MAC下Hadoop环境配置(模拟分布式模式)
背景环境
mac环境:
MacBook Pro (Retina, 15-inch, Mid 2015) 处理器:2.2 GHz Intel Core i7 内存:16 GB 1600 MHz DDR3 图形卡:Intel Iris Pro 1536 MBjava环境(已经配置好)
java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)Hadoop集群支持三个模式:
(1)本地/独立模式:下载Hadoop在系统中,默认情况下之后,它会被配置在一个独立的模式,用于运行Java程序。
(2)模拟分布式模式:这是在单台机器的分布式模拟。Hadoop守护每个进程,如 hdfs, yarn, MapReduce 等,都将作为一个独立的java程序运行。这种模式对开发非常有用。本博客安装的方式。
(3)完全分布式模式:这种模式是完全分布式的最小两台或多台计算机的集群.
安装及配置Hadoop
(1)安装Hadoop(brew前提已经安装好)
[zhuqiuhui@localhost:~]$ brew install Hadoop==> Renamed Formulae
osh -> etsh
==> Deleted Formulae
autotrace libtess2 snescom xplanetfx
==> Using the sandbox
==> Downloading https://www.apache.org/dyn/closer.cgi?path=hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
==> Best Mirror http://apache.fayea.com/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
######################################################################## 100.0%
==> Caveats
In Hadoop's config file:
/usr/local/opt/hadoop/libexec/etc/hadoop/hadoop-env.sh,
/usr/local/opt/hadoop/libexec/etc/hadoop/mapred-env.sh and
/usr/local/opt/hadoop/libexec/etc/hadoop/yarn-env.sh
$JAVA_HOME has been set to be the output of:
/usr/libexec/java_home
==> Summary
/usr/local/Cellar/hadoop/2.8.0: 25,169 files, 2.1GB, built in 49 minutes 15 seconds由上知,安装的Hadoop版本为hadoop-2.8.0。
(2)配置ssh免密码登录,用dsa密钥认证来生成一对公钥和私钥:
[zhuqiuhui@localhost:~]$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa[zhuqiuhui@localhost:~]$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys[zhuqiuhui@localhost:~]$ ssh localhost配置Hadoop文件
(1)core-site.xml文件配置如下:
fs.defaultFS
hdfs://localhost:9000
dfs.replication
1
mapreduce.framework.name
yarn
yarn.nodemanager.aux-services
mapreduce_shuffle
运行Hadoop样例程序
(1)
[zhuqiuhui@localhost:~]$ cd /usr/local/Cellar/hadoop/2.8.0/libexec # 进入Hadoop的目录
[zhuqiuhui@localhost:libexec]$ bin/hdfs namenode -format # 格式化文件系统
[zhuqiuhui@localhost:libexec]$ sbin/start-dfs.sh # 启动NameNode和DataNode的守护进程
[zhuqiuhui@localhost:libexec]$ sbin/start-yarn.sh # 启动ResourceManager和NodeManager的守护进程(3)
[zhuqiuhui@localhost:libexec]$ pwd
/usr/local/Cellar/hadoop/2.8.0/libexec
[zhuqiuhui@localhost:libexec]$ bin/hdfs dfs -mkdir -p /user/robin/input # 创建hdfs目录
[zhuqiuhui@localhost:libexec]$ bin/hdfs dfs -put etc/hadoop /input # 拷贝一些文件到input目录[zhuqiuhui@localhost:libexec]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar grep /input output 'dfs[a-z.]+'17/06/29 16:53:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/06/29 16:53:13 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/06/29 16:53:13 INFO input.FileInputFormat: Total input files to process : 27
17/06/29 16:53:13 INFO mapreduce.JobSubmitter: number of splits:27
17/06/29 16:53:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1498699672044_0002
17/06/29 16:53:14 INFO impl.YarnClientImpl: Submitted application application_1498699672044_0002
17/06/29 16:53:14 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1498699672044_0002/
17/06/29 16:53:14 INFO mapreduce.Job: Running job: job_1498699672044_0002
17/06/29 16:53:20 INFO mapreduce.Job: Job job_1498699672044_0002 running in uber mode : false
17/06/29 16:53:20 INFO mapreduce.Job: map 0% reduce 0%
17/06/29 16:53:29 INFO mapreduce.Job: map 22% reduce 0%
17/06/29 16:53:34 INFO mapreduce.Job: map 41% reduce 0%
17/06/29 16:53:35 INFO mapreduce.Job: map 44% reduce 0%
17/06/29 16:53:39 INFO mapreduce.Job: map 52% reduce 0%
17/06/29 16:53:40 INFO mapreduce.Job: map 63% reduce 0%
17/06/29 16:53:43 INFO mapreduce.Job: map 70% reduce 0%
17/06/29 16:53:44 INFO mapreduce.Job: map 78% reduce 0%
17/06/29 16:53:45 INFO mapreduce.Job: map 81% reduce 0%
17/06/29 16:53:49 INFO mapreduce.Job: map 96% reduce 0%
17/06/29 16:53:50 INFO mapreduce.Job: map 100% reduce 32%
17/06/29 16:53:51 INFO mapreduce.Job: map 100% reduce 100%
17/06/29 16:53:51 INFO mapreduce.Job: Job job_1498699672044_0002 completed successfully
17/06/29 16:53:52 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=357
FILE: Number of bytes written=3828012
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=77949
HDFS: Number of bytes written=488
HDFS: Number of read operations=84
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=27
Launched reduce tasks=1
Data-local map tasks=27
Total time spent by all maps in occupied slots (ms)=132231
Total time spent by all reduces in occupied slots (ms)=16296
Total time spent by all map tasks (ms)=132231
Total time spent by all reduce tasks (ms)=16296
Total vcore-milliseconds taken by all map tasks=132231
Total vcore-milliseconds taken by all reduce tasks=16296
Total megabyte-milliseconds taken by all map tasks=135404544
Total megabyte-milliseconds taken by all reduce tasks=16687104
Map-Reduce Framework
Map input records=2016
Map output records=26
Map output bytes=613
Map output materialized bytes=513
Input split bytes=2975
Combine input records=26
Combine output records=14
Reduce input groups=13
Reduce shuffle bytes=513
Reduce input records=14
Reduce output records=13
Spilled Records=28
Shuffled Maps =27
Failed Shuffles=0
Merged Map outputs=27
GC time elapsed (ms)=1999
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=5587861504
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=74974
File Output Format Counters
Bytes Written=488
17/06/29 16:53:52 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/06/29 16:53:52 INFO input.FileInputFormat: Total input files to process : 1
17/06/29 16:53:52 INFO mapreduce.JobSubmitter: number of splits:1
17/06/29 16:53:52 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1498699672044_0003
17/06/29 16:53:52 INFO impl.YarnClientImpl: Submitted application application_1498699672044_0003
17/06/29 16:53:52 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1498699672044_0003/
17/06/29 16:53:52 INFO mapreduce.Job: Running job: job_1498699672044_0003
17/06/29 16:54:02 INFO mapreduce.Job: Job job_1498699672044_0003 running in uber mode : false
17/06/29 16:54:02 INFO mapreduce.Job: map 0% reduce 0%
17/06/29 16:54:07 INFO mapreduce.Job: map 100% reduce 0%
17/06/29 16:54:12 INFO mapreduce.Job: map 100% reduce 100%
17/06/29 16:54:12 INFO mapreduce.Job: Job job_1498699672044_0003 completed successfully
17/06/29 16:54:12 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=330
FILE: Number of bytes written=272979
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=621
HDFS: Number of bytes written=220
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2064
Total time spent by all reduces in occupied slots (ms)=2142
Total time spent by all map tasks (ms)=2064
Total time spent by all reduce tasks (ms)=2142
Total vcore-milliseconds taken by all map tasks=2064
Total vcore-milliseconds taken by all reduce tasks=2142
Total megabyte-milliseconds taken by all map tasks=2113536
Total megabyte-milliseconds taken by all reduce tasks=2193408
Map-Reduce Framework
Map input records=13
Map output records=13
Map output bytes=298
Map output materialized bytes=330
Input split bytes=133
Combine input records=0
Combine output records=0
Reduce input groups=4
Reduce shuffle bytes=330
Reduce input records=13
Reduce output records=13
Spilled Records=26
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=83
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=352845824
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=488
File Output Format Counters
Bytes Written=220(5)在localhost:50070中的Utilities标签下找到/user/zhuqiuhui/output/目录,下载part-r-00000文件:
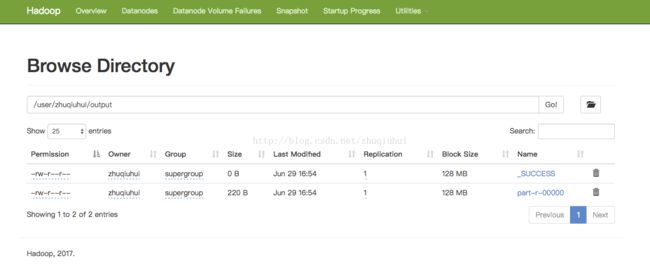
其内容是:
4 dfs.audit.logger
4 dfs.class
3 dfs.logger
3 dfs.server.namenode.
2 dfs.audit.log.maxbackupindex
2 dfs.period
2 dfs.audit.log.maxfilesize
1 dfs.log
1 dfs.file
1 dfs.servers
1 dfsadmin
1 dfsmetrics.log
1 dfs.replication参考:http://www.cnblogs.com/micrari/p/5716851.html