运用机器学习(含深度学习)方法处理数据问题的完备流程总结+实践经验细节+代码工具书(1):什么是好的机器学习模型/如何得到好的模型+前置数据分析
博客简介:
关键字:数据处理完整流程代码+实践经验+算法特性思考与特点总结
不论是数据科学,传统机器学习还是深度学习,相关的理论讲解和代码资源已经十分丰富,但是当我们实际想要使用代码实现这些理论的时候,却总觉得机器学习或者数据科学的任务流程会有点复杂:繁琐的前置数据分析和处理,充满各种细节的模型搭建与训练,不同的模型分析和评价等等,若要完整地走完所有的流程,需要考虑到的东西多之又多,哪怕一个简单的数据分析问题,所需的代码量也不可小视,但是好在不论是传统机器学习还是深度学习,问题大概的处理流程是一定的,在这里将机器学习任务的大概流程总结成为:前置数据分析阶段,数据处理阶段,搭建训练和评价模型阶段,如果我们可以将整个数据处理的流程菜谱化,把每一个主要流程中可能需要的各个方法提前写好,那么在处理实际问题的时候,码代码的工作量就可以降低到最少,最后的工作就是简单的从各个流程中选出你要的代码‘积木‘,然后将它们拼接起来,实现真正的一劳永逸,这也是本人撰写本文的主要动机。因此本文本质上具备着工具书的性质,尝试对利用传统机器学习和深度学习处理数据科学问题的流程进行‘完全‘整理,并将各个流程中重要的常用方法与代码进行组织和改进,缩短在实际项目中的工作时间,由于是在尝试对基本流程进行完全整理,所以会尽可能包含所有处理一般数据问题时可能会用到的代码**(将持续更新补充),让大家在碰到问题时只要顺着这本‘工具书’中的流程走下去,把它当成一个模版或者流水线(流程骨架),在其中挑选需要用到的代码块,简单地组织在一起就可以出色地完成任务。
因为以着‘工具书‘为目标进行编写和整理, 因此博客基本不会涉及算法和方法背后的理论介绍,默认本文的读者已经熟悉了基本的机器学习算法和基础统计学方法,若读者对部分名词感到陌生,利用网上众多的优秀资料也可以快速进行学习,同时本文加入了很多对于技术细节的思考与算法运用的经验总结。
最后希望这篇文章可以帮助到大家。
在后续的学习工作中我会持续对此博客系列进行更新,希望可以让博客内容更加完备和准确,同时在之后会尝试将更加前沿的数据科学技术逐渐融合于其中。
什么是好的机器学习模型/如何得到好的模型+数据分析阶段:(you are here)
前置数据处理阶段: https://blog.csdn.net/weixin_44563688/article/details/86558939
非神经网络机器学习模型的搭建,训练及评价阶段: https://blog.csdn.net/weixin_44563688/article/details/86568400
神经网络机器学习模型的搭建,训练及评价阶段: https://blog.csdn.net/weixin_44563688/article/details/88884468
本篇为《机器学习完备流程总结+实践经验细节+代码工具书(1)》,主要介绍前置分析与数据分析相关流程与对应代码(基于python3):
机器学习模型的本质与误差来源:
理解这个问题和我们做项目没有直接的关系,但深入理解机器学习模型的运作原理与特点可以帮助我们合理地规划整个任务流程,系统性地对模型进行后续优化与改进以及清晰地意识到训练完毕的模型在实际应用中潜藏着的风险。
1.优化机器学习模型的目标:
训练和优化机器学习模型的目标简单来说是希望提高模型在测试数据集上的表现(需要注意这只是一个比较general的说法,事实上某些时候模型在测试数据集上的表现太好并不是一件好事,其中一个原因可见下方机器学习的习惯中的相关论述)。进一步来说我们希望平衡模型的bias和variance,关于variance和bias对于模型表现的具体影响可以通过下图理解:

关于variance和bias这里有几个重要结论:
- 对于一般机器学习模型,模型的bias越大意味着variance越小,反之依然。
- variance越大的模型一般能力越强,bias越大的模型一般较为稳定。稳定就意味着对于数据的精度和数量的要求较低,结果虽然不会太好但也不可能太坏(模型上限低下限高)。而能力强大的high variance模型在训练时不仅要求trainset数据数量充足,还对训练数据中的噪音和数据缺陷十分敏感,根据训练数据的多少和数据的质量的不同,最终模型表现的上下限会有很大差距:模型可能非常好,也可能非常坏。
- 我们训练和优化模型的准则是:要在平衡bias与variance相对大小的基础上寻求同时降低bias和variance的可能。
2.机器学习模型的能力上限与改进时的主要着手点:
所有的机器学习模型可以分为Generative model(Naive Bayes,Mixture models,Hidden Markov models,Restricted Boltzmann Machines,etc)以及Discriminative mode(Linear Regression, Logistics Regression,SVM,Random forest,Neural network etc.)两类,如果我们的输入(features)是X,输出(labels or regression object)是y,generative model本质是在寻找一个函数h(X,y)来模拟P(X,y),而dicriminative model本质是在寻找一个函数h(X,y)来模拟P(y | X),两者的本质都是用一些数学方法来逼近训练数据集中暗含着的P(X,y)或者P(y | X),因此,generative model的能力极限是训练集中存在着的P(X,y),discriminatve model能力极限是训练集中存在着的P(y | X),如果训练集中的数据相较于全体数据分布存在某种倾向或者偏离,那么单纯使用这种数据训练出来的机器学习模型永远也不可能在真实数据上有优秀的表现。
我们需要赋予P(X,y)或者P(y | X)某个具体的形式才能得到具体的优化对象,这个所谓的形式就是我们具体使用的数学模型(机器学习模型),需要明白的是所有的机器学习模型都存在或多或少的优缺点,不存在一个可以完美适用于所有的数据机器学习模型,那么如何选择适合我们数据的模型,我们选择的模型又有多适合我们的数据呢?而模型的选择又会对最终的模型表现产生很大影响,因此机器学习算法的选择直接决定了我们模型最终的表现。
大多数的机器学习算法均为参数学习,意味着我们优化(训练)模型时的优化对象是模型中的各个参数,对于非限制的凸算法(线性回归)我们可以获得确定的解析解,但大多数的机器学习算法的优化对象都是一个非线性非凸的函数,这也就意味着我们必须通过梯度下降或者牛顿法(对于神经网络则存在adam,SGD等优化方法)来一步一步地优化参数,那么使用什么样的优化方法来优化模型,也从根本上决定了我们模型最后的表现能达到多好。
对于复杂模型,我们需要对其中的超参数进行调参才能确定最佳的超参数组合,因此超参数的调参也是优化模型时必须考虑的方法,同时对于SVM,神经网络等强力模型,为了缓解overfitting一定的regularization方法是必须要考虑的。
最后值得一提的是,对于某些机器学习问题我们可以从通过对目标问题进行转化来提高模型表现:比如我们希望从某张RGB图片中分类出天空的蓝色和非天空蓝的其他颜色,这是个单纯的二分类问题,我们需要准备label为天蓝色和非天蓝色的训练数据集然后训练一个二分类器,但是由于非天蓝色的数据中包含着所有非天蓝的颜色,导致模型在实际的分类时会非常倾向于将所有颜色分类为天蓝,影响了模型在实际情况下的表现。为了避免这种情况的发生,我们应该训练一个可以分类天蓝,红色,黄色,黑色…的多分类器,然后在实际情况中只将分类结果中蓝色概率最大的pixel分类为蓝色。
上述一段文字介绍了机器学习模型的主要误差来源,总结之后,那么也就知道了我们改进模型表现时的所有着手点:
- 提高训练数据质量(精度,低噪音,分布代表性等)和数据数量
- 根据数据特点和任务目标选择更合适的机器学习模型
- 根据模型和硬件计算能力采用合适的参数优化方法
- 积极地调参,对于复杂模型尝试regularization方法
- 通过目标问题的转化提高模型表现
一般情况下,最重要的两个因素是模型的选择和训练数据的质量,针对模型选择的问题,推荐采取的策略是:与其不停尝试不同的机器学习模型,费时费力的调节超参数不断试验不如直接使用集成学习,通过集成学习降低主观的模型选择产生的Bias:
如上文所说,模型的误差可以分类为Bias与Variance,提高模型表现的目标也就可以归结为降低模型的variance与bias。若使用非神经网络的传统机器学习算法时,通过集成学习可以使得子模型之间取长补短,显著降低模型整体的bias同时基本不提高甚至降低模型的variance,而对于神经网络来说,由于模型本身的低bias,大多数时候我们只需要考虑调参以及加入regularization方法来降低模型的variance即可。
至于提高数据的质量和数量,应该确保我们的训练数据集尽可能和实际使用时的测试数据集有着相同的概率分布,若存在分布的轻微差异可以设计分布转移算法进行转移,同时训练数据应尽可能的具有代表性,各class数据比例均衡/合理同时涵盖尽可能大的feature space,关于数据数量可以使用数据增强等方式来加大训练数据的整体数量来避免模型的overfitting。
3.机器学习模型的习惯:
如前所述,机器学习模型本质是一个用来拟合概率分布函数统计学模型,原则上,当一个模型足够强大(deep learning)时,使用越多的feature模型会有越好的表现,但是这里需要知道,在训练数据集,甚至测试数据集上越好的表现不代表越好的模型,那么如何理解在测试数据集上的表现好未必一定是好事这个结论呢?设想我们有一个CNN模型,我们用这个模型来处理一个图片中人物头发颜色的分类问题,当我们一股脑地把图像的全部内容传给model,而不使用任何attention model的时候,模型会尝试利用图片中所有信息来判断图片中人物的头发颜色,包括人物的发型,肤色,穿着,表情甚至背景环境的情况:用训练好的模型对输入图片进行梯度求导,会发现其实模型在分类发色的时候更多的是在寻找图中人物肤色的信息(高梯度点很多分布在脸的范围上而非头发),原因很简单,对于一个general的图片训练数据集来说,人物肤色白,那么头发就很可能是金色或者黑色,肤色黑头发基本只可能是黑色,而且肤色信息相比于头发信息往往更好定位与提取,机器学习十分聪明地观察和利用到了这点,像那头聪明的小马汉斯一样十分出色地完成了任务(大多数简单机器学习模型的本质就是聪明的汉斯:https://en.wikipedia.org/wiki/Clever_Hans),但是它其实是在用肤色来分类头发,在某些反常情况下,比如染了金发的黑人出现时,模型就很可能会犯错,这种情况不同于1中提到的问题,不能单纯归结于模型对于训练数据的过度拟合,相反应该说是机器学习模型的一种习惯,这种习惯在大多数情况下是有益的(我们就是希望机器学习模型可以利用更多的feature来进行更好的判断和预测),但是本质上,这种习惯会让模型并不安全与可靠,从某种程度上决定了机器学习模型能力的天花板。 如果你需要一个十分robust的机器学习模型,在这个例子中,你希望模型能够先成功提取头发的信息,然后再基于头发的信息进行后续的发色分类,那么使用一些tricky的结构是必不可少的。

前置数据分析的主要目的:
数据分析阶段我们的主要目是:
1.对数据的量级有一个大概的评估:
确定数据中有多少data point,每一个data point有多少个feature,明白这点主要有两个作用,其一是帮助我们选择具体的模型,简单来说,数据的复杂度应与模型的复杂度相匹配。用一个resNet-inception-V2去处理一个pixel颜色的分类问题,一方面严重浪费计算资源和我们的时间不说,结果也存在很大很大的过拟合风险,同理,我们也不可能使用线性回归去处理一般图片的分类问题,因为模型的能力完全不足以抓取和利用数据中隐藏着的核心信息。
2.确保所用的数据feature有用且独特:
关于这点的原因部分介绍于之上的‘机器学习的习惯‘,但是更多的是出于避免过拟合的考量,特征选择准确,简单的模型也可以有着非常不错的表现,而能用简单模型获得满意准确率的时候,为什么我们要使用复杂的模型呢?确定feature显著程度具体的方法有相关性系数(主要),条件熵估计,线性回归系数,卡方检验等。
至于feature的独特,则是指数据feature和feature之间的correlation系数不可以过大,否则会增大过拟合的风险。
3.大概了解数据中的噪音与数据的均衡与完整程度:
现实世界中所有数据都是noisy的,意味着我们的数据往往会一定程度地偏离真值,同时实际情况中我们到手的数据也往往是不完备的,数据中存在着缺失值,错误值以及outlier(常见于计算机视觉问题)等各种各样的缺陷,而根据数据里噪音分布和量级大小的不同以及缺陷的多少,我们也应该随之进行不同的数据处理和选择不同的机器学习模型进行拟合:比如线性回归模型要求数据中的噪音呈0均值的高斯分布,支持向量机(SVM)是一种对数据精度和完整性要求较高的机器学习模型,当我们数据的精度较低或者缺失了部分feature时,SVM一般不是一个好选择。反之,大噪音和数据缺失对于随机森林算法表现的影响则微乎其微。
至于数据的均衡程度指训练数据有足够的代表性,训练数据feature的分布应尽可能与实际数据相似,同时若为分类问题则不同class对应的数据数量(一般情况)不应该差距过大。
4.从数据中提出新的问题:
在数据分析的阶段,我们还希望可以总结数据中某些有趣的规律,从数据中提出/发现一些新的有价值的问题以进行后续的研究。
开始流程:
step1:引入常用包:
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
from torch.autograd import Variable
import torch.utils.data as Data
import os
import torchvision.models as models
import seaborn as sns
import pandas as pd
import torchvision as tv
import torchvision.transforms as transforms
#import Augmentor #图像数据增强库
step2:更改工作目录到数据源所在路径,方便之后数据的读取,处理和保存。
os.chdir(‘####your path#####')
os.chdir('/Users/sdret/Desktop/jupyter_home')
print(os.getcwd())
print(os.listdir())
step3:当我们拿到数据后,首先希望对于数据的大概性质有一个全面的了解,这个时候我们可以将数据转换成DataFrame并利用pandas中的相关方法对数据进行大概的了解与分析。
#这里假如读取的数据为csv格式,实际情况中若数据格式不同可以使用其他方法读取数据并将其转换为DataFrame
data = pd.read_csv('###name of your data###')
#展示数据前五行,认识数据的大概组织形式,即有什么feature,各个feature的表示形式是什么,对于数据首先有一个直观的认识。
data.head()
output example: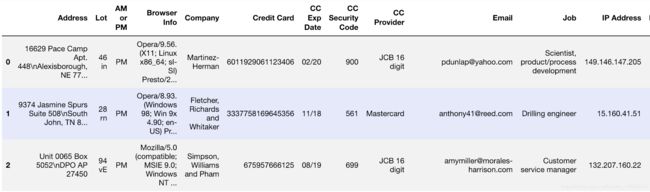
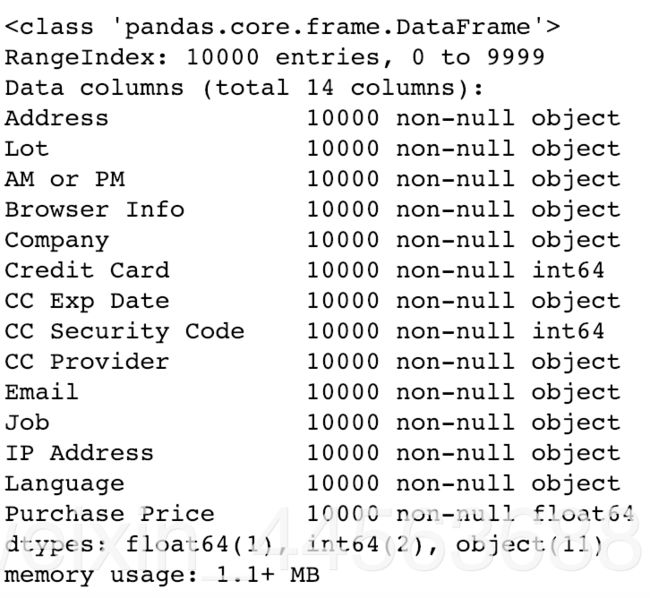
#查看数据数量以及feature的数据类型,内存占用大小,记录格式以及检查有无缺失值(或者缺失值的数量)
data.info()
output example:
#了解数据中各个数值的大概分布范围以及各个feature的重要统计量
data.describe()
output example:

此外还可使用其他DataFrame中的方法进一步认识和组织数据,提供以下一些常用方法:
#'xxx'为列名
data['xxx'].value_counts(dropna=False)
data[pd.notna(data['xxx'])]['outputs_class'].value_counts()
data.isnull().any()
data['xxx'].mean()
data['xxx'].max()
data['xxx'].min()
data = pd.concat([data_1,data_3],axis = 1)
data['xxx'].value_counts() #’xxx’中各个数值出现的次数统计,默认倒序
data.sort_values('xxx',ascending = False,inplace = True) #将数据按照某列中的值以一定顺序进行排列
data.drop('xxx',axis = 1,inplace = True) #if inplace为True,则替换原数据
data[xxx'].apply(lambda x: x.split(''))
data['xxx'].nunique()
one_hot = pd.get_dummies(data['xxx'])
index_labek = pd.factorize(df1['xxx'])
data = data.join([one_hot_1,one_hot_2,one_hot_3])
data = data.rename(columns={0.0:'pox1',0.5:'pox2',0.83:'pox3'})
data.hist(figsize=(20,20))
step4:在大概认识了解以及初步组织数据之后,我们可以借助可视化来更进一步分析数据,观察feature分布的特点以及彼此之间的相关程度,这一步的结果将直接影响到我们之后如何对数据进行处理。这里主要使用seaborn以及matplotlib。下列代码中使用的数据类型默认为DataFrame(行为sample,列为feature),若为其他类型做出相应修改即可:
#plot出某一feature的分布情况,bins为bar的宽度,根据实际情况改变
sns.distplot(data['xxx'],bins = 15)
output example:
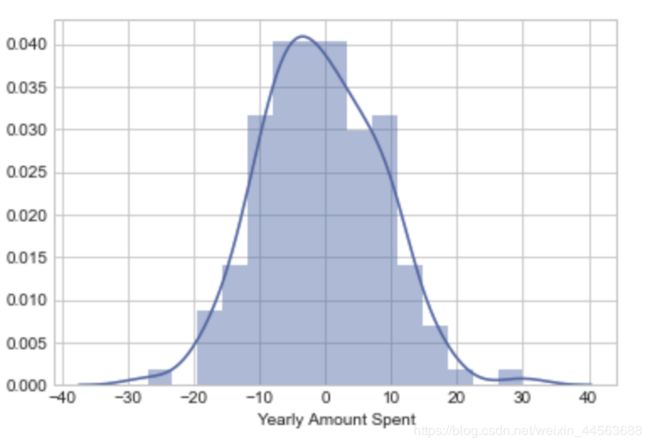
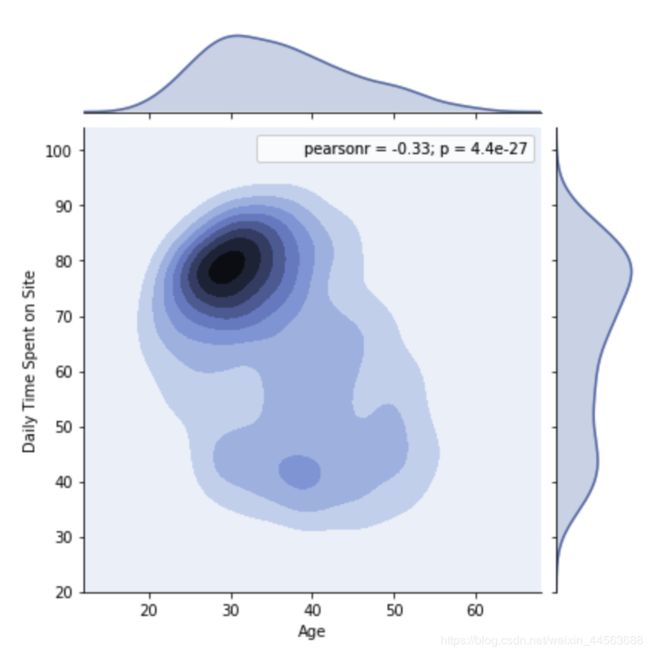
#某两个feature各自的分布以及相关性分析
#可以改变hue这个参数获得更加好看的分布图
sns.set_style("whitegrid")
sns.jointplot(data['###feature1###'],data['###feature2###'])
#or
sns.jointplot(data['###feature1###'],data['###feature2###'],kind = 'hex')
#or
sns.jointplot(data['###feature1###'],data['###feature2###'],kind = 'kde')
output example:

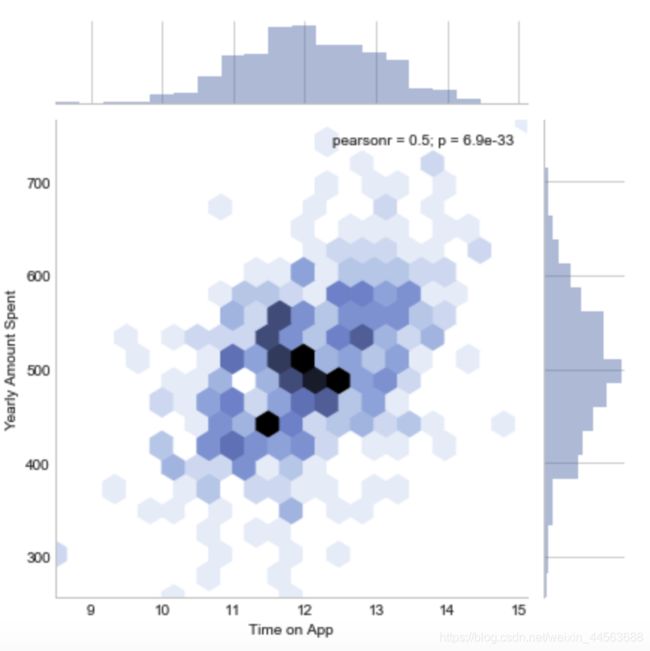
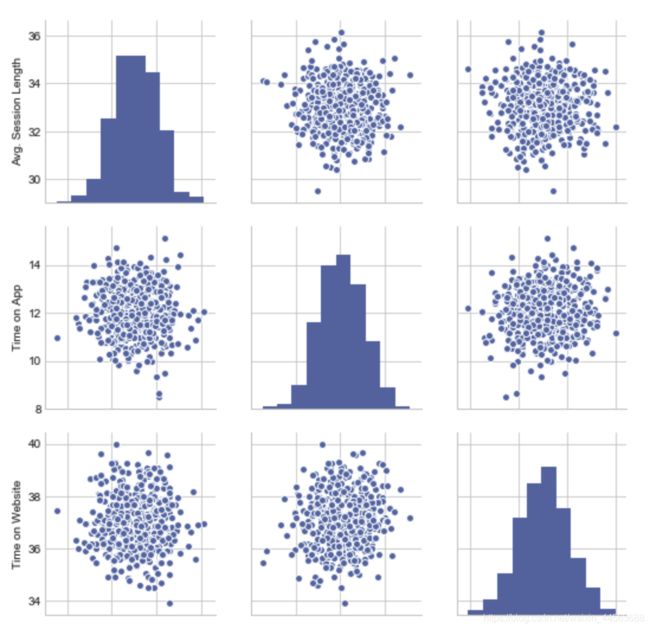
#plot多个feature各自的分布以及可视化两两分布之间的相关性
#处于对角线上的图为该feature的分布情况,其他格点为该行与
#列对应feature的相关性plot,可以对于所有feature两两之间的
#相关性有一个直观的认识,从而更好确立之后要研究的科学问
#题以及进行相关分析
sns.pairplot(data)
output example:
#使用kde来表示两个feature的分布相关性
sns.kdeplot(data['###feature1###'],data['###feature2###'],cmap = 'plasma',shade = True,shade_lowest = False)
output example:

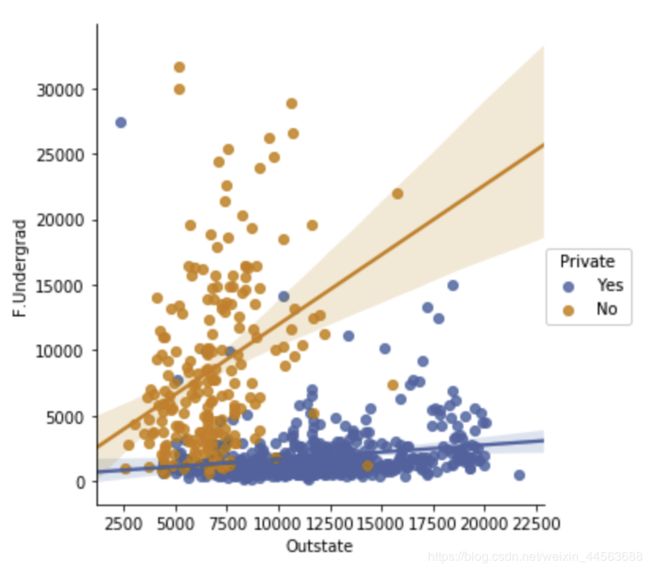
#plot出两feature之间的相关关系以及线性拟合之后的直线
sns.lmplot(x = '###column1###',y = '###column2###',data = data,hue = '###column3###')
output example:

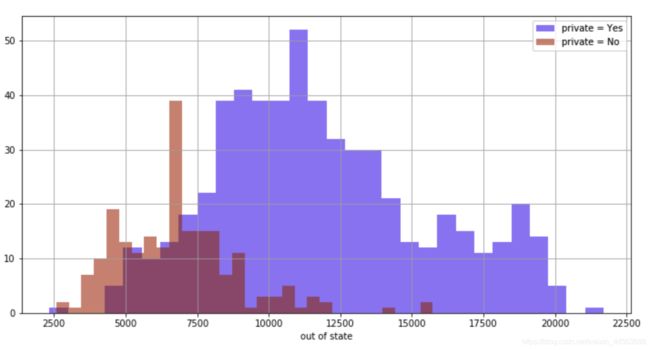
#两类别samples某一feature的hisogram,这里直接po上了
#之前项目的源代码,实际需要时只要做出相应修改即可,alpha
#为bar的透明度,要求数据为DataFrame。
plt.figure(figsize = (12,6))
col[col['Private']== 'Yes']['Outstate'].hist(alpha = 0.5,color = 'blue',bins = 30,label = 'private = Yes')
col[col['Private']== 'No']['Outstate'].hist(alpha = 0.5,color = 'red',bins = 30,label = 'private = No')
plt.legend()
plt.xlabel('out of state')
output:
#等高线图
def f(x,y):
# the height function
return (1 - x / 2 + x**5 + y**3) * np.exp(-x**2 -y**2)
n = 256
x = np.linspace(-3, 3, n)
y = np.linspace(-3, 3, n)
X,Y = np.meshgrid(x, y)
plt.contourf(X, Y, f(X, Y), 8, alpha=.75, cmap=plt.cm.hot)
C = plt.contour(X, Y, f(X, Y), 8, colors='black', linewidth=.5)
plt.clabel(C, inline=True, fontsize=10)
plt.xticks(())
plt.yticks(())
output:
#计算各个feature之间的协方差系数,从而得到协方差矩阵,
#利用heat map对协方差协方矩阵进行可视化。若两feature
#之间的相关性过大,则可以考虑drop掉其中一个或者使用
#PCA等降维方法进行降维处理。
corr = data.corr()
sns.heatmap(corr,annot = True)
output example:

#同样利用heatmap,可直观检查缺失值的有无以及分布情况,
#黄色部分为缺失值,关于缺失值的处理方法与代码在下一篇数
#据处理中会有详细的交待。
sns.heatmap(data.isnull(),yticklabels = False,cbar = False,cmap = 'viridis')
output example:

step5:检查数据是否存在极端值,具体措施取决于数据的具体分布与形式,因此无法给出一个普遍且通用的办法:可供选择的常用方法有:IQR outlier detection,偏差检测,聚类,最邻近,LOF,设置欧氏,马氏距离阈值等(后续对所有方法进行补充)。
偏差检测:将处于N倍方差之外的数据视为极端之并
去除:
#参数:
#N:去除均值加减N倍方差之外的所有数据,一般常用的N值有3,4,5
#df:dataframe形式的数据
def drop_noisy(df,N):
df_copy = df.copy()
df_describe = df_copy.describe()
for column in df.columns:
mean = df_describe.loc['mean',column]
std = df_describe.loc['std',column]
minvalue = mean - N*std
maxvalue = mean + N*std
df_copy = df_copy[df_copy[column] >= minvalue]
df_copy = df_copy[df_copy[column] <= maxvalue]
return df_copy
step6:若后续的机器学习模型要处理一个分类任务,而且输入数据维度较高,那么我们有必要对数据的可分性进行分析从而有一个预期的最终分类效果,这里有类似PCA,LDA等很多方法可以选择,将高维数据降维至我们可以可视化的2维或者3维来判断数据的可分性。
#部分关键参数介绍:
#for PCA LDA TSNE:
#n_components:结果空间的维度,
#for TSNE:
#perplexity:5-50,数据集越大,需要的参数值就越大
#early_exaggeration:默认为12.0,不是很关键
#verbose:训练过层是否可视
#method:对于大苏局使用默认值,小数据使用exact
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.manifold import TSNE
pca = PCA(n_components=2)
lda = LinearDiscriminantAnalysis(n_components=2)
tsne = TSNE(n_components=2)
temp_1 = pca.fit_transform(data)
temp_2 = lda.fit(data, y).transform()
temp_3 = tsne.fit_transform(data)
#这里只列出了plot 经过tsne降维后数据分布的代码,
#PCA和LDA只有替换temp_3为temp_1或者temp_2即可
plt.scatter(temp_3[:,0],temp_3[:,1],alpha=.5)
plt.yticks(())
plt.xticks(())
plt.show()
下一篇将详细介绍数据预处理中的常用方法与相关代码~
前置数据处理阶段: https://blog.csdn.net/weixin_44563688/article/details/86558939
参考:
Pandas 中 DataFrame 结果删除噪声数据的一种方法
https://blog.csdn.net/weixin_44563688/article/details/86535274
转载请告知作者,并附上原始CSDN博客链接。