从零使用强化学习训练AI玩儿游戏(7)——使用DQN(TensorFlow)
上一篇我们使用了DQN来玩简单的走迷宫游戏,但是DQN能胜任比走迷宫游戏更复杂的游戏。这一篇我们就从GYM中选一款游戏来通过训练神经网络,让他自己玩。
我们选择CartPole这款游戏,在之前的Q-learning中我们有用过这款游戏,在Q-learning上效果非常的差。
由于CartPole这个游戏的reward是只要杆子是立起来的,他reward就是1,失败就是0,显然这个reward对于连续性变量是不可以接受的,所以我们通过observation修改这个值。点击pycharm右上角的搜索符号搜索CartPole进入他环境的源代码中,再进入step函数,看到里面返回值state的定义
x, x_dot, theta, theta_dot = state通过这四个值定义新的reward是
x, x_dot, theta, theta_dot = observation_
r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
reward = r1 + r2主程序是:
import gym
from RL_brain import DeepQNetwork
env = gym.make('CartPole-v0')
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = DeepQNetwork(n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],
learning_rate=0.01, e_greedy=0.9,
replace_target_iter=100, memory_size=2000,
e_greedy_increment=0.001,)
total_steps = 0
for i_episode in range(100):
observation = env.reset()
ep_r = 0
while True:
env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
# theta越小,越靠近中心,奖励应该越大
x, x_dot, theta, theta_dot = observation_
r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
reward = r1 + r2
RL.store_transition(observation, action, reward, observation_)
ep_r += reward
if total_steps > 1000:
RL.learn()
if done:
print('episode: ', i_episode,
'ep_r: ', round(ep_r, 2),
' epsilon: ', round(RL.epsilon, 2))
break
observation = observation_
total_steps += 1
RL.plot_cost()因为这个游戏的观测值只有四个,输出值也只有一个,所以不需要太大的神经网络,还是用之前单细胞神经网络就行了代码在上一篇的最后。

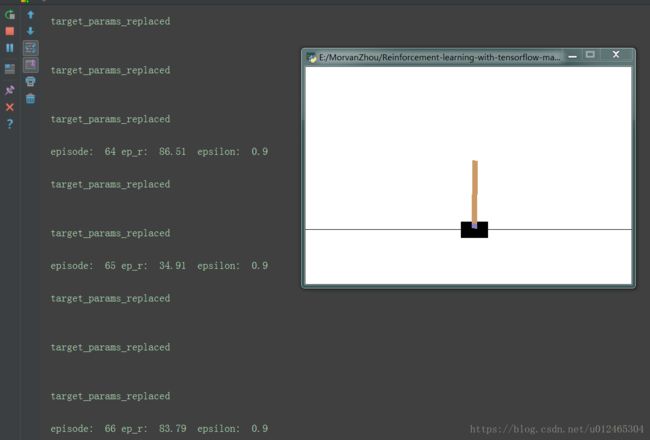
在非常短的训练时间内我们就能很明显的看出训练效果,刚开始基本上没走几步就会掉下去,直到后来能坚持83.79秒,甚至到最后一直不掉下去。我们再返回去看一下Q-learning的表现效果,即使运算几十分钟仍然是立不起来的。
DQN的cost值如下图所示,只要参数调整的好整体是趋于下降的,但是由于随机性,和DQN的探索总是会有新的东西出来,所以有的时候会有突变,上下波动也比较大。

下一篇我们就要使用Keras搭建一个更复杂的神经网络,来玩一个更复杂的游戏。