数据库提升知识点汇总
文章目录
- 数据库
- 1. 数据库的设计范式
- E-R模型
- 范式
- 2. 事务
- 3. 为什么需要锁,锁的分类,锁粒度
- 锁
- 锁的分类
- 锁粒度
- 4. 乐观锁,悲观锁的概念及实现方式
- 5. 分页如何实现(`Oracle`,`MySql`)
- mysql
- oracle
- 6. Mysql引擎
- InnoDB存储引擎
- MyISAM存储引擎
- MEMORY存储引擎
- MERGE存储引擎
- 7. 内连接,左连接,右连接作用及区别
- 8. `Statement`和`PreparedStatement`之间的区别
- Statement: 执行sql的对象
- PreparedStatement: 执行sql的对象
- 9. 什么是数据库连接池
- 概念:
- 好处:
- 实现
- 10. 数据库的分区分表
- 1. 分库分表
- 2. 数据库分区
- mysql的优化
- 11. MYSQL语句优化
- 思路
- 1. 慢查询日志
- 2. explain的使用
- explain的作用
- 重点
- 3. 优化SQL
- 索引失效的几种情况
- 12. 分片
- mycat
- 1. 什么是分片
- 分片相关的概念
- mycat分片规则
- 13. 索引
- 14. 索引分类
- 1. 普通索引
- 2. 唯一索引
- 3. 主键索引
- 4. 组合索引
- 14. mysql的SQL语法技巧
- 1. null转0
- 2. distinct去重
数据库
一款用于存储的文件系统
组成部分: 文件系统 + 磁盘
一次io消耗的时间: 寻道+旋转
1. 数据库的设计范式
E-R模型
- 当前物理的数据库都是按照E-R模型进行设计的
- E表示entry,实体
- R表示relationship,关系
- 一个实体转换为数据库中的一个表
- 关系描述两个实体之间的对应规则,包括
- 一对一
- 一对多
- 多对多
- 关系转换为数据库表中的一个列 *在关系型数据库中一行就是一个对象
范式
经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式
- 第一范式(1NF):列不可拆分
- 第二范式(2NF):唯一标识
- 第三范式(3NF):引用主键
说明:后一个范式,都是在前一个范式的基础上建立的
2. 事务
- 事务的基本介绍
- 概念:
- 如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败
- 操作:
- 开启事务 start transaction
- 回滚 rollback
- 提交 commit
- MySQL数据库中事务默认自动提交
- 事务提交的两种方式
- 自动提交
- mysql就是自动提交的
- 一条DML(增删改)语句会自动提交一次事务
- 手动提交
- Oracle数据库默认手动提交事务
- 需要先开启事务,再提交
- 自动提交
- 修改事务的默认提交方式
- 查看事务的默认提交方式:
select @@autocommit; --1代表自动提交 0代表手动提交 - 修改 set @@autocommit=0
- 查看事务的默认提交方式:
- 事务提交的两种方式
- 概念:
- 事务的四大特征
- 原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败
- 持久性:当事务提交或回滚后,数据库会持久化的保存数据
- 隔离性:多个事务之间,相互独立
- 一致性:事务操作前后,总量不变
- 事务的隔离级别(了解)
- 概念:多个事务之间隔离的,相互独立,但是如果多个事务操作同一批数据,会引发一些问题,设置不同的隔离级别就可以解决这些问题
- 存在问题:
- 脏读: 一个事务,读取到另一个事务中没有提交的数据。
- 不可重复读: 在同一事务中,两次读取到的数据不一样
- 幻读:一个事务操作DML数据表中所有记录,另一个事务添加了一条记录,则第一个事务查询不到自己的修改
- 隔离级别
- read uncommitted: 读未提交
- 产生的问题:脏读不可重复读、幻读
- read committed 读已提交
- 产生的问题:不可重复读、幻读
- repeatable read 可重复读
- 产生的问题:幻读
- serializable: 串行化
- read uncommitted: 读未提交
在企业开发中,框架里面配置事务来解决相关的数据库问题,spring框架在项目中配置事务。
3. 为什么需要锁,锁的分类,锁粒度
锁
数据库是一个多用户使用的共享资源。当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库的一致性。
加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。
锁的分类
读锁/共享锁:只要是读的线程都能获得这把锁–> 读时不会触发安全问题 lock in share mode
写锁/排他锁:一个人持有锁,其他人都不能拿到锁。for update
锁粒度
一种提高共享资源并发性的方式就是让锁对象更有选择性。尽量只锁定需要修改的部分数据,而不是所有的资源。更理想的方式是。只对修改的数据片进行精确的锁定。任何时候,在给定的资源上,锁定的数据量越少,则系统的并发程度越高,只要相互之间不发生冲突即可。
但是加锁也需要消耗资源,锁的各种操作,包括获得锁、检查锁是否已经解除、释放锁等,都会增加系统的开销。如果系统花费大量的时间来管理锁,而不是存取数据,那么系统的性能可能会因此受到影响。
所谓的锁策略,就是在锁的开销和数据的安全性之间寻求平衡。
- 表锁
表锁是Mysql中最基本的锁策略,并且时开销最小的策略。表锁会锁定整张表。对表进行写操作(插入、删除、更新等),需要先获得写锁,这会阻塞其他用户对该表的所有读写操作。读锁之间是不相互阻塞的。
- 行级锁
行级锁可以最大程度地支持并发处理(同时也带来了最大的锁开销)。
行级锁只在存储引擎层实现,而Mysql服务器层没有实现。
4. 乐观锁,悲观锁的概念及实现方式
乐观锁:制定了一个版本号,每次操作这个数据,对应版本号+1,提交数据时,要比安全的版本号大一,否则提交失败。
悲观锁:就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。
- 读锁/共享锁:只要是读的线程都能获得这把锁–> 读时不会触发安全问题
lock in share mode - 写锁/排他锁:一个人持有锁,其他人都不能拿到锁。
for update
5. 分页如何实现(Oracle,MySql)
mysql
- 语法: limit 开始的索引,每页查询的条数;
- 公式: 开始的索引 = (当前的页码-1) * 每页显示的条数;
- limit 是mysql的方言
oracle
rownum行号:当我们做select操作的时候,每查询出一行记录,就会在该行上加上一个行号,行号从1开始,依次递增,不能跳着走。
排序操作会影响rownum的顺序,如果涉及到排序,还是要用rownum的话,可以再次嵌套查询
select rownum,t.* from(
select rownum,e.* from emp e order by e.sal desc)t;
-- emp表工资倒序排列后,每页五条记录,查询第二页
-- rownum不能写上大于一个正数
select * from(
select rownum rn,tt.* from(
select * from emp order by sal desc
)tt where rownum<11
)where rn>5;
6. Mysql引擎
InnoDB存储引擎
该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。
InnoDB存储引擎的特点:支持自动增长列,支持外键约束
MyISAM存储引擎
不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
MEMORY存储引擎
使用存在于内存中的内容来创建表,一旦服务关闭,表中的数据就会丢失掉。
MERGE存储引擎
是一组MyISAM表的组合,这些MyISAM表必须结构完全相同。对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
7. 内连接,左连接,右连接作用及区别
多表查询
-
内连接查询 只包括交集
-
隐式内连接
SELECT t1.`name`, -- 员工表的姓名 t1.`gender`, -- 员工表的性别 t2.`name` -- 部门表的名称 FROM emp t1,dept t2 WHERE t1.`dept_id`=t2.`id`;
-
显式内连接
select 字段列表 from 表名1 inner join 表名2 on 条件 -
内连接查询:
- 从哪些表中查询数据
- 条件是什么
- 查询哪些字段
-
-
外链接查询
-
左外连接 一般用左外,包括左外和交集
select 字段列表 from 表1 left join 表2 on 条件左外连接查询的是左表所有数据以及其交集部分
-
右外连接
select 字段列表 from 表1 right join 表2 on 条件
-
-
子查询
-
概念:查询中嵌套查询,称嵌套查询为子查询
-- 查询工资最高的员工信息 SELECT MAX(salary) FROM emp; -- 查询员工信息,工资等于9000 SELECT * FROM emp WHERE emp.`salary`=9000; -- 合并为一条 SELECT * FROM emp WHERE emp.`salary`=(SELECT MAX(salary) FROM emp); -
子查询的不同情况
-
子查询的结果是单行单列的值
-
子查询可以作为条件,放在where后边,使用运算符去判断
-- 查询员工工资小于平均工资的人 SELECT * FROM emp WHERE emp.`salary`< (SELECT AVG(salary) FROM emp);
-
-
子查询的结果是多行单列的数组
- 子查询可以作为条件,放在where后边,使用运算符in来判断
-- 查询所有财务部和市场部员工的信息 SELECT id FROM dept WHERE NAME = '财务部' OR NAME='市场部'; SELECT * FROM emp WHERE dept_id = 3 OR dept_id=2; -- 子查询 SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME = '财务部' OR NAME='市场部');
-
子查询的结果是多行多列的子表
- 子查询可以作为一张虚拟表参与查询,放在from后边
-- 查询员工的入职日期是2011-11-11日之后的员工信息和部门信息 -- 子查询 SELECT * FROM dept t1,(SELECT * FROM emp WHERE emp.`join_date` >'2011-11-11') t2 WHERE t1.id = t2.dept_id; -- 普通内连接 SELECT * FROM emp t1,dept t2 WHERE t1.`dept_id`=t2.`id` AND t1.`join_date`>'2011-11-11';
-
-
8. Statement和PreparedStatement之间的区别
Statement: 执行sql的对象
-
执行sql
-
boolean execute(String sql): 可以执行任意的sql(了解) -
int executeUpdate(String sql): 执行DML(insert\update\delete) 语句、DDL语句返回值:影响的行数,可以通过它判断DML是否执行成功,返回值>0则执行成功,反之,失败
-
ResultSet executeQuery(String sql): 执行DQL(select)语句
-
PreparedStatement: 执行sql的对象
-
SQL注入问题:在拼接sql时,有一些sql的特殊关键字参与字符串的拼接,会造成安全性问题
- 输入用户随便,输入密码:
a' or 'a' = 'a
- 输入用户随便,输入密码:
-
解决sql注入问题: 使用
PreparedStatement对象来解决 -
预编译的SQL:参数使用
?作为占位符 -
步骤:
- 导入jar包
- 注册驱动
- 获取数据库连接对象
- 定义sql
- 注意:sql的参数使用?作为占位符(列字段对应的数据),如
select * from user where username = ? and password = ?;
- 注意:sql的参数使用?作为占位符(列字段对应的数据),如
- 获取执行sql语句的对象
PreparedStatement Connection.prepareStatement(String sql) - 给?赋值
- 方法: setXxx(参数1,参数2)
- 参数1:
?的位置编号,从1开始 - 参数2:
?的值
- 参数1:
- 方法: setXxx(参数1,参数2)
- 执行sql,接受返回结果,不需要传递sql语句
- 处理结果
- 释放资源
注意:
后期都会使用PreparedStatement来完成增删改查的所有操作
- 可以防止SQL注入
- 效率更高
-
预编译:preparedStatement对象,会提前(预编译)校验SQL语句是否正确,接下来执行SQL语句时,传递的参数就是
?对应的数据,而不会把传递的参数作为SQL语句的一部分 -
预编译对象,会对特殊的关键词进行转义,比如
or,把它作为password的参数;而statement对象,没有预编译功能,也不会对参数的关键词进行转义,传递的数据是什么,就是什么,如果参数有关键词,会作为SQL语句的一部分
9. 什么是数据库连接池
概念:
其实就是一个容器(集合),存放数据库连接的容器。当系统初始化好后,容器被创建,容器会申请有一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完,会将连接对象归还给容器。
好处:
- 节约资源
- 用户访问高效
实现
- 标准接口: DataSource javax.sql包下的
- 方法:
- 获取连接:getConnection()
- 归还连接:Connection.close() 如果连接对象connection是从连接池中获得的,那么调用Connection.close()方法,则不再关闭连接池,而是归还连接
- 技术实现
- C3P0: 数据库连接池技术
- Druid: 数据库连接池实现技术,由阿里巴巴提供
- 方法:
10. 数据库的分区分表
1. 分库分表
优点:
将大表分割为多个小表,大幅度查询的行数,从而提高查询效率
相比于分区,对于单个小表可建立索引,进一步提高查询
缺点:
- 数据量大幅增长的话,分表表数不够,需要重新分表,移数据略显麻烦
- 将数据导入到多个表中,对于查询该表所有数据的统计不大好统计
- 数据表建的太多,看起来凌乱,且导入历史数据麻烦
- 增加列不方便
- 浪费存储空间
2. 数据库分区
优点:
- 和数据库分库分表的思想接近,属于屋里存储层面的分库分表,数据量过大时,删除索引查询速度可显著提高
- 数量若增大,查询速度减慢时,可直接通过语句增加分区个数,提高查询速度。
缺点:
- 单表数据量过大时,对于分区建立索引会降低查询速度
- 数据库迁移数据困难
- 多表连接查询效率明显降低
- 数据插入较慢,不适合插入频繁操作
- 浪费存储空间
mysql的优化
对mysql优化时一个综合性的技术,主要包括
1: 表的设计合理化(符合3NF)
2: 添加适当索引(index) [四种: 普通索引、主键索引、唯一索引unique、全文索引]
3: 分表技术(水平分割、垂直分割)
4: 读写[写: update/delete/add]分离
5: 存储过程 [模块化编程,可以提高速度]
6: 对mysql配置优化 [配置最大并发数my.ini, 调整缓存大小 ]
7: mysql服务器硬件升级
8: 定时的去清除不需要的数据,定时进行碎片整理(MyISAM)
11. MYSQL语句优化
思路
- 找到慢的SQL(慢查询日志)
- 分析SQL(explain)
- 优化SQL
1. 慢查询日志
开启慢查询日志
在my.ini中设置如下开启慢查询日志
slow-query-log=1(开启慢查询日志)
slow_query_log_file="mysql-slow.log"(慢查询日志的路径)
long_query_time=10(大于多少的才进行记录,单位是毫秒)
筛选慢查询日志找到需要优化的SQL
使用mysql提供的mysqldumpslow工具
mysqldumpslow -s t -t 10 /database/mysql/mysql06_slow.log
(获取按照耗时排序的前10条sql语句)
2. explain的使用
explain select * from course_base cb ,category c where cb.st = c.id ;
explain的作用
- 查看表的加载顺序
- 查看SQL的查询类型
- 哪些索引可能被使用
- 哪些索引被实际使用了
- 表之间的引用关系
- 一个表中有多少行被优化器查询
- 其他额外的辅助信息
重点
- type:查询等级,从最好到最差依次是:system > const > eq_ref > ref > range > index > all
一般需要达到ref和range, 之前的需要唯一索引。
ref:非唯一性索引扫描,返回匹配某个单独值的所有行
range:只检索给定范围的行,不用扫描全部索引
- rows:估算需要读取的行数,优化目标:越少越好
- extra里面group by没有使用索引时会显示using filesort和using temporary着两个关键字。
3. 优化SQL
目的就是提高explain中的type的等级,减少rows扫描行数,优化extra信息中提及的信息。
主要从以下几点入手:
- 对于type等级低且rows大的表加索引
- 检查是否有SQL写法不当导致索引失效
- 优化SQL写法减少查询次数
- 尽量指明返回的列,避免
select *
索引失效的几种情况
- 最佳左前缀法则:如果索引多列,查询要从最左前列开始且不跳过索引中的列,因为底层的B+树会从最左的索引开始找,如果顺序反了会导致索引失效从而全表查询(组合索引会出现这种情况)
- like以
%开头的话mysql索引会失效,%放后边或者不写就不会失效 - 使用不等于的时候无法使用索引
- 字符串不加单引号会导致索引失效
12. 分片
mycat
一个新颖的数据库中间件产品支持mysql集群,或者mariadb cluster,提供高可用性数据分片集群。你可以像使用mysql一样使用mycat。对于开发人员来说根本感觉不到mycat的存在。
1. 什么是分片
通过某种特定的条件,将存放在同一个数据库中的数据分散存放在多个数据库(主机),达到分散单台设备负载的效果。
数据的切分(Sharding)根据切分规则的类型,分为两种切分模式
- 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,称为数据的垂直切分

- 另外一种根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多态数据库(主机)上,称为数据的水平切分
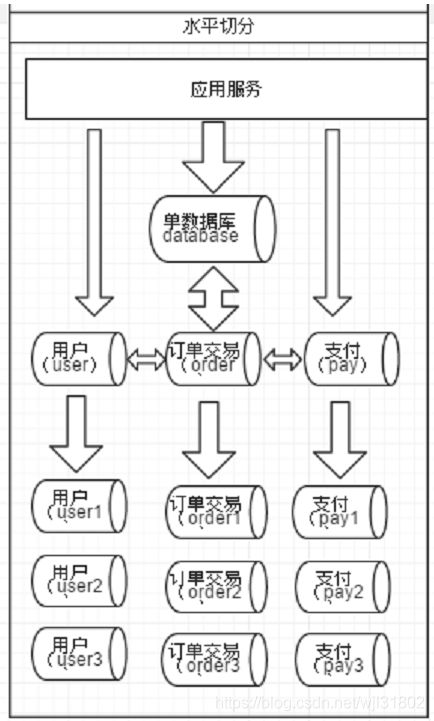
分片相关的概念
以mycat为例
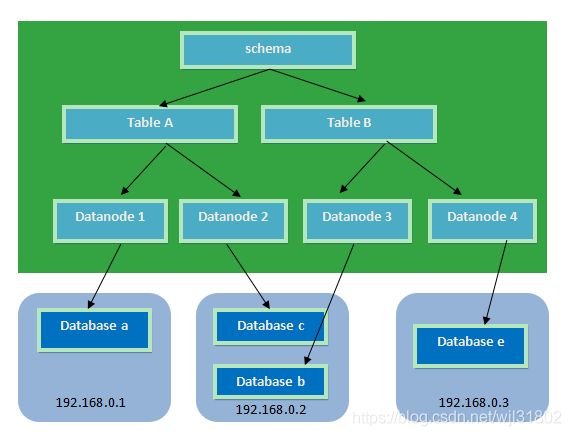
逻辑库(schema):数据库中间件可以被看做一个或多个数据库集群构成的逻辑库
逻辑表(table):对应用来说,读写数据的表就是逻辑表
分片表:需要进行分片的表
非分片表:不需要进行数据切分的表
分片节点(dataNode):数据切分后,一个大表被分到不同的分片数据库中,每个表分片所在的数据库就是分片节点。
节点主机(dataHost):数据切分后,每个分片节点不一定单独一台主机,可能多个分片节点在一台分片主机上
分片规则(rule):数据切分的规则
mycat分片规则
rule.xml用于定义分片规则,常见两种
- 按主键范围分片rang-long,在autopartition-long.txt里面配置
- 一致性哈希 murmur 设置节点权重,没有默认都是1
13. 索引
是帮助数据库高效获取数据的排好序的数据结构
优势:
1.索引能极大的减少存储引擎需要扫描的数据量
2.索引能将随机io变成顺序io
3.索引能够帮助我们进行分组、排序等操作时,避免使用临时表
劣势:
1.降低更新表的速度,mysql不仅要存储数据,同时还需要保留下一个节点的地址,当改变了索引后,索引树需要发生改变,保证B+Tree结构完整
2.占用空间
底层数据结构:默认使用的是B+TREE
- B+节点关键字采用闭合区间
- B+非叶子节点不保存数据相关信息,只保存关键字和子节点的引用
- B+关键字对应的数据存在叶子节点上
- B+树节点是按顺序排列的,相邻节点有顺序引用关系
14. 索引分类
1. 普通索引
是最基本的索引,它没有任何限制
CREATE INDEX index_name ON table(column(length))
2. 唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组
合必须唯一
CREATE UNIQUE INDEX indexName ON table(column(length))
3. 主键索引
一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) NOT NULL ,
PRIMARY KEY (`id`)
);
4. 组合索引
多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。 遵循 最左前缀集合
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
14. mysql的SQL语法技巧
1. null转0
代码示范
SELECT s.s_id,s.`s_name`,IFNULL(a.courseNum,0) 选课总数,IFNULL(a.scoreSum,0) 总成绩
from student s
left join
(SELECT s_id,COUNT(c_id) courseNum,SUM(s_score) scoreSum FROM score GROUP BY s_id)a
on
s.`s_id`=a.s_id
2. distinct去重
代码示范
SELECT * FROM student WHERE s_id NOT IN(
SELECT DISTINCT s.`s_id` FROM student s,score sc,course c
WHERE s.`s_id`=sc.s_id AND sc.c_id=c.c_id AND sc.s_score<70
)