(大)数据处理:从txt到数据可视化
Python 2.7
IDE Pycharm 5.0.3
numpy 1.11.0
matplotlib 1.5.1
本次可视化数据由机器学习实战倾情提供(就是盗用了数据和改了一点点程序更加易读)
前言
将txt中数据进行可视化展示用于分析需求
你只需要知道
每行的第一列数据是飞行里程,第二列是玩游戏所占百分比时间,第三列是每年吃的冰激凌消耗量,第四列是某个xx觉得这类人的适合约会的感兴趣程度,也就是说啦,他一年飞40920公里,有百分之八左右的时间在玩游戏,每年还要吃掉0.9公升哦,这个对象xx觉得好有魅力,非常想和它约会呢,就是这个意思!
准备食材
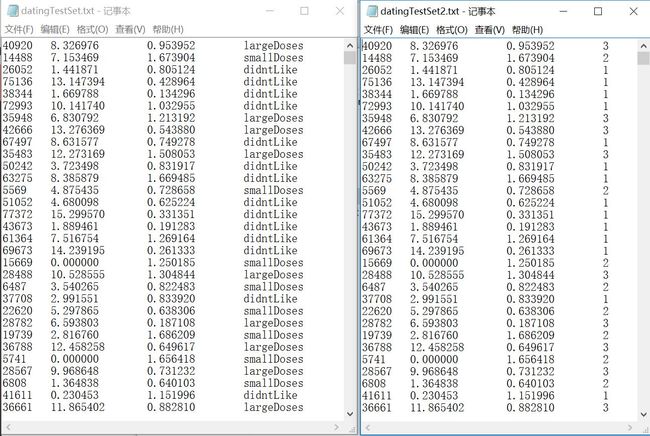
刚下载下来的txt是左边那个,第四列也就是类别了,但是中文怎么转化为右边那个数值强度呢?还是挺简单的,扫描每一行的时候把判断相等字符串直接替换就可以了,详细请看如下代码片段,这里单独拿出来看一下。
#将评价转化为数字
if listFromLine[3] == 'largeDoses':
listFromLine[3] =3
elif listFromLine[3] == 'smallDoses':
listFromLine[3]=2
else:
listFromLine[3]=1
经过转化之后,形式应该和右边那个一样了,非常想约会是3,一般是2,不想是1,就酱紫。这也就是类别了。
从txt到存入array数组
我现在接触到的保存在txt中数据的有(大)数据处理:从txt到MySql的数据预处理迁徙中的北京市一个月的出租车GPS数据(350G),高光谱数据AVIRIS遥感图像数据(.mat)也是可以转化为txt的,所以如何将txt数据清洗后存入到array也好,存入到database也好,这都是数据处理后续工作避不开的前提,废话不多说,开始。
完整代码
# -*- coding: utf-8 -*-
from numpy import *
import matplotlib.pyplot as plt
def file2matrix(filename):
fr = open(filename,'r')
arrayOlines = fr.readlines()
numberOfLines = len(arrayOlines)
returnMat = zeros((numberOfLines,3)) #构造全零阵来存放数
classLabelVector = [] #开辟容器
index = 0
for line in arrayOlines:
#清洗数据
line = line.strip()
listFromLine = line.split('\t')
#将评价转化为数字
if listFromLine[3] == 'largeDoses':
listFromLine[3] =3
elif listFromLine[3] == 'smallDoses':
listFromLine[3]=2
else:
listFromLine[3]=1
#存入数据到list
returnMat[index,:] = listFromLine[0:3] #三个特征分别存入一行的三个列
classLabelVector.append(int(listFromLine[3])) #最后一行是类别标签
index +=1
return returnMat,classLabelVector
#将喜欢强度转化为颜色
def ColorOfDatingLable(num):
datingLabels_rgb = []
for i in range(len(num)):
if num[i]==3:
datingLabels_rgb.append('red')
elif num[i]==2:
datingLabels_rgb.append('green')
else:
datingLabels_rgb.append('black')
return datingLabels_rgb
datingDataMat,datingLabels = file2matrix('C:\\Users\\MrLevo\\Desktop\\machine_learning_in_action\\Ch02\\datingTestSet.txt')
##################创建图表1#####################
plt.figure(1) #创建图表1
ax1 = plt.subplot(1,2,1) # 图表1中创建子图1
plt.title("original color")
plt.xlabel('play game/time %')
plt.ylabel('ice cream cost/week')
ax2 = plt.subplot(1,2,2) # 图表1中创建子图2
plt.title("improved color")
plt.xlabel('play game/time %')
plt.ylabel('ice cream cost/week')
###################创建图表2####################
plt.figure(2) #创建图表2
ax3 = plt.subplot(2,2,1) # 图表2中创建子图1
plt.title("play game & ice cream cost")
plt.xlabel('play game/time %')
plt.ylabel('ice cream cost/week')
ax4 = plt.subplot(2,2,2) # 图表2中创建子图2
plt.title("fly distance & play game")
plt.xlabel('fly distance/year')
plt.ylabel('play game/time %')
ax5 = plt.subplot(2,2,3) # 图表2中创建子图2
plt.title("fly distance & ice cream cost")
plt.xlabel('fly distance/year')
plt.ylabel('ice cream cost/week')
#plt.scatter(x[i],y[i],marker = 样式,s=大小半径,color =(np.random.rand(1,3)),label = str(i+1))
ax1.scatter(datingDataMat[:,1],datingDataMat[:,2],15*array(datingLabels),15*array(datingLabels)) #scatter散点图展示第二列和第三列数据
ax2.scatter(datingDataMat[:,1],datingDataMat[:,2],s=15*array(datingLabels),color=ColorOfDatingLable(datingLabels)) #scatter散点图展示第二列和第三列数据,第一个15*array(datingLabels)用来表现不同标签的不同半径
ax3.scatter(datingDataMat[:,1],datingDataMat[:,2],s=15*array(datingLabels),color=ColorOfDatingLable(datingLabels),label='largeDoses/smallDoses/didntLike')
ax4.scatter(datingDataMat[:,0],datingDataMat[:,1],s=15*array(datingLabels),color=ColorOfDatingLable(datingLabels),label='largeDoses/smallDoses/didntLike')
ax5.scatter(datingDataMat[:,0],datingDataMat[:,2],s=15*array(datingLabels),color=ColorOfDatingLable(datingLabels),label='largeDoses/smallDoses/didntLike')
ax3.legend(loc='upper right')
ax4.legend(loc='upper right')
ax5.legend(loc='upper right')
plt.show()
产生的效果图如下

对比图分析
从上图中可以看出,红点的密集区域以及各个维度之间的联系,其中吃不吃冰激凌,这个貌似并不能作为评判的影响性因素,因为冰激凌量的多少,完全符合了均匀分布。唯一有价值的算是第二幅图,我们可以看出,飞行时间在40000左右,玩游戏时间所占比例为10%左右,xx女士比较喜欢这样类型的男士,并且表现出了极大兴趣,而飞行时间过长,或者游戏时间很短,却不受她的青睐,我们这里揣测一下xx女士的想法,她喜欢的类型应该是比较活泼的,见多识广,但又能不经常出差希望陪伴在自己身边的男士,从飞行距离上看出,适当的旅行能增长见识,会更有趣,而过长的飞行时间,只能表明,他要么在出差,要么就属于那种全世界游玩的人,这样的不定性而缺乏安全感,我想这也就是xx女士并不喜欢这类男士的原因吧,而飞行时间很短,缺乏对外界的认识,让xx女士觉得这类男士缺乏见识和有趣度,你想,一个常年待在家的人,会有多少有趣呢,俗话说得好,读万卷书不如行万里路,我想也是xx女士判别一个人是否有趣的因素吧,而游戏时间上来说,过短的游戏时间,可能会让xx女士认为男士缺乏幽默,激情,智商的表现,毕竟游戏很多都是对一个人反应能力,情商,布局能力的各方面体现,所以,xx女士认为一个不玩游戏,并且飞行距离超长的男士,只能判断为长期出差在外,所以并不喜欢这类,而她对那些‘死宅’却保持着一般的兴趣,这点说明,死宅也有春天啊,哈哈哈。
改进代码
画散点阵scatter来说,它的参数设置是这样的:
#plt.scatter(x[i],y[i],marker = 样式,s=大小半径,color =颜色,label = 点备注
而书中的有一行代码是这样的,我相信也有小伙伴们觉得这个很奇怪:
ax1.scatter(datingDataMat[:,1],datingDataMat[:,2],15*array(datingLabels),15*array(datingLabels)) #scatter散点图展示第二列和第三列数据第一个好理解,15*array(datingLabels)它来规定点的尺度大小,而第二个的15*array(datingLabels)来表示颜色?很抱歉,我查找scatter颜色参数的过程中,没有看到这个表示方法的,可能我没找到吧,如果有人知道请告诉我一声为什么可以这么表示颜色。我目前知道的表示颜色的参数可以有类似“r”,或者三原色的数值表示的,并没有看到单数值表示的。所以我改进了一下,写了个ColorOfDatingLable函数,里面是将数值转换为颜色值对应起来。所用的语句是这个
ax2.scatter(datingDataMat[:,1],datingDataMat[:,2],s=15*array(datingLabels),color=ColorOfDatingLable(datingLabels)) #scatter散点图展示第二列和第三列数据,第一个15*array(datingLabels)用来表现不同标签的不同半径他们两的对比图我也放在一块比较了,如图显示

相比较而言,修改后的图更加清晰,特色明显。
你可能还需要知道
- 一些numpy的常用方式,请见numpy快速入门
- matplotlib的常用例子,致谢@星星点灯–Python图表绘制:matplotlib绘图库入门
- 它来自于机器学习之K-近邻算法(Python描述)基础并且只是其中处理数据的一部分
- matplotlib官方文档
致谢
numpy快速入门
@星星点灯–Python图表绘制:matplotlib绘图库入门
@MrLevo520–机器学习之K-近邻算法(Python描述)基础
matplotlib官方文档
@MrLevo520–(大)数据处理:从txt到MySql的数据预处理迁徙