爬取雪球网股票信息(一)
这篇是爬取股票名称,我用了三个模块来实现。Crwal_Share_Names、Saved_MongDB、DEFINITION.
首先是最简单的一个模块:DEFINITION,定义,这个模块里面定义了要爬取的url序列和HEADERS,
其url是如图网站中的:
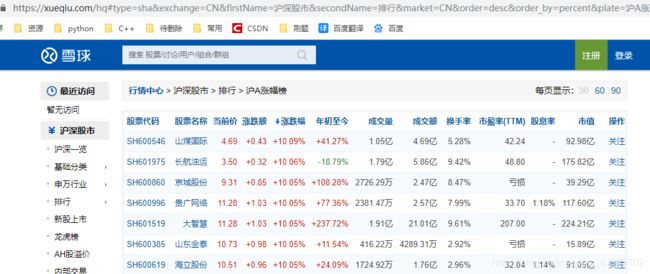
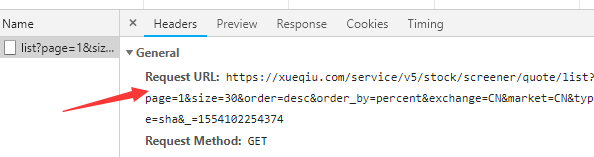
这个url的会返回一个层层嵌套的字典,字典中有我们需要的信息:
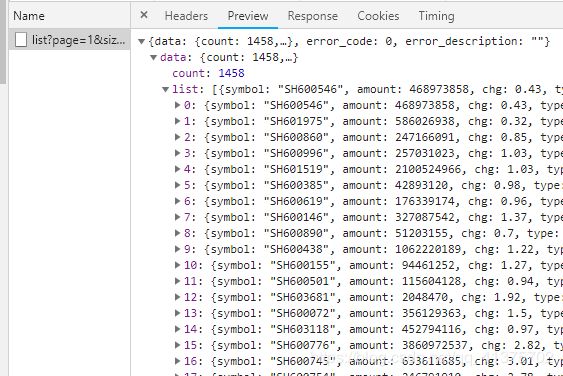
HEADERS为:Cookies和User-Agent
下面是DEFINTION的源码,如果其中URL_LIST里面的url失效,则重新加入即可。
#order_by,type,_
list_order_by=['percent',]
URL_LIST=[
#{page}
#沪A涨幅榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=percent&exchange=CN&market=CN&type=sha&_=1554089990960",
#沪A成交量排行榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=volume&exchange=CN&market=CN&type=sha&_=155409025214",
#沪A成交额排行榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha&_=1554090638063",
# 沪B涨幅榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=percent&exchange=CN&market=CN&type=shb&_=1554090694971",
#沪B成交量排行榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=volume&exchange=CN&market=CN&type=shb&_=1554090725471",
#沪B成交额排行榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=shb&_=1554090754809",
# 深A成交额排行榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sza&_=1554090798062",
#深A成交量排行榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=volume&exchange=CN&market=CN&type=sza&_=1554090826152",
#深A涨幅榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=percent&exchange=CN&market=CN&type=sza&_=1554090882203",
#深B涨幅榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=percent&exchange=CN&market=CN&type=szb&_=1554091104976",
#深B成交量排行榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=volume&exchange=CN&market=CN&type=szb&_=1554091138333",
#深B成交额排行榜
"https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=szb&_=1554091164545",
]
HEADERS={
'Cookie': '_ga=GA1.2.1454001628.1553229520; device_id=f3cca6bc0ac4c9015624a453cc1e618c; s=dx1211zr9m; __utmz=1.1553229617.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); u=961553732228048; aliyungf_tc=AQAAAB/nFTVR4AMA+Z8G3Wv/2VC5UXM6; xq_a_token=863a7c645ec00c0e71991b15cb194a5698bc77f0; xq_r_token=76ffeecdbb180d3e0f2d0a121034c63b6d515296; Hm_lvt_1db88642e346389874251b5a1eded6e3=1553736060,1553772223,1553996510,1554089968; __utma=1.1454001628.1553229520.1554001496.1554089968.8; __utmc=1; __utmt=1; __utmb=1.3.10.1554089968; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1554089991',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
}
第二个模块为Saved_MongDB,是一个将爬取到的名称存储到MongDB数据库。里面只有一个简单的函数,saved_name,另一个save_comment是为了接下来保存评论。
其中关键点是: result = collection.update_one({"NAME":name['NAME']}, {'$set': name}, True),这条语句为有同样是则更新,没有同样的内容时则插入。
源码如下:
'''
保存信息到MONGDB
1、save_name保存股票名
2、save_comment保存每只股票下面的评论
'''
import pymongo
from pymongo import MongoClient
client=MongoClient('mongodb://localhost:27017/')
db = client.shares # 指定数据库
def save_name(n):
collection = db.names
name={
"NAME":n,
}
result = collection.update_one({"NAME":name['NAME']}, {'$set': name}, True)
def save_comment(symbol,comment):
collection = db.comment
comment={
'SYMBOL':symbol,
'Comment':comment
}
result=collection.update_one({"Comment":comment['Comment']},{'$set':comment},True)
def main():
print("This is a testing....")
if __name__ == '__main__':
main()最后一个模块为:Crawl_share_names,这个模块有两个主要方法,get_share_names和main。get_share_names实现网页的解析,main实现url的构造
get_share_names接受一个完整的url,并爬取它,获得一个json格式的数据,接着层层解封,可以得到symbol,这就是股票对应的名称。
main函数实现url的构造,
首先用for循环,遍历DEFINTION中的URL_LIST,得到的是不完整的url。
然后再次使用for循环,利用format方法,构造不同页码的url,
最后将这些构造好的url分别传入get_share_names
总结:
第一步先做的是局部请求,请求单个url并解析(反爬),看是否能解析成功,第二部构造多个url,将解析写成函数,并传入url,完成大规模解析。第三部保存到数据库等常规操作。
Crawl_share_names源码:
'''
得到股票名
'''
import requests
import Saved_MongDB
import DEFINITON
import re
import time
name_list=[]
#沪A涨幅榜
def get_share_names(url):
#发送请求得到一个列表
response=requests.get(url=url, headers=DEFINITON.HEADERS)
html=response.json()
#逐层查找
try:
for one in html['data']['list']:
name_list.append(one['symbol'])
Saved_MongDB.save_name(one['symbol'])
except:
print('-------------------------------------20lines')
def show_names():
list_b = []
for i in name_list:
if i not in list_b:
list_b.append(i)
for i in range(1, len(list_b)):
print(i, '\t', list_b[i])
'''
order_by:
percent:涨幅榜
volume:成交量排行榜
amount:成交额排行榜
type:
沪A:sha
沪B:shb
深A:sza
深B:szb
'''
def main():
start=time.perf_counter()
for num in range(len(DEFINITON.URL_LIST)):
for pag in range(1,49):
#构造url
url=DEFINITON.URL_LIST[num].format(page=pag)
#找出请求的链接是那种股票、页码是多少、按什么方式排序的
Type=re.findall('type=(.*?)&',url)
order_by=re.findall('order_by=(.*?)&',url)
print("type:{Type}'\t',page:{page},'\t'order_by:{order_by}".format(Type=Type,page=pag,order_by=order_by))
#得到股票的名字
get_share_names(url)
end=time.perf_counter()
print("总共用时:{0}s".format(end-start))
if __name__ == '__main__':
main()
#