2018秋招面试问题(十五、MySQL基础(4))
第六部分:多表数据记录查询(join)
关系数据操作:
并:并就是把具有相同字段数目和字段类型的表合并到一起。合并的时候重复的记录只出现一次。
笛卡儿积(交叉连接):就是直接将两个表合起来,前几个字段是a表的,后几个字段是b表的,总记录数是a记录数*b记录数。就是个排列组合。
内连接:就是在笛卡儿积数据记录中,保留表关系中所有匹配的数据记录,舍弃不匹配的数据记录。
内连接按照匹配的条件可以分为自然连接、等值连接、不等连接。
外连接:是一个范围。
左外连接:左边表全部显示,右边表只显示匹配记录。
右外连接:右边表全部显示,左边表只显示匹配记录。
全外连接:左右表都全部显示。左表和右表都不做限制,所有的记录都显示,两表没有记录的地方用null 填充。
MYSQL中推荐使用子查询来实现多表查询数据记录。
子查询:就是指在一个查询中嵌套了其他的若干查询,比如在select中的from或者where中包含了另一个select查询语句。
步骤:
1.先通过count查看两个表笛卡儿积之后的数据记录数。
2.如果数据记录数MYSQL可以接受,就进行多表记录查询。
第七部分:运算符操作
select 6/2,6*2,6+2+2,6-2-2,6%2;
“=”“<=>”是判断相等的。“=”不能操作NULL,“<=>”可以操作NULL。可以判断数值、字符、表达式。
select 1=1,'sub'='sub',1<=>1,'sub'<=>'sub';
”!=“ ”<>“是判断不相等的。同样可以判断数值、字符、表达式。
这两个都不能操作NULL。
”^“表示匹配字符串的开始部分。
select 'cjgong' regexp '^c' A,'cjgonggong' regexp '^cjgong' B;
”$“表示匹配字符串的结束部分。
select 'cjgong' regexp 'g$' A,'cjgong' regexp 'gong$';
”.“表示匹配字符串中任意一个字符。从任意起点开始比较。
select 'cjgong' regexp '.g' A,'cjgong' regexp '.a','cjgong' regexp '......g','cjgong' regexp '.....g';
//结果是1,0,0,1
”[]“表示是否包含集合内的任意一个字符,”[^]“表示包含集合外的任意一个字符。
select 'cjgong' regexp '[abc]','cjgong' regexp '[a-zA-Z]','cjgong' regexp '[^abc]','cjgong' regexp '[^cjgong]';
//结果是1,1,1,0,其中a-z表示a到z的所有字母,A-Z表示A到Z的所有字母。
”*“表示0个或任意个字符,”+“表示至少得有一个字符。这两个判断的是相邻字符。
select 'cjgong' regexp 'c*o','cjgong' regexp 'c+o','cjgong' regexp 'j+g';
//判断o前面有没有c,o前面有没有c,g前面有没有j
”|“表示是否包含任意一个字符串。
select 'cjgonggongj' regexp 'aj|pag|goa|jg';
”c{M}“表示字符串c连续出现M次,”c{M,N}“表示c字符串连续出现至少M次,最多N次。
select 'cjgongngo' regexp 'g{2}','cjgongmngsng' regexp 'ng{1,2}';
//结果是1,0
逻辑运算符:
与、或、非、异或(XOR)
其中操作数中有一个NULL都是返回NULL。
select 3 || 4,0 && 3,4 XOR 5,!3;
位运算符:
& | ~ ^ << >>
select 5&6,bin(5&6),5&6&7,bin(5&6&7);
select ~4,bin(~4);
select 5<<4,bin(5<<4),5>>3,bin(5>>3);
第八部分:MYSQL常用函数
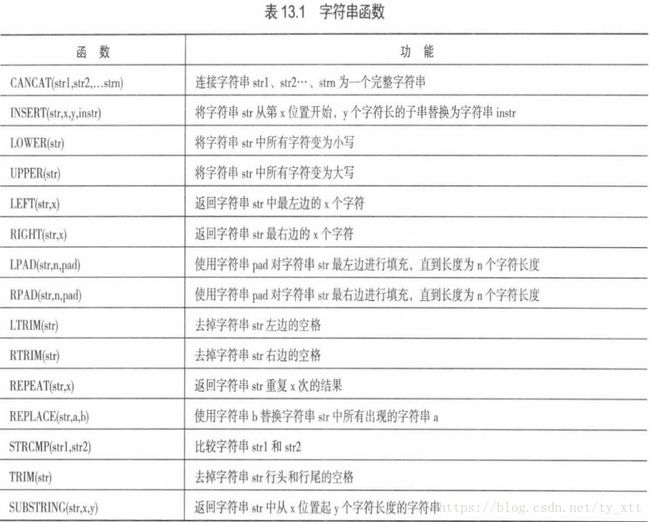
select concat('my','s','ql'); //合并字符串,输出mysql。concat中如果有一个NULL。
select concat(curdate(),12.13);//合并当地时间与12.13
比较字符串大小,比较ASCII码:
select strcmp('abc','bac'),strcmp('bmp','azy');
字符串长度,一个英语字母占一个字节,一个汉字占2个字节:
select length('mysql'),length('唐宇'); //结果是5和4
大小写转换函数:
select upper('mysql'),lower('MySQL');
查找字符串,返回字符串位置:
find_in_set(str1,str2);
select find_in_set('mysql','oral,mysq,MYSQL,mysql');//第二个str中字符串必须以逗号隔开,返回值是3,查找不区分大小写
field(str1,str2,str3...);
select field('mysql','str','oral','mysq','MYSQl');//返回值4,不区分大小写
查找字符串匹配的开始位置:
locate(str1,str2);
select locate('Sql','mysql');//返回值4,不区分大小写
position(str1 in str2);
select position('Sql' in 'mysql');
instr(str2,str1);
select instr('mysql','Sql');
返回指定位置的字符串:
elt(n,str1,str2...)返回第n个字符串
select elt(2,'str','mysql','sql');
从现有字符串中截取子字符串:
left(str,num);//从左到右截取
right(str,num);//从右到左截取
select left('mysql',2);
select right('mysql',3);
截取指定位置和长度的字符串:
substring(str,num,len);//从第num个位置截取len个
mid(str,num,len);
select substring('istring',5,3);
去除字符串首尾空格:
ltrim(str); //去掉开始处空格
rtrim(str); //去掉结束处空格
trim(str); //去掉首尾空格
替换字符串:
insert(str,pos,len,newstr);//newstr的长度可以超出len
select insert('mysql',2,3,'strdf');
replace(str,substr,newstr);//将str中的substr字符串用newstr来替换
select replace('mysql',‘y’,'strdf');
数值函数:
获取随机数:
rand()和rand(x)来获取0-1之间的随机数,前者每次或取的随机数不同,后者相同x每次获取的随机数相同。
得到整数:
ceil()、 floor()
截取数值:
truncate(x,y) //y表示为x保留多少位小数
四舍五入:
round()、round(x,y) //y也是保留的小数位数
常用的日期时间函数:

第九部分:存储过程和函数的操作
数据库的存储过程和函数:可以理解为一条或者多条sql语句的集合,经编译创建保存在数据库中,需要的时候调用执行。
存储过程:就是预编译的代码块。
存储过程的好处:
- 数据库执行动作时,是先编译后执行的,而存储过程是一个编译过的代码块,所以存储过程的执行效率比T-sql更高。
- 一个存储过程替代大量T_SQL语句 ,可以降低网络通信量,提高通信速率。
- 一定程度上确保数据安全。
存储过程和函数非常接近,主要区别就是函数必须要有返回值,然后函数的参数只有IN类型,而存储过程有IN、OUT、INOUT三种类型。IN是调用者向过程里传参,OUT是由过程向外面输出参数。
存储过程和函数的优点:
允许标准组件式编程,提高sql语句的重用性、可移植性、共享性;可以实现较快的执行速度。缺点是:编写复杂;需要创建这些数据库对象的权限。
存储过程和函数的区别:
- 本质上没有区别,但是函数只能返回一个变量,存储过程可以返回多个变量。
- 函数可以嵌在sql中使用,可以在select中调用,而存储过程不行。
- 函数的限制比较多,存储过程的限制稍微少一些。
- 对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
创建存储过程:create procedure name(parameter[]) [characteristic...]

创建函数:

声明变量用declare name type;
赋值变量用set name=
数据库中相当于指针或者数组下标的是:游标
对游标的操作有:declare,open,fetch,close
第十部分:事务(transaction)、锁
数据库中的事务(transanction)是什么?
事务是并发控制的基本单位,要么完全执行,要么完全不执行。
举个例子加深一下理解:同一个银行转账,A转1000块钱给B,这里存在两个操作,一个是A账户扣款1000元,另一个操作是B账户增加1000元,两者就构成了转账这个事务。
两个操作都成功,A账户扣款1000元,B账户增加1000元,事务成功;两个操作都失败,A账户和B账户金额都没变,事务失败。
为了保证数据库记录的一致性,引入了事务。
事务有四个特性:原子性(事务不可再分割,要么都执行,要么都不执行)、隔离性、一致性(事务开启之前和完毕之后,数据库的完整性没有被破坏,比如ab账户的总额事务前后保持不变)、持久性(事务一旦提交,对数据库的修改就是永久的)。
什么是乐观锁、悲观锁?
这是并发控制中采取的技术手段。
乐观锁:假定不会发生并发冲突,只在提交操作时检查是否破坏数据的完整性。
悲观锁:假定一定会发生并发冲突,屏蔽一切可能会破坏数据完整性的操作。
什么是并发控制?
:是确保多个事务同时存取数据库中同一数据时不破坏事务的原子性、隔离性和一致性。
InnoDB支持事务主要是通过undo和redo日志来实现的。
redo日志: 是将事务日志写到日志文件中。当数据库进行更新操作时,首先将redo日志写入到日志缓冲区,当客户端执行commit提交命令时,日志缓冲区的内容被刷新到磁盘。
undo日志: 是用于事务异常时的数据回滚,具体就是复制事务前的数据库内容到undo缓冲区,然后在合适的时间将内容刷新到磁盘。
begin开始事务,commit结束事务,rollback回滚事务。
begin; //开启事务
update test set name='lily' where id=1; //更新记录,但是此时数据库中的数据记录还并没有修改
commit; //提交事务,提交之后数据库中的记录才被修改了,这是具有持久性的修改
rollback; //回滚事务,但是回滚得在显式执行commit之前才能回滚。
事务隔离级别分为四种:
Read-uncommited:(可读取未提交内容)
在这个隔离级别,所有事务都可以看到其他未提交事务的执行结果。这个级别很少用到,读取未提交的数据称为脏读。
:比如同时开启两个事务,事务a读到了事务b更新但未提交的数据,但是随后事务b就回滚了,这样事务a就出现了脏读的现象。
Read-commited:(可读取已提交内容)
这是大多数数据库系统的默认隔离级别,只能看见提交事务所做的改变,提交之前的都是不可见的。
幻读:是指多个事务同时对同一个表进行操作时发生的一种现象。
比如有两个事务同时对一个表操作,事务a是对表的全部行进行一个修改,此时事务b又往表中插入了一行新数据,此时操作事务a的用户就会发现表中又出现没有修改的数据行了,这样就叫做幻读。
这种隔离级别也支持所谓的不可重复读。
:因为同一事务的其他实例可能会在重复查询的期间有新的数据提交,所以多次查询很可能会返回不同的结果。
Repetable-read:(可重复读)mysql
这是mysql的默认事务隔离级别。
这个隔离级别可以确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。
这个保证是由InnoDB的MVCC机制来实现的:
为每个数据行增加了两个隐含值,隐含值记录了每一行的创建时间、删除时间,这里说的时间是指的系统版本号,相当于事务的id。每一次开始一个新事务时版本号都会自动加1,每个事务都会保存开始时的版本号。所以每个查询是根据事务的版本号来查询的,查询出来的就是同样的结果。
Serializable:(可串行化)
这是最高的隔离级别,通过强制事务排序,使之不可能相互冲突,解决。如果一个事务,使用了SERIALIZABLE——可串行化隔离级别时,在这个事务没有被提交之前,其他的事务,只能等到当前操作完成之后,才能进行操作,这样会非常耗时,而且,影响数据库的性能,通常情况下,不会使用这种隔离级别。
InnoDB锁机制:
锁机制是为了解决数据库并发控制问题,同一时刻对同一个表做更新或者查询操作,这种情况为了保证数据的一致性,产生了锁。
锁有共享锁、排他锁、意向锁。
共享锁:代号是S,锁粒度是行或者多个行(元组)。一个事务获得共享锁之后,可以对锁定范围内的数据执行读操作。
排他锁:代号是X,锁粒度是行或者是多个行(元组)。一个事务获得排他锁之后,可以对锁定范围内的数据执行写操作。
<如果事务A获取了一个元组的共享锁,事务B还可以获取这个元组的共享锁,但是不能获取这个元组的排他锁,必须等事务A释放共享锁之后。也就是说,
读写操作不能同时进行!!读可以多个事务同时读,写只能有一个事务在写。
如果事务A获取了一个元组的排他锁,那么事务B既不能获取这个元组的共享锁,也不能获取它的排他锁,必须等事务A释放掉排他锁之后。>
意向锁:是一种表锁,锁粒度是整张表,分为意向共享锁IS和意向排他锁IX。
意向共享锁表示一个事务有意给数据上共享锁或者排他锁。
锁与锁之间要么是相容的,要么是互斥的。
锁a与锁b相容是指:操作同一组数据时,事务A获取了锁a,另一个事务B还可以获取锁b。
锁a与锁b互斥是指:操作同一组数据时,事务A获取了锁a,那么另一个事务B在事务A释放锁a之前是无法获得锁b的。
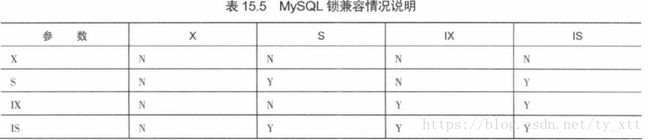
锁粒度指的就是锁住的数据量。
锁粒度是平衡高并发响应和系统性能两方面而引出的概念。为尽可能提高数据库的并发量,每次锁定的数据越小越好,这样会导致耗费的系统资源越多,性能下降。
锁粒度分为表锁和行锁。
表锁的资源开销最小,允许的并发量也是最小的锁机制。当要写入数据时,整个表记录被锁,其他读、写动作一律等待。MyISAM使用这种锁机制。
行锁可以支持最大的并发,InnoDB使用这个锁机制。
当开启一个事务时,InnoDB会在更新的记录上自动加个行级锁,此时其他事务是不可以更新这条被锁定的记录的,但是可以更新没被锁定的同一个表中的其他记录。