python 爬虫破解有道词典
废话不多说,直接来硬货!!!!!!
有道的官网:url=“http://fanyi.youdao.com/”
下面开始了,当你输入需要翻译的字时,如下:

点开“检查”选项:
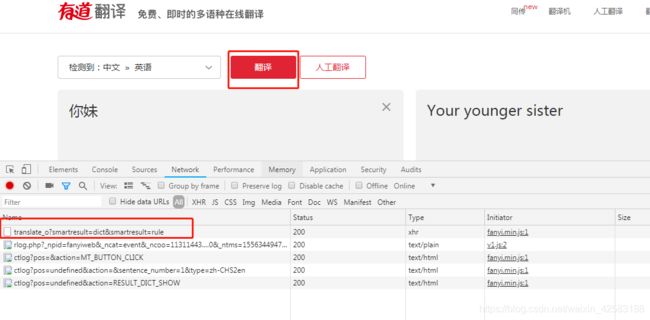
发现有道词典是post请求:需要带参数发送:

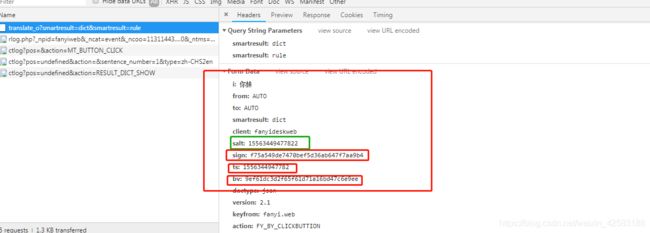
到这里发现,里面有参数js加密;我擦这哪里来的啊?
分析网页源代码发现有个fanyi.min.js文件含有关键字sign、salt等

ts:是个时间戳,类型是字符串
salt:是str( ts ) + str(随机数(0-9)之间的一个数),类型是字符串
bv:是请求头的哈希值
sign:是 (”fanyideskweb" + 翻译的语句 + salt + "@6f#X3=cCuncYssPsuRUE ”)的哈希值
其他post参数基本上固定的值
代码如下:
import requests
import time
import random
import hashlib
import json
kw = input("请输入你需要翻译的语句:")
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
"Content-Length": "255",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie":"[email protected]; OUTFOX_SEARCH_USER_ID_NCOO=1131144345.1085367; _ntes_nnid=ead037be70f0bb3757d4ad8646892644,1547025272545; JSESSIONID=aaa5rl0TEfn7yfpOIRCPw;_rl__test__cookies="+str(int(time.time()*1000)),
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
timestamp = str(int(time.time()*1000)) #时间戳
timestamp1 = timestamp+str(random.choice(range(0,10)))#时间戳与随机数
def hash5(str):#哈希函数
md5=hashlib.md5()
md5.update(str.encode("utf8"))#这里是坑,需要编码,问我为什么,我也不懂
data = md5.hexdigest()
return data
def get_request_data():
data = {
"i":kw,
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"salt":timestamp1,#时间戳
"sign":hash5("fanyideskweb" + kw + timestamp1 + "@6f#X3=cCuncYssPsuRUE"),#哈希值
"ts":timestamp,#时间戳与随机数(0-9)
"bv":hash5(headers["User-Agent"].replace("Mozilla/","")),#请求头的去掉“Mozilla/”后的哈希
"doctype":"json",
"version":2.1,
"keyfrom":"fanyi.web",
"action":"FY_BY_CLICKBUTTION"
}
return data
def get_info():
data = get_request_data()
response = requests.post(url=url,headers=headers,data=data).content.decode()
tran_data = json.loads(response)
trans1 = tran_data["translateResult"][0][0]['tgt']
# print(type)
if "smartResult" in tran_data:
trans2 = tran_data["smartResult"]['entries'][1:]
print("字面意思:"+trans1)
print("其他意思:"+str(trans2).replace(r"\r\n",""))
else:
print("字面意思:"+trans1)
if __name__ == "__main__":
get_info()
调用后输入:project

到这里,麻麻再也不怕我翻译费劲了!!!!