DPDK简单example的阅读——l2fwd
从大四开始嚷嚷着要学DPDK,一直没有静下心来看源码,拖了两年到现在才开始钻研DPDK的简单应用。二层转发是DPDK数据报处理应用里一个比较简单的example,代码只有几百行,全部看懂也大约只要半天时间。
在计算机网络中,二层是链路层,是以太网所在的层,识别的是设备端口的MAC地址。DPDK作为用户态驱动,主要的目的也就是不需要让报文经过操作系统协议栈而能实现快速的转发功能。网卡驱动在二层上的作用就是根据设定的目的端口,转发报文到目的端口。
l2fwd的运行效果如下:
将两台机器用网线相连,一台用pktgen发送数据,一台用l2fwd转发数据,l2fwd的运行界面:

由于只开了一个端口转发,所以在l2fwd的默认规则下,就是单个port自己收自己发,发送的报文数量和接收的一样多。
程序的主要流程如下:
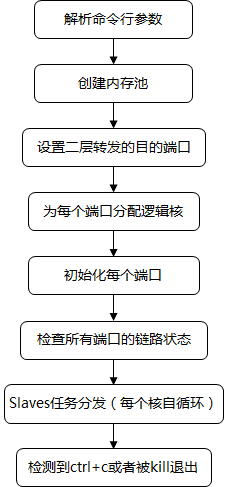
每个逻辑核在任务分发后会执行如下的循环,直到退出:

其中打印时间片在命令行参数中是可以自己设置的。
1.解析命令行参数
DPDK的命令行参数包括:EAL参数和程序自身的参数,之间用“–”隔开。比如说,运行l2fwd时,输入命令
./l2fwd -c 0x3 -n 4 -- -p 3 -q 1
其中-c和-n就是EAL参数,后面的-p和-q就是程序自带的参数
所以在代码中,解析命令行参数,也分了两步,先解析的是EAL参数
ret = rte_eal_init(argc, argv);
if (ret < 0)
rte_exit(EXIT_FAILURE, "Invalid EAL arguments\n");
argc -= ret;
argv += ret;rte_eal_init不仅有解析命令行参数的作用,以及一系列很复杂的环境的初始化,详见前一篇。当解析完了EAL的参数之后,argc减去EAL参数的个数同时argv后移这么多位,这样就能保证后面解析程序参数的时候跳过了前面的EAL参数。
ret = l2fwd_parse_args(argc, argv);
if (ret < 0)
rte_exit(EXIT_FAILURE, "Invalid L2FWD arguments\n");(其实真正做到分割的原因是系统函数getopt以及getopt_long,这些处理命令行参数的函数,处理到“–”时就会停止,所以这一机制可以被用来做多段参数)
2.创建内存池
由于DPDK在使用前需要分配大页,所以实际创建内存池时就是从这些已分配的大页中创建。
l2fwd_pktmbuf_pool = rte_pktmbuf_pool_create("mbuf_pool", NB_MBUF,
MEMPOOL_CACHE_SIZE, 0, RTE_MBUF_DEFAULT_BUF_SIZE,
rte_socket_id());其中参数包括cache_size、priv_size、data_room_size,以及在哪个socket上分配。这里的socket不是网络中的套接字,而是numa架构的socket。
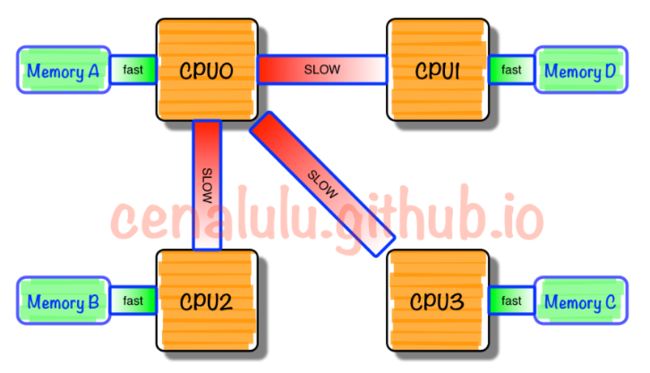
numa架构是多核技术发展的产物,在传统结构上,每个处理器都是通过系统总线访问内存,访存时间开销一致。而numa架构里,每个socket上有数个node,每个node又包括数个core。每个socket有自己的内存,每个socket里的处理器访问自己内存的速度最快,访问其他socket的内存则比较慢,如下图所示[1]。因此我们在创建缓冲区的时候就需要充分考虑到内存位置对性能的影响。
3.设置二层转发目的端口
对每个端口,先初始化设置他们的目的端口都是0,然后用一个for循环来让端口两两互为目的端口。例如:0号端口的目的端口是1,1号端口的目的端口是0;2号端口的目的端口是3,3号端口的目的端口是2……这里我们也可以修改成我们想要的转发规则。
for (portid = 0; portid < nb_ports; portid++) {
/* skip ports that are not enabled */
if ((l2fwd_enabled_port_mask & (1 << portid)) == 0)
continue;
if (nb_ports_in_mask % 2) {
l2fwd_dst_ports[portid] = last_port;
l2fwd_dst_ports[last_port] = portid;
}
else
last_port = portid;
nb_ports_in_mask++;
//获取端口的名字、发送队列、接收队列等信息,主要就是填充每个端口的dev_info结构体
rte_eth_dev_info_get(portid, &dev_info);
}以及最后填充了一下每个端口的结构体里有关该端口的各种信息
4.为每个端口分配逻辑核
我们在命令行输入的参数有一个q,指的就是每个逻辑核最多可以用来处理几个端口,在这里绑定核的时候,就会执行这方面的检查。while后面的语句是寻找一个可同的逻辑核,在不超过最大核数量(128)的基础上,从0开始,看每个核是否超过了设置的每个核绑定几个端口数限制,如果没有当前循环的这个端口就可以绑定该核。
for (portid = 0; portid < nb_ports; portid++) {
...
while (rte_lcore_is_enabled(rx_lcore_id) == 0 ||
lcore_queue_conf[rx_lcore_id].n_rx_port ==
l2fwd_rx_queue_per_lcore) {
rx_lcore_id++;
if (rx_lcore_id >= RTE_MAX_LCORE)
rte_exit(EXIT_FAILURE, "Not enough cores\n");
}
//绑定该核
if (qconf != &lcore_queue_conf[rx_lcore_id])
/* Assigned a new logical core in the loop above. */
qconf = &lcore_queue_conf[rx_lcore_id];
...
}实际的绑定就是在这个核处理的端口列表中加上当前这个端口,然后该核绑定的端口数加1。
5.初始化每个端口
其中fflush函数是清除缓冲区的作用,会强迫未写入磁盘的内容立即写入。这部分比较简单,直接上源码。
for (portid = 0; portid < nb_ports; portid++) {
...
//清除读写缓冲区
fflush(stdout);
//配置端口,将一些配置写进设备dev的一些字段,以及检查设备支持什么类型的中断、支持的包大小
ret = rte_eth_dev_configure(portid, 1, 1, &port_conf);
...
//获取设备的MAC地址,写在后一个参数里
rte_eth_macaddr_get(portid,&l2fwd_ports_eth_addr[portid]);
/* init one RX queue */
//清除缓冲区
fflush(stdout);
//设置接收队列
ret = rte_eth_rx_queue_setup(portid, 0, nb_rxd,
rte_eth_dev_socket_id(portid),
NULL,
l2fwd_pktmbuf_pool);
if (ret < 0)
rte_exit(EXIT_FAILURE, "rte_eth_rx_queue_setup:err=%d, port=%u\n",
ret, (unsigned) portid);
/* init one TX queue on each port */
fflush(stdout);
//设置发送队列
ret = rte_eth_tx_queue_setup(portid, 0, nb_txd,
rte_eth_dev_socket_id(portid),
NULL);
if (ret < 0)
rte_exit(EXIT_FAILURE, "rte_eth_tx_queue_setup:err=%d, port=%u\n",
ret, (unsigned) portid);
/* Initialize TX buffers */
//每个端口分配接收缓冲区,根据numa架构的socket就近分配
tx_buffer[portid] = rte_zmalloc_socket("tx_buffer",
RTE_ETH_TX_BUFFER_SIZE(MAX_PKT_BURST), 0,
rte_eth_dev_socket_id(portid));
if (tx_buffer[portid] == NULL)
rte_exit(EXIT_FAILURE, "Cannot allocate buffer for tx on port %u\n",
(unsigned) portid);
//初始化接收缓冲区
rte_eth_tx_buffer_init(tx_buffer[portid], MAX_PKT_BURST);
//设置接收缓冲区的err_callback
ret = rte_eth_tx_buffer_set_err_callback(tx_buffer[portid],
rte_eth_tx_buffer_count_callback,
&port_statistics[portid].dropped);
if (ret < 0)
rte_exit(EXIT_FAILURE, "Cannot set error callback for "
"tx buffer on port %u\n", (unsigned) portid);
/* Start device */
//启用端口
ret = rte_eth_dev_start(portid);
if (ret < 0)
rte_exit(EXIT_FAILURE, "rte_eth_dev_start:err=%d, port=%u\n",
ret, (unsigned) portid);
printf("done: \n");
rte_eth_promiscuous_enable(portid);
//打印端口MAC地址
printf("Port %u, MAC address: %02X:%02X:%02X:%02X:%02X:%02X\n\n",
(unsigned) portid,
l2fwd_ports_eth_addr[portid].addr_bytes[0],
l2fwd_ports_eth_addr[portid].addr_bytes[1],
l2fwd_ports_eth_addr[portid].addr_bytes[2],
l2fwd_ports_eth_addr[portid].addr_bytes[3],
l2fwd_ports_eth_addr[portid].addr_bytes[4],
l2fwd_ports_eth_addr[portid].addr_bytes[5]);
/* initialize port stats */
//初始化端口数据,就是后面要打印的,接收、发送、drop的包数
memset(&port_statistics, 0, sizeof(port_statistics));
}6.任务分发
这里就是DPDK程序最熟悉的任务分发函数了,每个slave从线程启动后运行的函数是l2fwd_launch_one_lcore:
rte_eal_mp_remote_launch(l2fwd_launch_one_lcore, NULL, CALL_MASTER);
RTE_LCORE_FOREACH_SLAVE(lcore_id) {
if (rte_eal_wait_lcore(lcore_id) < 0) {
ret = -1;
break;
}
}而l2fwd_launch_one_lcore实际上运行的是l2fwd_main_loop,这就是上面说的从线程循环了
static int
l2fwd_launch_one_lcore(__attribute__((unused)) void *dummy)
{
l2fwd_main_loop();
return 0;
}7.从线程循环
这部分就直接附上注释的源码吧,注释有点调皮~
static void
l2fwd_main_loop(void)
{
...
//获取自己的lcore_id
lcore_id = rte_lcore_id();
qconf = &lcore_queue_conf[lcore_id];
//分配后多余的lcore,无事可做,orz
if (qconf->n_rx_port == 0) {
RTE_LOG(INFO, L2FWD, "lcore %u has nothing to do\n", lcore_id);
return;
}
//有事做的核,很开心的进入了主循环~
RTE_LOG(INFO, L2FWD, "entering main loop on lcore %u\n", lcore_id);
...
//直到发生了强制退出,在这里就是ctrl+c或者kill了这个进程
while (!force_quit) {
cur_tsc = rte_rdtsc();
/*
* TX burst queue drain
*/
//计算时间片
diff_tsc = cur_tsc - prev_tsc;
//过了100us,把发送buffer里的报文发出去
if (unlikely(diff_tsc > drain_tsc)) {
for (i = 0; i < qconf->n_rx_port; i++) {
portid = l2fwd_dst_ports[qconf->rx_port_list[i]];
buffer = tx_buffer[portid];
sent = rte_eth_tx_buffer_flush(portid, 0, buffer);
if (sent)
port_statistics[portid].tx += sent;
}
//到了时间片了打印各端口的数据
/* if timer is enabled */
if (timer_period > 0) {
/* advance the timer */
timer_tsc += diff_tsc;
/* if timer has reached its timeout */
if (unlikely(timer_tsc >= timer_period)) {
/* do this only on master core */
//打印让master主线程来做
if (lcore_id == rte_get_master_lcore()) {
print_stats();
/* reset the timer */
timer_tsc = 0;
}
}
}
prev_tsc = cur_tsc;
}
/*
* Read packet from RX queues
*/
//没有到发送时间片的话,读接收队列里的报文
for (i = 0; i < qconf->n_rx_port; i++) {
portid = qconf->rx_port_list[i];
nb_rx = rte_eth_rx_burst((uint8_t) portid, 0,
pkts_burst, MAX_PKT_BURST);
//计数,收到的报文数
port_statistics[portid].rx += nb_rx;
for (j = 0; j < nb_rx; j++) {
m = pkts_burst[j];
rte_prefetch0(rte_pktmbuf_mtod(m, void *));
//updating mac地址以及目的端口发送buffer满了的话,尝试发送
l2fwd_simple_forward(m, portid);
}
}
}
}值得注意的小操作
程序中强制退出,是自己写的一个信号量,包括两种操作,即在ctrl+c或者kill了这个进程的时候,会触发:
static void
signal_handler(int signum)
{
if (signum == SIGINT || signum == SIGTERM) {
printf("\n\nSignal %d received, preparing to exit...\n",
signum);
force_quit = true;
}
}
signal(SIGINT, signal_handler);
signal(SIGTERM, signal_handler);signal_handler函数第一个参数signum:指明了所要处理的信号类型,它可以取除了SIGKILL和SIGSTOP外的任何一种信号。
第二个参数handler:描述了与信号关联的动作,它可以取以下三种值:
1. SIG_IGN
这个符号表示忽略该信号。
2. SIG_DFL
这个符号表示恢复对信号的系统默认处理。不写此处理函数默认也是执行系统默认操作。
3. sighandler_t类型的函数指针
此函数必须在signal()被调用前申明,handler中为这个函数的名字。当接收到一个类型为sig的信号时,就执行handler 所指定的函数。(int)signum是传递给它的唯一参数。执行了signal()调用后,进程只要接收到类型为sig的信号,不管其正在执行程序的哪一部分,就立即执行func()函数。当func()函数执行结束后,控制权返回进程被中断的那一点继续执行。
在该函数中就是第三种,所以当我们退出是ctrl+c不是直接将进程杀死,而是会将force_quit置为true,让程序自然退出,这样程序就来得及完成最后退出之前的操作。
图引用:
[1].http://www.cnblogs.com/cenalulu/p/4358802.html