MTCNN与facenet实现实时人脸识别
MTCNN+facenet实现实时人脸识别
- 整体思路
- 步骤1--框架搭建
- 步骤2--人脸数据库构造
- 步骤3--训练SVM分类器
- 步骤4--实时人脸检测识别
整体思路
利用MTCNN进行人脸框提取,将提取后的人脸框送入facenet中提取出embedding,利用SVM对embedding进行分类,整个过程以视频提取帧作为输入,实现了利用摄像头实时进行人脸检测识别的功能。
mtcnn采用https://github.com/AITTSMD实现,facenet采用https://github.com/davidsandberg实现,程序是在facenet环境基础上实现。
该项目的github地址为:https://github.com/ninesky110/Real-time-face-recognition
步骤1–框架搭建
下载MTCNN的程序及模型(https://github.com/AITTSMD/MTCNN-Tensorflow)
下载facenet的程序及模型(https://github.com/davidsandberg/facenet)
对于facenet的程序,我们只用到了src/facenet.py程序,因此您可以仅仅下载该python文件;对于模型,github上作者给的模型链接下载不了(我自身原因),可以自行上网搜索模型下载。
将facenet.py文件拷贝至MTCNN-Tensorflow-master/test内(mtcnn中的文件夹);
在MTCNN-Tensorflow-master/test文件夹下新建一个RealtimeIdentification.py文件,本文中所有程序实现都在此py文件内进行,导入一些需要用到的包
import sys
sys.path.append("../")
import tensorflow as tf
import numpy as np
import argparse
import facenet
import os
import sys
import math
import pickle
from scipy import misc
from Detection.MtcnnDetector import MtcnnDetector
from Detection.detector import Detector
from Detection.fcn_detector import FcnDetector
from train_models.mtcnn_model import P_Net, R_Net, O_Net
import cv2
from sklearn.svm import SVC
步骤2–人脸数据库构造
拍摄所要识别的人脸图片,每个人脸拍8张不同角度的照片(当然也可以更多照片),将人脸的名字以文件夹的形式保存。我共收集了五个人的人脸信息,每个人对应一个文件夹,如下图所示:
 文件夹内的照片如下图所示:
文件夹内的照片如下图所示:
 因为facenet的图片输入尺寸为160×160×3,因此图片的尺寸要设定为160×160×3。
因为facenet的图片输入尺寸为160×160×3,因此图片的尺寸要设定为160×160×3。
人脸图片收集完毕之后,便可以利用facenet来构造我们的人脸数据库,数据库中存放的为每个人脸的embedding信息(即每个人脸用1×512维特征进行表示)。
在RealtimeIdentification.py文件内建立构造数据库的函数,如下所示
// An highlighted block
def face2database(picture_path,model_path,database_path,batch_size=90,image_size=160):
#提取特征到数据库
#picture_path为人脸文件夹的所在路径
#model_path为facenet模型路径
#database_path为人脸数据库路径
with tf.Graph().as_default():
with tf.Session() as sess:
dataset = facenet.get_dataset(picture_path)
paths, labels = facenet.get_image_paths_and_labels(dataset)
print('Number of classes: %d' % len(dataset))
print('Number of images: %d' % len(paths))
# Load the model
print('Loading feature extraction model')
facenet.load_model(model_path)
# Get input and output tensors
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
embedding_size = embeddings.get_shape()[1]
# Run forward pass to calculate embeddings
print('Calculating features for images')
nrof_images = len(paths)
nrof_batches_per_epoch = int(math.ceil(1.0*nrof_images / batch_size))
emb_array = np.zeros((nrof_images, embedding_size))
for i in range(nrof_batches_per_epoch):
start_index = i*batch_size
end_index = min((i+1)*batch_size, nrof_images)
paths_batch = paths[start_index:end_index]
images = facenet.load_data(paths_batch, False, False,image_size)
feed_dict = { images_placeholder:images, phase_train_placeholder:False }
emb_array[start_index:end_index,:] = sess.run(embeddings, feed_dict=feed_dict)
np.savez(database_path,emb=emb_array,lab=labels)
print("数据库特征提取完毕!")
#emb_array里存放的是图片特征,labels为对应的标签
if __name__ == "__main__":
picture_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_database"
model_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_models/facenet/20180408-102900"
database_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/Database.npz"
SVCpath="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_models/facenet/SVCmodel.pkl"
face2database(picture_path,model_path,database_path)
ClassifyTrainSVC(database_path,SVCpath)
#RTrecognization(model_path,SVCpath,database_path)
运行结束之后便可以在MTCNN-Tensorflow-master/test/中生成Database.npz的文件。
步骤3–训练SVM分类器
当MTCNN提取人脸框送入facenet提取特征之后,需要利用特征进行人脸分类,采用SVM分类器进行分类,程序如下所示
def ClassifyTrainSVC(database_path,SVCpath):
#database_path为人脸数据库
#SVCpath为分类器储存的位置
Database=np.load(database_path)
name_lables=Database['lab']
embeddings=Database['emb']
name_unique=np.unique(name_lables)
labels=[]
for i in range(len(name_lables)):
for j in range(len(name_unique)):
if name_lables[i]==name_unique[j]:
labels.append(j)
print('Training classifier')
model = SVC(kernel='linear', probability=True)
model.fit(embeddings, labels)
with open(SVCpath, 'wb') as outfile:
pickle.dump((model,name_unique), outfile)
print('Saved classifier model to file "%s"' % SVCpath)
if __name__ == "__main__":
picture_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_database"
model_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_models/facenet/20180408-102900"
database_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/Database.npz"
SVCpath="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_models/facenet/SVCmodel.pkl"
#face2database(picture_path,model_path,database_path)
ClassifyTrainSVC(database_path,SVCpath)
#RTrecognization(model_path,SVCpath,database_path)
运行结束之后便可以在test/face_models/facenet/中生成SVCmodel.pkl模型文件。
步骤4–实时人脸检测识别
def RTrecognization(facenet_model_path,SVCpath,database_path):
#facenet_model_path为facenet模型路径
#SVCpath为SVM分类模型路径
#database_path为人脸库数据
with tf.Graph().as_default():
with tf.Session() as sess:
# Load the model
print('Loading feature extraction model')
facenet.load_model(facenet_model_path)
with open(SVCpath, 'rb') as infile:
(classifymodel, class_names) = pickle.load(infile)
print('Loaded classifier model from file "%s"' % SVCpath)
# Get input and output tensors
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
embedding_size = embeddings.get_shape()[1]
Database=np.load(database_path)
test_mode = "onet"
thresh = [0.9, 0.6, 0.7]
min_face_size = 24
stride = 2
slide_window = False
shuffle = False
#vis = True
detectors = [None, None, None]
prefix = ['../data/MTCNN_model/PNet_landmark/PNet', '../data/MTCNN_model/RNet_landmark/RNet', '../data/MTCNN_model/ONet_landmark/ONet']
epoch = [18, 14, 16]
model_path = ['%s-%s' % (x, y) for x, y in zip(prefix, epoch)]
PNet = FcnDetector(P_Net, model_path[0])
detectors[0] = PNet
RNet = Detector(R_Net, 24, 1, model_path[1])
detectors[1] = RNet
ONet = Detector(O_Net, 48, 1, model_path[2])
detectors[2] = ONet
mtcnn_detector = MtcnnDetector(detectors=detectors, min_face_size=min_face_size,
stride=stride, threshold=thresh, slide_window=slide_window)
video_capture = cv2.VideoCapture(0)
# video_capture.set(3, 340)
# video_capture.set(4, 480)
video_capture.set(3, 800)
video_capture.set(4, 800)
corpbbox = None
while True:
t1 = cv2.getTickCount()
ret, frame = video_capture.read()
if ret:
image = np.array(frame)
img_size=np.array(image.shape)[0:2]
boxes_c,landmarks = mtcnn_detector.detect(image)
# print(boxes_c.shape)
# print(boxes_c)
# print(img_size)
t2 = cv2.getTickCount()
t = (t2 - t1) / cv2.getTickFrequency()
fps = 1.0 / t
for i in range(boxes_c.shape[0]):
bbox = boxes_c[i, :4]#检测出的人脸区域,左上x,左上y,右下x,右下y
score = boxes_c[i, 4]#检测出人脸区域的得分
corpbbox = [int(bbox[0]), int(bbox[1]), int(bbox[2]), int(bbox[3])]
x1=np.maximum(int(bbox[0])-16,0)
y1=np.maximum(int(bbox[1])-16,0)
x2=np.minimum( int(bbox[2])+16,img_size[1])
y2=np.minimum( int(bbox[3])+16,img_size[0])
crop_img=image[y1:y2,x1:x2]
scaled=misc.imresize(crop_img,(160,160),interp='bilinear')
img=load_image(scaled,False, False,160)
img=np.reshape(img,(-1,160,160,3))
feed_dict = { images_placeholder:img, phase_train_placeholder:False }
embvecor=sess.run(embeddings, feed_dict=feed_dict)
embvecor=np.array(embvecor)
#利用人脸特征与数据库中所有人脸进行一一比较的方法
# tmp=np.sqrt(np.sum(np.square(embvecor-Database['emb'][0])))
# tmp_lable=Database['lab'][0]
# for j in range(len(Database['emb'])):
# t=np.sqrt(np.sum(np.square(embvecor-Database['emb'][j])))
# if t
# tmp=t
# tmp_lable=Database['lab'][j]
# print(tmp)
#利用SVM对人脸特征进行分类
predictions = classifymodel.predict_proba(embvecor)
best_class_indices = np.argmax(predictions, axis=1)
tmp_lable=class_names[best_class_indices]
best_class_probabilities = predictions[np.arange(len(best_class_indices)), best_class_indices]
print(best_class_probabilities)
if best_class_probabilities<0.3:
tmp_lable="others"
cv2.rectangle(frame, (corpbbox[0], corpbbox[1]),
(corpbbox[2], corpbbox[3]), (255, 0, 0), 1)
cv2.putText(frame, '{0}'.format(tmp_lable), (corpbbox[0], corpbbox[1] - 2), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 0, 255), 2)
cv2.putText(frame, '{:.4f}'.format(t) + " " + '{:.3f}'.format(fps), (10, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(255, 0, 255), 2)
for i in range(landmarks.shape[0]):
for j in range(len(landmarks[i])//2):
cv2.circle(frame, (int(landmarks[i][2*j]),int(int(landmarks[i][2*j+1]))), 2, (0,0,255))
# time end
cv2.imshow("", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
print('device not find')
break
video_capture.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
picture_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_database"
model_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_models/facenet/20180408-102900"
database_path="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/Database.npz"
SVCpath="/home/zhangx/CVstudy/RealTime/MTCNN-Tensorflow-master/test/face_models/facenet/SVCmodel.pkl"
#face2database(picture_path,model_path,database_path)
#ClassifyTrainSVC(database_path,SVCpath)
RTrecognization(model_path,SVCpath,database_path)
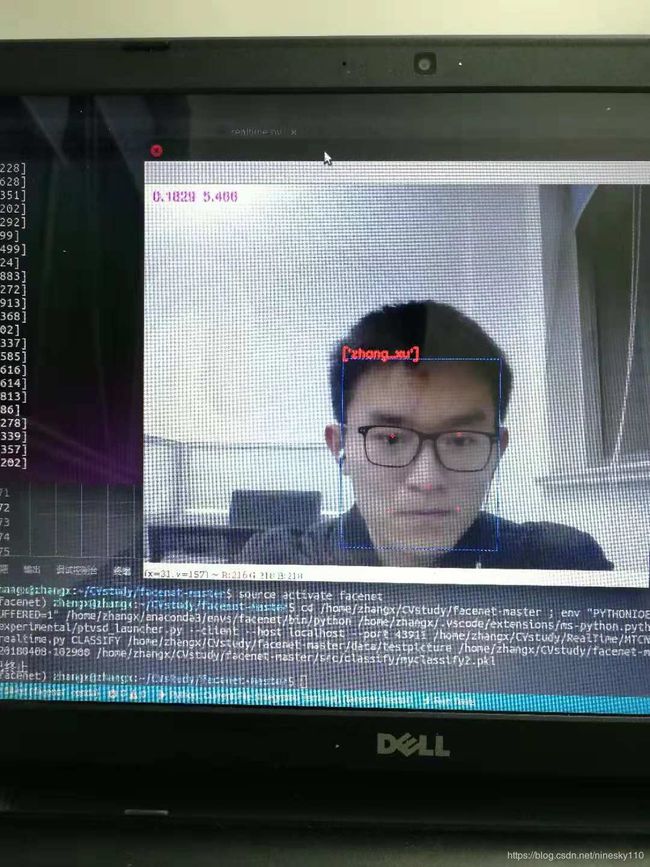
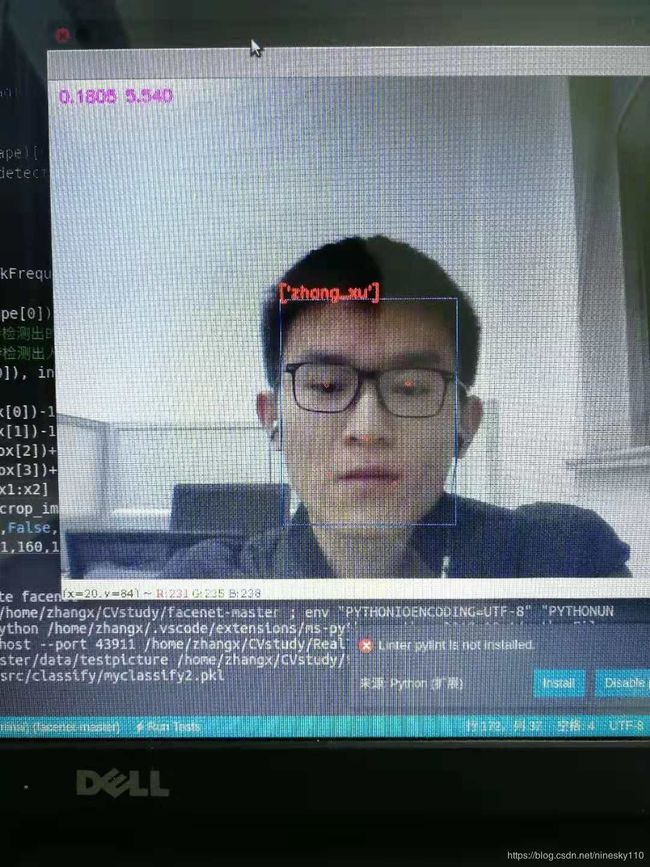
起初我是用MTCNN检测出的人脸经过facenet提取embedding后将其与人脸库中所有特征进行比较,选取欧式距离最小的人脸库label作为人脸框的label,不过在调试的时候发现这种方法速度较慢,且随着人脸数据库的数据的增大,速度会越来越慢,做不到实时性,因此改用例一个分类模型放在最后用于分类。
利用SVM模型进行分类时,以得分最高的类别作为分类类别,在此之外,设置了一个阈值0.3,预测人脸类别低于0.3的将其判定为“others“,即非数据库人物。
最终效果如下图所示,每秒识别5~6张图片,基本上可以做到实时性。