队列1-环形缓冲区
本篇为队列的第一篇文章,介绍基于数组结构的一个环形缓冲区队列。我觉得没有必要再从数组来写起,毕竟对于数组本身来说,我觉得是没有太多可说的,但是基于数组的数据结构就有的说了。
什么是环形缓冲区
- 环形缓冲区,顾名思义就是一个环状的存储数据的区域,其空间使用数组进行构造(链表也可以)。环形缓冲区特点是读和写可以是分开的,写入数据之后可以先不去读取,等到需要读取的时候再去读取,并且数据一经读取之后就做丢弃处理(当然也可以实现重复读取的效果,不过大多用作一次性读取),等于说是一次性的读取。
- 假设一个长度为256字节的数组,构建出一个环形缓冲区,当写操作进行到数组的第256项之后,再一次写入就会回到第0个进行写入;同样读操作是读取到数组的第256项时,再一次进行读取就会回到数组的第一项。是谓环形缓冲
可以看到,环形缓冲区是一种先进先出的队列类型结构,通常情况下会用于一个符合生产着消费者模型的场景。比如说视频帧数据的管理、消息队列的管理等等。
队列类型的数据结构还有链表形式,只不过对于环形缓冲区来说,使用数组更加的高效。本文就基于 Linux 内核里面的 kfifo 队列实现一个高效、自定义功能并且以面向对象模式组织的环形缓冲区模块,不是照抄,理会精髓,自己实现,然后加入一些扩展。
基本结构
一个环形缓冲区包括以下元素:
- 读指针、写指针。
- 数组类型的存储空间(有链表类型的,但是这里只说数组类型)。
- 缓冲区是否满标志、锁。
用图形化的描述就如下图所示:
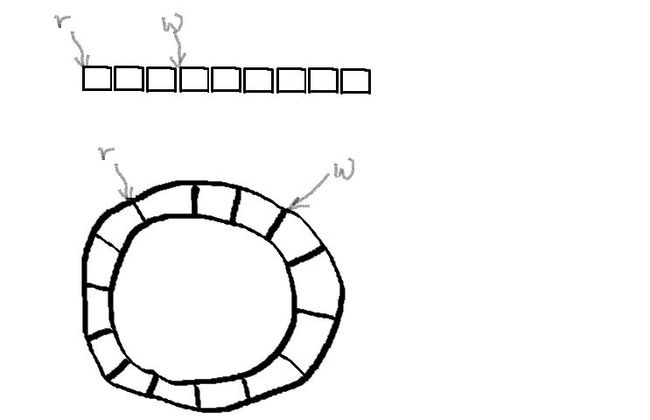
上面一个是它的直观存储方式,也就是一个数组类型的结构,其中 r 代表读指针,用于指示下一个应该读取的环形缓冲区元素。w 代表写指针,用于指示下一个该写入的位置。黑色的一列小方框就是用于存储环形缓冲区数据的存储空间。锁在单生产者、单消费者的情况下是不需要的,原因后面讲。其中 r,w 指针其实很容易看出来,它就是个数组的下标索引。
下面一个圆形的图就是形象化的环形缓冲区,其实把直线棍状的数组给它折叠起来了而已,看起来没头没尾的一个自交型贪吃蛇结构。这个图更接近环形缓冲区的本身的抽象化形象,在代码实现上其实就是把读写指针取一个模完成"环形化"。
这里要提一下的是关于缓冲区的满与空的标志,首先说结论:
- 当
r与w相等的时候,就说明这个环形缓冲区队列空了。 - 当
r== (w+ 1)%size的时候就说明这个环形缓冲区满了。
上面两个断言似乎有冲突的地方,比如写指针绕过一圈子之后如果 w 与 r 相等也能够说这个环形缓冲区是满的,并且上面第二条看起来会空余一个元素没有用到啊。第一个我们在代码实现的时候就会在出队列的时候才会判断这个缓冲区是否为空,第二个为了方便起见,环形缓冲区始终会空出一个元素的位置来明确的区分队列空与队列满的标记。所以第一个冲突的情况就不会发生。
如果希望能够充分利用存储空间的话就需要一个额外的变量来存储目前缓冲区里面已经存放好的元素有多少个,然后与环形缓冲区创建之初指定的元素总数进行比较,这样就可以充分利用所有缓冲区里面的存储空间,因为大多数时候环形缓冲区的元素都是大于一个字节的。
代码实现
保留之前的习惯,在文章里面会尽可能少的贴代码,我觉得贴的代码过多会导致整篇文章很难看,并且使得文章显得冗长并且有用的部分还不多,代码我贴到 github 上面在文末给出链接。
首先我这里的代码实现提出了几个要求:
- 能够自定义环形缓冲区的元素个数、自定义每个元素的字节数。
- 能够支持多线程安全的方式进行读取或者写入。
- 模块化,使用者只需要初始化一个环形缓冲区对象,然后可以很方便地使用它。
- 可以很方便、快速地初始化多个环形缓冲区实例。
这里我会先规定一个环形缓冲区的抽象化结构体,在需要使用的时候就实例化一个环形缓冲区结构体,我把它的结构写成下面这种:
struct ring_buffer {
int (*rb_in)(struct ring_buffer *rb_hd,
void *buf_in, uint32_t elem_num);
int (*rb_out)(struct ring_buffer *rb_hd,
void *buf_out, uint32_t elem_num);
void (*rb_reset)(struct ring_buffer *rb_hd);
uint32_t (*rb_g_bufsize)(struct ring_buffer *rb_hd);
uint32_t (*rb_g_validnum)(struct ring_buffer *rb_hd);
uint32_t (*rb_g_elemsize)(struct ring_buffer *rb_hd);
void *private;
};
里面的前面大部分项都不去解释了,很容易可以知道它们每个值的意义。最后一个 private 需要特别解释下,这个是用于模块内部的自用结构的索引。仔细看一下上面的结构体里面缺少了哪些元素?
可以看到少了环形缓冲区的总大小、元素大小、锁、读指针、写指针等等。而这些东西对于使用者来讲是不需要用到的数据,不需要关心,而这部分数据我就放在另外一个内部的结构体里面了,它的定义如下所示:
struct ring_buffer_entity {
pthread_mutex_t rb_lock;
uint32_t rb_in;
uint32_t rb_out;
uint32_t elem_size;
uint32_t elem_cnt;
bool rb_full;
unsigned char *rb_buf;
struct ring_buffer_attr rb_attr;
struct ring_buffer rb_handle;
};
在使用的时候我通常会做以下的转换:struct ring_buffer_entity *entity = (struct ring_buffer_entity *)ring_buffer->private;。这样就达到了封装的目的,在 C++ 里面封装是不需要用得到那个 private 的,但是在 C 里面就不得不用这种方式实现封装的目的。
扯多了,回到代码中与环形缓冲区相关的地方。
临界判断
在上面的第二个结构体里面,读写指针都是32位的无符号整形,这个是有特殊作用的,因为这种情况下可以直接使用 rb_in - rb_out 来表示目前环形缓冲区里面有效的数据个数,不用取模,在写入之后 rb_in 尽管加上写入元素的个数即可,也不用在写入结束的时候把 rb_in 取模。
想象一下无符号整形数的特点,就是在溢出的时候会恢复到0值,也就是 0xFFFFFFFF+1 会等于 0,在没有溢出的情况下 rb_in - rb_out 用于表示目前已写入的元素个数很好理解,那么一旦当 rb_in 溢出了,rb_in - rb_out 还是可以满足计算要求。
用一个实例套入计算即可,比如说现在环形缓冲区里面有三个元素,正常情况下 rb_in 与 rb_out 的关系是类似 3与0,116与113 的关系,直接减去没有问题,但是如果这个时候 rb_in 已经超了,比如此时 rb_out == 0xFFFFFFFE, 呢么 rb_in 就是 0xFFFFFFFE+3,这个值在无符号的时候是2,因为溢出了,那么无符号的 2-0xFFFFFFFE 在内部计算的时候就是一个很大的负数,而这个负数重新转化为无符号类型就是 3.
目前代码里面没有只用了一个已写入元素的个数计数和整个环形缓冲区的可存储元素总数来进行比较,没有使用 r,w 指针本身来进行判断,这样会充分利用环形缓冲区里面的每一个存储空间。
读写的实现
写入的核心代码有下面几个步骤:
uint32_t cp_cnt = min(要写入的元素个数, 剩余的元素个数);
uint32_t cp_step1 = min(cp_cnt, 数组右侧剩余的可存储元素空间个数);
memcpy(写指针在的位置, 输入buffer地址, cp_step1乘以元素的大小);
memcpy(数组起始地址, 输入buffer剩下的数据起始地址, (cp_cnt-cp_step1)乘以元素大小);
rb_ent->rb_in += cp_cnt; /* 写指针后移 */
读取的核心代码有下面几个步骤:
uint32_t cp_cnt = min(要读出的元素个数, 有效元素个数);
uint32_t cp_step1 = min(cp_cnt, 数组右侧剩余的有效元素个数);
if (NULL == buf_out)
goto copy_end;
memcpy(输出buffer地址, 读指针在的位置, cp_step1乘以元素大小);
memcpy(输出buffer剩余空间起始地址, 数组零下标起始地址, (cp_cnt-cp_step1)乘以元素大小);
copy_end:
rb_ent->rb_out += cp_cnt; /* 读指针后移 */
这里读写指针不必每次后移的时候都取模,只用在索引数组下标的时候对其取模即可,原因在上一条里面描述过了。
如果在单生产者单消费者的情况下,这个读写的过程是不用加锁的,唯一需要担心的也就是指令重排了,但是这种情况发生的概率也是极小的,一般情况下在嵌入式的场景里面基本是不用担心的。
那么如果在写的时候被打断,看下会发生什么情况,由于写过程中用到的会时刻变化的共享变量也就是 rb_out 了,如果在取到了 rb_out 的值之后它的值被别人改变了,也就是环形缓冲区中的存储空间又被释放出了一部分,此时顶多会导致本来可以写入的部分由于缓冲区被判定为满而写不进去了,稍等片刻再写或者干脆丢掉也不影响,整体上不会导致读写错乱。
而读的过程也是类似,顶多是有些已经写入的东西被误判为还没有写入,那下次再去读取就好,无非是多耗费了一点时间,况且加锁的话这部分时间也是无法省去的。这也是代码里面为什么要在数据拷贝完成之后在改变 rb_in 与 rb_out 的一个考虑,因为如果在拷贝之前改变它的值就有可能读出来非法的值或者写入值把原来的值给覆盖了。
所以单生产者但消费者的情况下,基本上是不用考虑锁的问题的。从另一种角度来讲,这种队列模式其实不太可能用于多个消费者的情况,原因是因为通常情况下消费者是不能够错过队列中的任何一个消息的,或者说必须获取连续的队列内容。
想象一下多消费者的实现,我这里有一种思路:提前确定好消费者的数量,然后为每一个队列项添加一个引用计数,一旦有一个消费者取用就将引用计数减一,到0才真正从队列里面删掉这个数据。这样会有几个问题:
- 一旦有任何一个消费者阻塞,其它的都会阻塞。
- 必须确定每一个元素的引用计数,需要添加一个成员,这样会导致一次性的多个元素拷贝变得很困难,因为可能有的读得多,有的读的少,这样会导致引用计数无法保持一致性的减少。
所以,多个消费者一般是不会使用同一个队列对象的,多个生产者却是可能的,因为生产元素有很多时候无需满足十分有序的输入,比如命令分发、消息分发队列,这个时候可以只在生产者那一端也就是队列写入操作那里加上锁,读出就不需要加锁了。
代码设计
在代码里面我添加了一些属性,比如线程安全属性,与普通情况不同的是它加了一把锁,但是表现在使用者那里就对应的是同一个回调函数成员,只不过其指向的函数实现不一样而已。
代码采用了面向对象的方式进行编写,可以非常方便的初始化一个环形缓冲区,并且使用实例化对象结构体内部的成员就可以完成整个的环形缓冲区的操作,十分方便。
代码参考了内核里面的 kfifo 的实现,力求尽量地精简,但是为了使用的便捷,加入了不少的自定义内容,并且加入了一些可能会用得到的特性,比如线程安全属性等等。
环形缓冲区内部不区分你想存入的数据结构类型,它只管按照当初约定好的元素长度以及你传递给它的读写 buffer 地址来进行指定长度的拷贝或者读取,数据类型的一致性要靠使用者自己来保证。
利用 void* 指针的特性来屏蔽一些用户不需要的细节,比如上面说到的两个结构体,一个作为模块内部使用,一个作为用户与模块内部交互的接口使用。
End
这是队列的第一篇,主要介绍下环形缓冲区这个队列,下一篇文章会介绍一下链表类型的队列,会先写一下链表队列的实现,然后再结合一个实际的链表类型的应用进行辅助,风格与这个类似,力求使用方便,代码清晰易懂。
需要注意的是代码里面肯定会不可避免的有一些 bug,要实现一个无 bug 的小模块显然比我想象当中的更困难,这一点在工作当中已经无数次验证过,所以当你使用我的代码遇到一些操蛋的问题,那一定不是用法的问题,我觉得大概率是我的代码 bug。那么为什么会有 bug 呢,主要还是我没有精力与动力去搞大规模测试,代码精确 review 这些,领会精髓吧,如果后续有必要,比如有人提了 issue 或者啥的我可能才会去修一修,不然凭我自己的主观能动性怕是比较玄学了。
这篇其实是比较浅显易懂的,不过不要怪我水,因为写一篇技术类的文章太难了,要有代码要有文章,要有调试要尽量少错误,由浅及深,后续估计进度会越来越慢的(逃。
Github 代码链接:链接
