爬取中国大学排名
放假在家闲来没事,学习python爬虫也一段时间了,于是将自己以前写的关于爬虫的代码写成博客,一起交流。
——前记
本节博客主要是简答地爬取中国大学排名,利用两种不同的解析库pyquery和beautifulsoup进行解析。
首先,简单地介绍下这两个库的安装,我使用的是anaconda直接运行cmd,在命令行输入pip beautifulsoup4 和pip install pyquery
这两个解析库的详细使用,我就不介绍了,给两个链接beautifulsoup库使用详解https://blog.csdn.net/love666666shen/article/details/77512353,pyquery库的使用http://www.mamicode.com/info-detail-2257042.html,如果有问题,可以留言,我们可以一起学习交流。
下面我们就正式对中国大学排名进行爬取,首先我们进入url='http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2017.html'网页中,我们看到下图的形式的一个表格,我们将要做的是提取出学校排名 名称 省市 高考成绩得分。
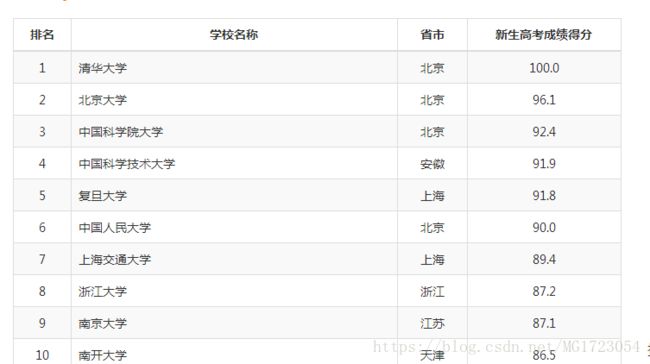
最简单的形式是在源代码中查看是否出现这些数据(有些数据不一定存在于源代码中,可能存在JavaScript渲染,异步加载等情况,这些后面再说),如图,打开源代码,我们可以在源代码中找到我们所需要的数据,于是我们可以利用requests库请求网址,得到源代码数据


请求数据部分代码如下:
需要requests请求库,所以要导入requests库。import requests
header={'User-Agent':'Mozilla/5.0'} #请求头,该网址反爬效果不行,可以不需要加的
url='http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html'
r=requests.get(url,headers=header)
r.encoding=r.apparent_encoding #改变编码方式,两种方法,第一种,利用该方式,使得编码成为显示编码,让程序自己根据源#代码猜测代码编码方式,第二种,自己在源代码(一般在开头,比如本文的网站的编码方式就是![]() ,所以#可以将r.encoding='utf-8'效果一样)
,所以#可以将r.encoding='utf-8'效果一样)
print(r.text)
这样,源代码就显示在屏幕上。
第二步,解析源代码,首先我们利用beautifulsoup解析库解析
注意虽然我们在安装的时候是pip install beautifulsoup4但是在导入这个解析库是用from bs4 import BeautifulSoup 库
解析库的代码如下:
university=[]
soup=BeautifulSoup(r.text,'html.parser') #初始化
for data in soup.find_all('tr','alt') :
####![]() 利用beautidulsoup库的find_all方法寻找所有的符合的数据,从这个截图中,我们可以看到,每行的数据都在tr,class="alt"节点内
利用beautidulsoup库的find_all方法寻找所有的符合的数据,从这个截图中,我们可以看到,每行的数据都在tr,class="alt"节点内
infor=data('td')
university.append([infor[0].string,infor[1].string,infor[2].string,infor[3].string]) #利用.string方法打印出td节点内所有文本。
最后我们利用pandas库对数据进行输入格式化,代码如下:
import pandas as pd
university=pd.DataFrame(university)
print(university)
最后我们得到的部分数据结果如下:

利用beautifulsoup解析的源代码如下:
"""
Created on Sun Aug 12 09:17:56 2018
@author:NJUer
"""
import requests
from bs4 import BeautifulSoup
import pandas as pd
university=[]
url='http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html'
r=requests.get(url)
r.encoding=r.apparent_encoding
#print(r.text)
soup=BeautifulSoup(r.text,'html.parser')
#print(soup.prettify())
#data=soup.find_all('tr','alt')
for data in soup.find_all('tr','alt') :
infor=data('td')
university.append([infor[0].string,infor[1].string,infor[2].string,infor[3].string])
university=pd.DataFrame(university)
print(university)
同样的,我们可以利用pyquery库进行解析,前面的请求库requests与前面相同,在解析模块我们利用pyquery进行解析,首先导入pyquery库
from pyquery import PyQuery as pq
doc=pq(r.text) #初始化
items=doc('tr.alt') #与CSS类似,寻找tr class=alt属性的所有节点,注意,一、如果不是class=alt,则不能省略class用点代替,具体的在前面推荐的那个博客里面有,二、不要在中间随意加空格!!即使源代码中有的有空格,在使用pyquery时候也要考虑一下,因为空格在pyquery中表示某节点之内的某个属性,这个坑我踩过。
for item in items.items():
data=item.text().split('\n') #单个地提出节点
universities.append(data)
最后我们利用format进行格式化打印输出
for university in universities:
print("{0:^5}{1:{4}^15}{2:{4}^5}{3:^25}".format(university[0],university[1],university[2],university[3],chr(12288)))###由于中间含有中文,所以在打印输出的时候要特别注意:中文与西文的编码问题,于是在要显示中文的地方格式化输出的时候使用中文空格作为填充。chr(12288)中文空格的Unicode编码。.format是格式化输出函数。对于漂亮输出具有很强的作用
最后部分输出结果如下:
977 江汉大学文理学院 湖北 11.7
977 山东英才学院 山东 11.7
977 长安大学兴华学院 陕西 11.7
977 重庆大学城市科技学院 重庆 11.7
981 兰州财经大学长青学院 甘肃 11.6
981 山东财经大学燕山学院 山东 11.6
981 太原理工大学现代科技学院 山西 11.6
981 铜仁学院 贵州 11.6
981 重庆邮电大学移通学院 重庆 11.6
986 吉林动画学院 吉林 11.5
987 上海师范大学天华学院 上海 11.4
988 嘉兴学院南湖学院 浙江 11.3
989 六盘水师范学院 贵州 11.2
990 江西农业大学南昌商学院 江西 11.1
990 南昌理工学院 江西 11.1
990 西安外事学院 陕西 11.1
993 武汉工程大学邮电与信息工程学院 湖北 11.0
994 兰州交通大学博文学院 甘肃 10.9
995 赣南师范大学科技学院 江西 10.8
995 天津理工大学中环信息学院 天津 10.8
995 长春科技学院 吉林 10.8
998 湖南理工学院南湖学院 湖南 10.7
998 厦门工学院 福建 10.7
998 西京学院 陕西 10.7
利用pyquery解析的源代码如下:
"""
Created on Sun Aug 12 09:17:56 2018
@author:NJUer
"""
universities=[]
from pyquery import PyQuery as pq
import requests
url='http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html'
r=requests.get(url)
r.encoding=r.apparent_encoding
#print(r.text)
doc=pq(r.text)
items=doc('tr.alt')
for item in items.items():
data=item.text().split('\n')
universities.append(data)
for university in universities:
print("{0:^5}{1:{4}^15}{2:{4}^5}{3:^25}".format(university[0],university[1],university[2],university[3],chr(12288)))
——————————原创不易 ,如需转载,请注明出处,提及作者,谢谢!