常用算法 之一 详解 MD5 实现(基于算法的官方原文档)及源码详细注释
写在前面
在之前的工作中,用到了CRC16、MD5 和 SHA1 算法,主要用来校验下发的文件。网上关于这些算法的文章铺天盖地,以下内容仅仅是自己在学习时候的一个记录,一些套话来自于互联网。下面先来看看 MD5。
以下算法分析基于 RFC 1321。
- Request For Comments (RFC),所有关于Internet 的正式标准都是以RFC(Request for Comment )文档出版。需要注意的是,还有大量的RFC文档都不是正式的标准,出版目的都是为了提供信息。
- 由互联网协会(Internet Society,简称ISOC)赞助发行,会交到互联网工程工作小组(IETF)和互联网结构委员会(IAB)。文档可由网站 https://www.ietf.org/ 下载。
什么是 MD5
全称是 MD5 消息摘要算法(The MD5 Message-Digest Algorithm),对输入任意长度的消息进行处理,最终产生一个128位的消息摘要(散列值(hash value))。不同的输入得到的不同的结果(唯一性)。MD5 由美国密码学家罗纳德·李维斯特(Ronald Linn Rivest)设计,于1992年公开,用以取代 MD4 算法。这套算法的程序在 RFC 1321 中被加以规范(具体见附件)。
- MD5 是 MD4 的升级版,MD4 是麻省理工学院教授 Ronald Rivest 于1990年设计的一种信息摘要算法,目前用的也不是很多。再之前还有个 MD2,好像是 1989年发布的,目前基本已被淘汰。
- 散列(Hash): 把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。
- 杂凑冲撞/散列冲撞: 发现两段原文对应同一个MD5,则称为一次杂凑散列碰撞。
与 MD4 区别
根据规范文档,主要有以下几点:
- 增加了第四轮
- 每一步均有唯一的加法常数
- 为减弱第二轮中函数G的对称性从
(X&Y)|(X&Z)|(Y&Z)变为(X&Z)|(Y&(~Z)) - 第一步加上了上一步的结果,这将引起更快的雪崩效应
- 改变了第二轮和第三轮中访问消息子分组的次序,使其更不相似
- 近似优化了每一轮中的循环左移位移量以实现更快的雪崩效应,各轮的位移量互不相同
安全性
1996年后被证实存在弱点,可以被加以破解。2004年,证实 MD5 算法无法防止碰撞(collision)。2004年的国际密码讨论年会(CRYPTO)尾声,王小云及其研究同事展示了 MD5、SHA-0 及其他相关散列函数的散列冲撞。
实现原理
MD5 以 512 位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。基本就是下面这张图(该图在许多大学的课本上就可以看到,具体忘了出处,就重新画了一下)
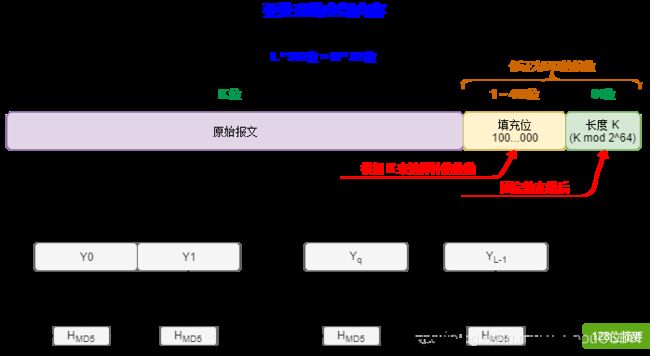
根据算法文档的描述,总共可以分为五步:
- 第一步:附加填充位: 如果输入信息的长度(bit)对512求余的结果不等于448,就需要填充使得对512求余的结果等于448。这里主要是为了保证计算的最后一定为512bits。具体看参见后文源码的函数:
void MD5Final(MD5_CTX *context, unsigned char digest[16])
填充方法: 在消息后面进行填充,填充第一位为1,其余为0。具体见下面源码的数组unsigned char PADDING[] - 第二步:附加长度: 用64位来存储填充前信息长度。这64位加在第一步结果的后面。将总的比特位位数附加到最后一包的最后,进行转换。
448 + 64 = 512 - 第三步:初始化 MD 缓冲区: 四个字(每个字32位)初始值(A,B,C,D)用于计算消息摘要。依次为:
A = 0x67452301,B = 0xEFCDAB89,C = 0x98BADCFE,D = 0x10325476 - 第四步:处理输入的数据: 这一步较为复杂,总共分两层循环:第一层为消息长度分的512bits的总包数(注意第一步的填充)下面的源码中,函数
void MD5Update(MD5_CTX *context, unsigned char *input, unsigned int inputlen)就是处理这层循环的,第二层循环为 16个32位子分组,以下面四个分组计算,共64次循环。下面的源码中,函数static void MD5Transform(unsigned int state[4], unsigned char block[64])就是处理这层循环的。- 规范定义了四个辅助函数,每个函数将三个32位字作为输入,并产生一个32位字作为输出。(& 表示与操作、| 表示或操作、~ 表示非操作、^ 表示异或操作)。64次子循环中,F、G、H、I 交替使用,第一个16次使用 F,第二个16次使用 G,第三个16次使用 H,第四个16次使用 I。
#define F(x, y, z) ((x & y) | (~x & z)) #define G(x, y, z) ((x & z) | (y & ~z)) #define H(x, y, z) (x ^ y ^ z) #define I(x, y, z) (y ^ (x | ~z))- 设 Mj 表示消息的第 j 个子分组(从0到15)。把原文的每512位再分成16等份,命名为M0 ~ M15,每一等份长度32。在64次子循环中,每16次循环,都会交替用到M1 ~ M16之一
FF(a,b,c,d,Mj,s,ti) 表示 a=b+((a+F(b,c,d)+Mj+ti)<<<s) GG(a,b,c,d,Mj,s,ti) 表示 a=b+((a+G(b,c,d)+Mj+ti)<<<s) HH(a,b,c,d,Mj,s,ti) 表示 a=b+((a+H(b,c,d)+Mj+ti)<<<s) II(a,b,c,d,Mj,s,ti) 表示 a=b+((a+I(b,c,d)+Mj+ti)<<<s)- 四轮运算,算法规定必须是四轮。具体见下面源码的函数
static void MD5Transform(unsigned int state[4], unsigned char block[64])
举个例子,假设输入的消息长度为N,那么第一层循环次数为 N / 512 (还需要考虑填充),第二层循环次数为512 / 32 *4 = 64。具体来看看下图(来自于维基百科的MD5介绍)。

这张图所表达的就是 单次子循环 的流程。图中的绿色F,代表以上四个辅助函数中的 F;红色的田字代表相加;Mi表示分为32位后的第 i 包数据;Ki是一个算法规定的常量,在64次子循环中,每一次用到的常量都是不同的;黄色的<<
新B = b+((a+F(b,c,d)+Mj+Ki)<<
新D = 原c
- 第五步:输出: 作为输出产生的消息摘要是A,B,C,D。也就是说,我们从A的低位字节开始,以D的高位字节结束。
源码
在RFC 1321文档中,作者不进给出了算法的具体描述以及与 MD4 的区别,还给出了一套实现好的 C 代码,下文说明就是基于该代码的。代码稍微简化了一下,因此与原文中的代码可能稍有不同。
仔细阅读以下源码会发现,源码的实现并不是严格按照上面说的顺序实现的。以下源码有非常详细的注释,具体参看注释即可,不在做过多说明。
- MD5.h
#ifndef MD5_H
#define MD5_H
/* MD5 context. */
typedef struct
{
/* 存储原始信息的bits数长度(不包括填充的bits),最长为 2^64 bits。如果消息长度大于2^64,则只使用其低64位的值,即(消息长度 对 2^64取模) */
unsigned int count[2];
/* 四个32bits数,用于存放最终计算得到的消息摘要。当消息长度大于 512bits时,也用于存放每个512bits的中间结果 */
unsigned int state[4];
/*存放输入的信息的缓冲区,512bits */
unsigned char buffer[64];
} MD5_CTX;
void MD5Init(MD5_CTX *context);
void MD5Update(MD5_CTX *context, unsigned char *input, unsigned int inputlen);
void MD5Final(MD5_CTX *context, unsigned char digest[16]);
#endif
- MD5.c
#include 使用方式
在实际使用时,往往需要多次调用循环计算。因为要计算的内容可能很长,需要分包一次次计算。上面的源码就是考虑到该种问题而实现的!使用方式如下:
MD5_CTX md5;
unsigned char encrypt[] = "admin"; //21232f297a57a5a743894a0e4a801fc3
unsigned char decrypt[16];
/* 计算前,先初始化 */
MD5Init(&md5);
/* 多次调用 MD5Update 循环计算多个包数据(如果有的话) */
MD5Update(&md5, encrypt, strlen((char *)encrypt));
/* 最后调用 MD5Final 获取最终结果 */
MD5Final(&md5, decrypt);
最终,在数组decrypt中存放的就是最终计算结果!
附件
- MD5 算法 官方文档 rfc1321