【深度之眼吴恩达机器学习第四期】笔记(十)
目录
- 异常点检测
- 高斯分布
- 异常点检测和监督学习
- 选择特征
- 多元高斯分布
- 使用多元高斯分布的异常点检测算法
- 原始模型VS.多元高斯分布的模型
- 编程
异常点检测
假如有一个关于飞机引擎的数据集,而且这些飞机引擎都是能良好运行的。现在得到一个新的飞机引擎的数据,希望知道它是否能运行良好。
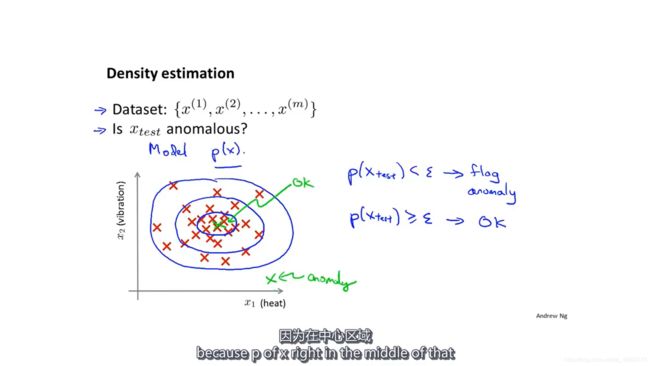
在下图中,红色的数据点是正常的样本,那么,右下角的绿色点就是一个异常点。

对于给定的数据集,异常点检测学习到的模型是P(x),也就是说,给定一个数据,预测得到一个概率,代表该数据正常的概率。如果这个概率小于特定阈值,那么就认为它是一个异常点。
异常点检测的应用:
- 作弊行为检测。使用登录频率,某个页面的访问次数(或交易次数),用户在论坛上的发帖次数,打字的频率等等,检测这个用户的行为是否正常(作弊行为)。然后进行进一步筛选或要求该用户给出身份验证等等,从而保证网站的安全。
- 工业上检测某个新零件是否符合标准。
- 在计算机集群中检测计算机是否运行良好。如果一个计算机运行良好的概率很低,那么它有可能出现什么问题了,可以让工作人员去人工检查一下。

高斯分布
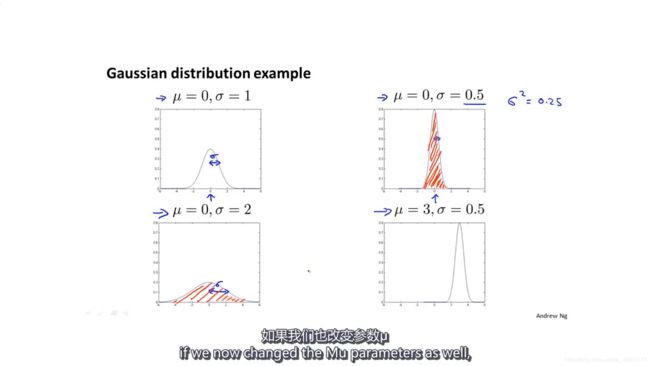
如果x服从均值为mu和方差为sigma2的高斯分布。mu是概率最大的x,sigma和钟型线的下降速度有关,sigma越小,钟型线越高,越瘦;sigma越大,钟型线越矮,越胖。因为对于钟型线积分,结果总是1。

当x=mu+sigma的时候,指数上的数恒为-1/2,决定该点概率(钟型线高度)的就只有sigma。sigma越大,该点概率越小,所以整体图形就更胖。
参数估计:给定一组数据,假设它服从高斯分布,那么就需要求出高斯分布中的mu和sigma。通过极大似然估计可以得到mu和sigma的公式如下。学过概率论的人可能会知道概率论中sigma2的分母是m-1而不是m,这两个理论上有差别,但是在实际应用中,由于机器学习的数据量很大,所以两者差别并不大。

密度估计:假设数据X的每个分量都服从高斯分布,那么X=Xi的概率就是Xi的每一个特征取特定值的概率的乘积。当然,前面的说法是在X的各个特征独立的情况下才成立的,但是实际应用中,就算特征不独立,这个方法也能得到很好的结果。

异常点检测算法:
- 选择你认为对异常点检测有用的特征;
- 对每个特征,求出mu和sigma;
- 计算出p(x),如果p(x)

异常点检测的例子

评估系统:如果有一个方法能评估系统的好坏程度,那么在要不要增加新特征等问题上会方便得多。
假设的数据集是有标签的,然后把它们分为训练集,验证集和测试集。训练集上训练数据是不需要使用标签的,而且训练集上的数据都是正常的(其实混进少量的异常数据也不会有很大问题)。

一般来说,异常点检测的数据中y=1的(异常的)都很少。60%,20%,20%是一个不错的划分方式。但有人会使用60%,40%,40%的数据划分方式(测试集和验证集完全相同),不建议这么做,但是在异常点检测中,有人会这么做。

由于样本分布不平均(异常点很少),所以不能直接使用预测准确率来评估模型,应该使用F1分数。
超参数epsilon需要通过验证集来选择。

异常点检测和监督学习
既然异常点检测也有数据标签,为什么不直接用监督学习来学习模型呢?
- 如果正负样本都很多,那么的确可以使用监督学习来学习模型。但是如果正样本(异常点)很少(一般只有0-20个,最多50来个),监督学习就可能没办法得到很好的结果。
- 可以从另一个方面考虑为什么使用异常点检测。异常点有很多种类型,在正样本很少的时候,监督学习并不能学习到所有类型的异常,而且新的异常有可能和已有的异常是完全不同类型的。而在正负样本都很多的时候,负样本很大概率包含了所有的异常类别,所以新样本的异常类型会和以前的相似,这时就应该使用监督学习。
换句话说,监督学习是同时学习正负样本的特点,然后根据这些特点判别一个新样本是正样本还是负样本。而异常点检测只学习负样本的特点,如果新样本不符合负样本的特点,那么它就是正样本。

选择特征
之前一直都是假设特征服从高斯分布的,如果它不符合高斯分布怎么办?
在使用特征前,先把特征的分布直方图画出来,如果它符合高斯分布,那很好;如果不符合,那么就可以对它做一些变换。其实就算它不是高斯分布也能运行正常,所以画出分布直方图只是一种检测。
可以对数据进行对数变换,多项式变换等等,从而使数据看起来更像高斯分布。

误差分析:对于异常点,希望p(x)比较小,对于正常点,希望p(x)比较大。但是,如果正常点和异常点的预测概率p(x)都很大怎么办?比如左图中的异常点(绿色叉)就有比较大的概率。应该把这个异常点拿出来,人为地找到一些新的特征,这样就能使异常点的概率p(x)比较小了。

一个增加新特征的例子:在监督计算机集群时,假设CPU负载和网络流量是成线性关系的,但是出现了一个问题,计算机进入了死循环,这时CPU负载很高,但是网络流量很低。那么就可以设计一个新的特征为CPU负载/网络流量,或者CPU负载2/网络流量(这和原来的特征不会线性相关)。

多元高斯分布
如果直接使用上面的方法计算p(x)的概率,那么概率的等高线应该是粉红色的线,对于绿色的叉来说,这个模型会认为它不是异常点。
实际上,概率的等高线是蓝色的线,这就要用到多元高斯分布。

多元高斯分布不使用单独的sigma,而是用一个sigma矩阵(Σ)来代替单独的sigma(σ)。

sigma矩阵的参数对概率函数的影响:
同时缩放对角线(乘以一个缩放矩阵)

只缩放对角线的某一元素(乘以一个缩放矩阵)

设置对角线以外的元素(乘以一个旋转矩阵)
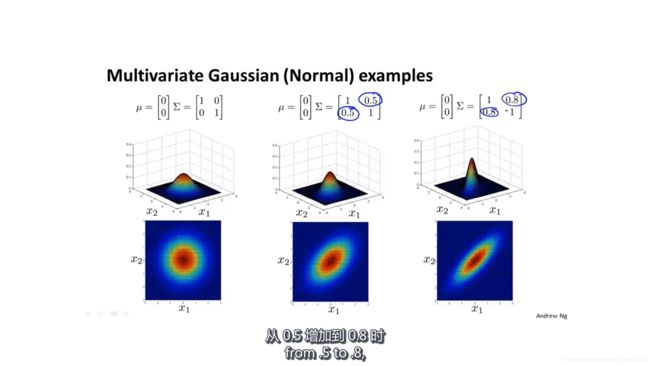
对角线以外的元素设置为负(乘以一个旋转矩阵)

改变mu

总而言之,多元高斯分布能描述不同特征之间的关系,能够更好的表现数据分布的形式。
使用多元高斯分布的异常点检测算法
使用多元高斯分布时的参数估计。这个sigma矩阵和PCA(主成分分析)中的一样。

使用多元高斯分布的异常点检测算法。

原始模型只是使用多元高斯分布的模型的一种特殊形式罢了,只要把原始模型的sigma2放到sigma矩阵的对角线上,两者就能得到同一个模型。

原始模型VS.多元高斯分布的模型
- 原始的模型更常用一点,但是使用多元高斯分布的模型能自动捕获特征间的关系,比如之前提到的CPU负载和网络流量之间的关系。而这种关系在原始模型中需要人识别出来,并手动添加。
- 当然,原始的模型也有其优点,它的最大优点是运行花销较小,也就是说即使在特征的个数n=100000时也能运行的很好。而使用多元高斯分布的模型要计算矩阵的逆,所以在特征的个数n很大的时候运行缓慢。
- 原始模型的另一个优点是:即使训练数据m很少也能运行良好,而使用多元高斯分布的模型在m
- 建议在m>=10n时使用多元高斯分布的模型,因为这个模型需要的参数sigma矩阵是n*n的,要有足够的数据才能学习到这些参数,而不至于过拟合。
- 如果在使用多元高斯分布的模型时发现sigma矩阵不可逆,那么有两种可能:m

编程
导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from scipy.io import loadmat加载并展示数据
data = loadmat('data/ex8data1.mat')
# 获取训练数据
X = data['X']
# (307, 2)
X.shape
# 获取验证数据集,用于训练超参数阈值epsilon
Xval = data['Xval']
yval = data['yval']
# ((307, 2), (307, 1))
Xval.shape, yval.shape
# 展示训练数据集
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(X[:,0], X[:,1])
plt.show()
参数估计,找到特征服从的高斯分布
def estimate_gaussian(X):
# INPUT:数据X
# OUTPUT:数据的均值和方差
mu = X.mean(axis=0)
sigma = X.std(axis=0)
return mu, sigma
mu, sigma = estimate_gaussian(X)
# (array([14.11222578, 14.99771051]), array([1.35374717, 1.3075723 ]))
mu, sigma计算各个特征的概率
from scipy import stats
dist = stats.norm(mu[0], sigma[0])
# 特征x1=15的概率为0.23767635105892454
dist.pdf(15)
# array([0.21620977, 0.25745208, 0.29413223, 0.24721192, 0.27251547])
dist.pdf(X[:,0])[0:5]
# 把训练数据转化为特征的概率
p = np.zeros((X.shape[0], X.shape[1]))
p[:,0] = stats.norm(mu[0], sigma[0]).pdf(X[:,0])
p[:,1] = stats.norm(mu[1], sigma[1]).pdf(X[:,1])
# (307, 2)
p.shape
# 把验证数据转化为特征的概率
pval = np.zeros((Xval.shape[0], Xval.shape[1]))
pval[:,0] = stats.norm(mu[0], sigma[0]).pdf(Xval[:,0])
pval[:,1] = stats.norm(mu[1], sigma[1]).pdf(Xval[:,1])
# (307, 2)
pval.shape用验证集寻找超参数,这里直接使用了验证集而没有使用训练集,是因为模型除了超参数epsilon以外就没有参数了,如果有一般的参数才要先在训练集训练。
def select_threshold(pval, yval):
# INPUT:交叉验证集数据pval,标签yval
# OUTPUT:最好的参数epsilon,最高的得分F1
best_epsilon = 0
best_f1 = 0
f1 = 0
# 各个特征的概率乘起来就是该数据的概率
pval_ = np.multiply(pval[:,0],pval[:,1])
# 和pval_保持相同的维度
yval = yval.reshape((len(yval)))
# 概率最高的和概率最低的区间分为1000份,在这1000个epsilon里寻找最优的
step = (pval_.max() - pval_.min()) / 1000
for epsilon in np.arange(pval_.min(), pval_.max(), step):
# 小于阈值epsilon的预测为正样本(异常点)
preds = pval_ < epsilon
tp = np.sum(np.logical_and(preds==1,yval==1))
fp = np.sum(np.logical_and(preds==1,yval==0))
fn = np.sum(np.logical_and(preds==0,yval==1))
precision = tp/(tp+fp)
recall = tp/(tp+fn)
f1 = (2*precision*recall)/(precision+recall)
if f1 > best_f1:
best_f1 = f1
best_epsilon = epsilon
return best_epsilon, best_f1
epsilon, f1 = select_threshold(pval, yval)
# (8.990852779269493e-05, 0.8750000000000001)
epsilon, f1画出异常点数据
# indexes of the values considered to be outliers
outliers = np.where(p < epsilon)
# (array([300, 301, 303, 304, 305, 306], dtype=int64),)
outliers
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(X[:,0], X[:,1])
ax.scatter(X[outliers[0],0], X[outliers[0],1], s=50, color='r', marker='o')
plt.show()