减少缓存失效,提高程序的运行效率。
参考资料
维基百科
计算机体系结构与程序性能
《深入理解计算机系统》