解读:信贷业务风控逾期指标及风控模型评估指标
<解读>信贷业务风控逾期指标及风控模型评估指标
一、互联网金融中需要关注的风控逾期指标
1.逾期天数 DPD (Days Past Due)
自应还日次日起到实还日期间的日期数
举例:DPDN+表示逾期天数 >=N天,如DPD30+表逾期天数 >=30天的合同
2.逾期期数
自应还日次日起到实还日期间的日期数
举例:
正常资产用C表示
Mn表示逾期N期:M1逾期一期,M2逾期二期,M3逾期三期,M4逾期四期,M5逾期五期,M6逾期六期
Mn+表示逾期N期(含)以上,M7+表示逾期期数 >=M7
3.贷款余额 ENR
至某时点借款人尚未偿还的本金,即:全部剩余本金作为贷款余额
4.月均贷款余额 ANR
月均贷款余额 = (月初贷款余额 + 月末贷款余额)/2,月初贷款余额即上月月底贷款余额
5.C,M1,M2,M3…的贷款余额
根据逾期期数(C,M1,M2,M3…),计算每条借款的当时的贷款余额
贷款余额 = 放款时合同额 –已还本金
已还本金 = (放款日次日 ~ T-1)的还款本金总额
6.核销金额
贷款逾期M7后经审核进行销帐,核销金额即在核销日期当天的贷款余额
7.回收金额 Recovery
来自历史所有已核销合同的全部实收金额
8.净坏账 NCL
当月新增核销金额 – 当月回收金额
9.在账月份 MOB
放款后的月份
举例:
MOB0,放款日至当月月底
MOB1,放款后第二个完整月份
MOB2,放款后第三个完整月份
10.(C->M1、M1->M2、M2->M3、M3->M4、M4->M5、M5->M6)滚动率 Flow rate
举例:
C-M1=当月进入M1的贷款余额/上月末C的贷款余额
M2-M3=当月进入M3的贷款余额/上月末M2的贷款余额
11.逾期率Coin©%、Coin(M1)%、Coin(M2)%、Coin(M3)%、Coin(M4)%、Coin(M5)%、Coin(M6)%
当月不同逾期期数的贷款余额/当月底总贷款余额
举例:
Coin©%=当月C贷款余额/当月底贷款余额(C-M6)
Coin(M1)%=当月M1贷款余额/当月底贷款余额(C-M6)
Coin(M1+)%=当月M1−M6贷款余额/当月底贷款余额(C-M6)
12.逾期率Lagged(M1)%、Lagged(M2)%、Lagged(M3)%、Lagged(M4)%、Lagged(M5)%、Lagged(M6)%
当月不同逾期期数的贷款余额/往前推N个月的总贷款余额
举例:
Lagged(M1)%=当月M1的贷款余额/上个月底的贷款余额(C~M6)
Lagged(M4)%=当月M4的贷款余额/往前推四期的 总贷款余额
Lagged(M4+)%=当月M4的贷款余额/往前推四期的总贷款余额
+ 当月M5的贷款余额/往前推五期的总贷款
+ 当月M6的贷款余额/往前推六期的总贷款余额
13.账龄分析Vintage
统计每个月新增放款在之后各月的逾期情况
解读模型评估指标
在建好模型后,我们需要对模型的质量进行评估。模型中常见的分类模型评估指标一般是通过混淆矩阵计算而来。
二、解读模型评估指标
模型评估之 — 混淆矩阵

TP(实际为正预测为正),FP(实际为负但预测为正),TN(实际为负预测为负),FN(实际为正但预测为负)
通过混淆矩阵我们可以给出各指标的值:
- 召回率(Recall,TNR):预测对的正例数占真正的正例数的比率计算公式:
Recall=TP / (TP+FN)
- 准确率:反映分类器统对整个样本的判定能力,能将正的判定为正,负的判定为负,计算公式:
Accuracy=(TP+TN) / (TP+FP+TN+FN)
- 精准率:指的是所得数值与真实值之间的精确程度;预测正确的正例数占预测为正例总量的比率,计算公式:
Precision=TP / (TP+FP)
- 阴性预测值:阴性预测值被预测准确的比例,计算公式:
NPV=TN / (TN+FN)
- F值:F-score是Precision和Recall加权调和平均数,并假设两者一样重要,计算公式:
F1 Score=(2RecallPrecision) / (Recall+Precision)
模型评估之 — ROC图和AUC
ROC曲线说明:
Sensitivity=正确预测到的正例数/实际正例总数
1-Specificity=正确预测到的负例数/实际负例总数
纵坐标为Sensitivity(True Positive Rate),横坐标为1-Specificity(True Negative Rate),ROC 曲线则是不同阈值下Sensitivity和1-Specificity的轨迹。
**阈值:**阈值就是一个分界线,用于判定正负例的,在模型预测后我们会给每条预测数据进行打分(0 **AUC(Area Under the ROC Curve)**指标在模型评估阶段常被用作最重要的评估指标来衡量模型的准确性,横坐标为其中随机分类的模型AUC为0.5,所以模型的AUC基线值大于0.5才有意义。 模型的ROC曲线越远离对角线,说明模型效果越好,ROC曲线下的区域面积即为AUC值,AUC值越接近1模型的效果越好。随着阈值的减小,Sensitivity和1-Specificity也相应增加,所以ROC曲线呈递增态势。 评估指标之 — Lift提升图 Lift =[TP/(TP+FP)] / [(TP+FN)/(TP+FP+FN+TN)] = PV_plus / pi1,它衡量的是,与不利用模型相比,模型的预测能力“变好”了多少,lift(提升指数)越大,模型的运行效果越好。 不利用模型,我们只能利用“正例的比例是(TP+FN)/(TP+FP+FN+TN)”这个样本信息来估计正例的比例(baseline model),而利用模型之后,我们不需要从整个样本中来挑选正例,只需要从我们预测为正例的那个样本的子集TP+FP中挑选正例,这时预测的准确率PV_plus(Precision)为TP/(TP+FP)。 上图的纵坐标是lift,横坐标是正例集百分比。随着阈值的减小,更多的客户就会被归为正例,也就是预测成正例的比例变大。当阈值设得够大,只有一小部分观测值会归为正例,但这一小部分一定是最具有正例特征的观测值集合(用前面银行向客户推荐信用卡的例子来看,这一部分人群对推荐的反应最为活跃),所以在这个设置下,对应的lift值最大。同样,当阈值设定得足够的小,那么几乎所有的观测值都会被归为正例(占比几乎为100%)——这时分类的效果就跟baseline model差不多了,相对应的lift值就接近于1。 ROC曲线和lift曲线都能够评价逻辑回归模型的效果:类似信用评分的场景,希望能够尽可能完全地识别出有违约风险的客户,选择ROC曲线及相应的AUC作为指标; 类似数据库精确营销的场景,希望能够通过对全体消费者的分类而得到具有较高响应率的客户群从而提高投入产出比,选择lift曲线作为指标; 评估指标 — Gain增益图 Gains(增益) 与 Lift (提升)类似:Lift 曲线是不同阈值下Lift和Depth的轨迹,Gain曲线则是不同阈值下PV_plus和Depth的轨迹,而PV_plus=Lift*pi1= TP/TP+FP,所以它们显而易见的区别就在于纵轴刻度的不同。 增益图是描述整体精准率的指标。按照模型预测出的概率从高到低排列,将每一个百分位数内的精准率指标标注在图形区域内,就形成了非累积的增益图。如果对每一个百分位及其之前的精准率求和,并将值标注在图形区域内,则形成累积的增益图。 模型评估之 — K-S图 正样本洛伦兹曲线记为f(x),负样本洛伦兹曲线记为g(x),K-S曲线实际上是f(x)与g(x)的差值曲线。K-S曲线的最高点(最大值)定义为KS值,KS值越大,模型分值的区分度越好,KS值为0代表是最没有区分度的随机模型。准确的来说,K-S是用来度量阳性与阴性分类区分程度的。 其实通常在实际使用的过程中,我们大多数都是通过AUC指标和Recall召回率来判断一个二分类模型的。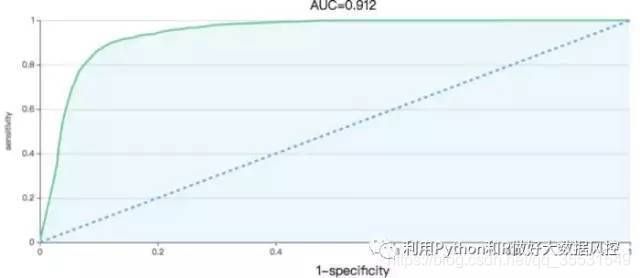


来源于66号学苑