大白话5分钟带你走进人工智能-神经网络之tensorflow的前世今生和DAG原理图解
神经网络是一门重要的机器学习技术。它是目前最为火热的研究方向--深度学习的基础。学习神经网络不仅可以让你掌握一门强大的机器学习方法,同时也可以更好地帮助你理解深度学习技术。而 Tensorflow 是深度学习的重要语言,DAG 原理图有助于更好的理解 Tensorflow 的设计思想。
我们的愿景是打造全网 AI 最通俗博客,赠人玫瑰,手有余香,在人工智能前行的路上一起前行。以通俗简介的方式,让每一位热爱着深入其中。
在本 Chat 中,你将收获如下内容:
- Tensorflow 框架简介
- 安装 Tensorflow
- 核心概念
- 代码实例和详细解释
- 拓扑图之有向无环图 DAG
- 其他深度学习框架详细描述
- Caffe 框架
- Theano 框架
- Keras 框架
Tensorflow 框架简介
Tensorflow 由 Google Brain 谷歌大脑开源出来的,在 2015 年 11 月在 GitHub 上开源,2016 年是正式版,2017 年出了 1.0 版本,趋于稳定。谷歌希望让优秀的工具得到更多的去使用,所以它开源了,从整体上提高深度学习的效率。在 Tensorflow 没有出来之前,有很多做深度学习的框架,比如 caffe,CNTK,Theano,公司里更多的用 Tensorflow。caffe 在图像识别领域也会用。Theano 用的很少,Tensorflow 就是基于 Theano。中国的百度深度学习 PaddlePaddle 也比较好,因为微软、谷歌、百度它们都有一个搜索引擎,每天用户访问量非常大,可以拿到用户海量的数据,就可以来训练更多的模型。
Tensorflow 发展非常快,它是适合所有人的开放源代码机器学习框架。是一个开放源代码软件库,用于进行高性能数值计算,借助其灵活的架构,然后用户可以轻松的将计算工作部署在多个平台(CPU,GPU,TPU)。**GPU 是显卡,有两个厂商,一个是 N 卡,一个是 AMD,其中 AMD 的显卡是不支持 Tensorflow 运行在 GPU 上的,TPU 是谷歌自己出的一个硬件,它可以更好的跑深度学习。Tensorflow 可以部署在多数平台里面去,一般是用 CPU,GPU,TPU 去训练,也可以把这个模型训练好之后,把它扔到手机端,让手机端去加载这个模型,进行一些预测,比如说图像识别等等。它的兼容性是非常好的。
Tensorflow 可为机器学习和深度学习提供强有力支持。Tensorflow 虽然是一个专门做深度学习的,但是它来做机器学习也非常 easy,而且它还在不断的封装一些库,一些机器学习的方法、算法,它发展的非常快。所以未来你只会一套 Tensorflow,你就可以即处理机器学习,又处理深度学习。并且其灵活的数值计算核心广泛应用于其它科学领域,比如在 Python 里面的一些数值计算,很多时候会用 NumPy,Tensorflow 里面也有一些 API 它可以取代 NumPy。
当下 Tensorflow 是杀出重围的,在关注度,用户数上都占据绝对优势,有一统天下之势。因为 Tensorflow 是一个开源项目,只有更多的高手贡献相关的开源代码,这个社区才会变得越来越好,所以 contributor 数量是至关重要的,也就意味着 Tensorflow 的版本会更新得非常快。
另外谷歌的在业界的号召力确实很强大,所以很多人相信 Tensorflow 非常好,谷歌在去年出了一个东西叫做 AlphaGo,下围棋很厉害,同时开源了 Tensorflow,说 AlphaGo 是基于 Tensorflow 开发出来的,给 Tensorflow 做一个大的广告。AlphaGo 是谷歌收购的,之前是英国的一个公司,开源出的一个项目,然后谷歌把公司给收购了。其实很多公司都会做这种事情,之前我去一个公司做企业分享的时候,跟那里面的部门老大,他很厉害,会做很多人工智能的摄像头,包括图像识别,语音识别,视频对话,视频加密等等,原来在阿里,后来自己出来开了一公司,做智能摄像头,然后干得不错,让一个知名公司给收购了。
Tensorflow 是一个相对高阶的机器学习库,它可以很方便的让用户去设计神经网络的结构,而不必为了追求高效率而亲自写 C++或 CUDA 代码。如果在 Tensorflow 里面去做深度学习,并且有一些时间,你可以去研究 C++或 CUDA 代码,因为有些公司在面试的时候,它需要有些人去写 C++或 CUDA 代码,为什么?因为同样一份代码用 C++或 CUDA 代码来写,执行效率会稍微的高一些,它少了 python 里面解释和翻译的过程,它的代码跑起来会更快。
Tensorflow 和 Theano 一样都支持自动求导,这件事情很重要,Tensorflow 是基于 Theano 的,Theano 带的功能叫自动求导。如果这个框架没有带自动求导的功能,在做机器学习迭代过程当中,为了去调整 w,首先需要把梯度求出来,求梯度公式就得自己实现。如果很多用户对公式推导不太熟悉的话,或者推导错的话,代码就错了。那对于 Tensorflow 来说,就不要自己去实现了,直接搞到 Loss 损失函数是什么,它自动把偏导求出来,不需要再通过反向传播,一步步的求解梯度。
Tensorflow 另外一个重要的特点,就是它灵活的移植性,它可以在 cpu 上面或 gpu 上面跑,同样的代码也可以在移动设备上面来执行。但是可以把执行好的模型加载到里面去 predict 预测。因为其核心的代码和 Caffe 一样是用 C++编写的,它也可以让手机这种内存和 CPU 资源都紧张的设备可以来运行复杂的模型。所以 Tensorflow 有 C++接口,也有 python、Go、Java 接口,只不过 python 用的更多一些。
Tensorflow 里面也内置有 tf.learn 和 TF.slim 等上层组件,可以帮助快速的设计新网络。比如 tf.learn 里面就封装了机器学习的一些算法;TF.slim 就是一个组件,可以很好的把之前别人训练的模型给读进来。这样的话你就可以更快速的调机器学习的库,或者用别人的模型,在别人模型基础上设计新网络。并且它兼容 Scikit-learn 里面 estimator 接口,可以很方便实现 Scikit-learn 里面的 evaluate、grid search、cross validation 功能,都可以很好的兼容。
Tensorflow 不只局限于神经网络,只要是数据流式图支持的自由表达的算法表达,Tensorflow 都可以来实现。
Tensorflow 还有强大的可视化的组件叫 TensorBoard,有 TensorBoard 之后,就可以把你写代码非常清晰的看到有效图,可以看到它的流程,包括它实时运算的时候,它怎么跑的,整个都可以通过它进行监控。它能可视化网络结构和训练过程,对于观察复杂的网络结构和监控长时间、大规模训练很有帮助。
安装 Tensorflow
如果安装在 windows 里,32 位,64 位都可以。
![]()
关于 CPU 版本安装,使用 pip 安装。 用完这个代码之后就可以跑了。
![]() 如果显卡是英伟达的,可以选择安装 GPU。如果显卡不是很旧的话,可以安装 CUDA 9.0 版本的。然后再安装 cuDNN,DNN 是深度神经网络,它是一个小的包,它里面会有 dll 的一些东西,可以整合 CUDA 和底层的系统。
如果显卡是英伟达的,可以选择安装 GPU。如果显卡不是很旧的话,可以安装 CUDA 9.0 版本的。然后再安装 cuDNN,DNN 是深度神经网络,它是一个小的包,它里面会有 dll 的一些东西,可以整合 CUDA 和底层的系统。
GitHub 网址:github.com/tensorflow/tensorflow
模型仓库网址: github.com/tensorflow/models
深度学习有很多经典的模型,它不是靠公司那点数据就能训练好得,是别人通过海量的数据训练完之后,把这个模型开源出来了,很多公司就会拿着别人的模型,然后再来修改,踩着别人的肩膀再来进行训练。相当于别人的模型作为你们 w 的初始值。
如果没有别人的模型,一般初值都是随机的,如果别人开源一些模型之后,我们就可以把别的模型作为初始值,再来进行训练,速度会快很多。比如 resnet 残差网络,就是一个经典的模型;比如 keras_application,mnist 等一些模型。
推荐也可以用深度学习来做。这个里有一些比较经典的模型,我们可以去使用。
除了执行深度学习算法,Tensorflow 还可以用来实现很多其它算法,比如可以去实现线性回归,逻辑回归,或者是随机森林等。很多算法都有封装。
核心概念
TensorFlow 中的计算可以表示为一个有向图(DirectedGraph),或者称计算图(ComputationGraph),其实就是构建一个从前往后,正向传播的一个逻辑,称为构建一个计算图。比如如下的一个计算图:
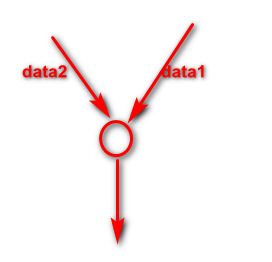
其中每一个运算操作(operation)(图中的圆圈)将作为一个节点(node),在计算图里面,每个节点就是一个逻辑,一个 function 代码,比如相乘还是相加。这里的每个节点可以把它看成是一个神经元,它可以有很多的输入和输出。每一个节点描述了一种运算操作。
计算图描述数据的计算流程,也负责维护和更新状态。其实做机器学习、做人工智能要的模型最终就是一堆参数,这些参数本质上就是 w1 到 wn,所以维护和更新的状态,就是维护这些 w,不断的迭代更新。
用户通过 python,c++,go,Java 语言设计这个这个数据计算的有向图。计算图中的边,里面流动的数据称为叫张量,data1,data2,就是流动在边(图中箭头)里面的数据。张量就是多维数组,因为 x 训练集里面有很多个维度,是一个 m 行 n 列的 x 数据集,所以它就是一个多维数组。数组在整个计算图里面流动起来,所以得名 Tensorflow,在流动的过程中,数据就不断的变化,然后循环往复不断地流动,就不断的调整连线所对应的权重值。
代码实例和详细解释
看下一般 tensorflow 的流程
import tensorflow as tf b = tf.Variable(tf.zeros([100])) W = tf.Variable(tf.random_uniform([784,100], -1, 1)) x = tf.placeholder(name="x") relu = tf.nn.relu(tf.matmul(W, x) + b) cost = [..] sess = tf.Session() for step in range(0, 10): input = …construct 100-D input array… result = sess.run(cost, feed_dict={x: input}) print(step, result)解释下代码:
import tensorflow as tf如果想用 Tensorflow 这个框架,首先需要把它导进来,一般情况给 Tensorflow 起个别名叫 tf。
b = tf.Variable(tf.zeros([100]))因为我们的算法是y=ax+b,其中 b 代表截距 bias,bias 有多少个,取决于这一层有多少神经元。tf.zeros 和机器学习的代码非常类似,np.zeros 就是来一个数组,里面有一堆 0。
tf.zeros[100]相当于创建长度为 100,里面每个位置都为 0 的一个向量。然后把它作为 tf.Varialbe 变量,为什么要把 bias 变成变量?因为在迭代过程中要反复调整它。
W = tf.Variable(tf.random_uniform([784,100], -1, 1))w=tf.Varialbe,我们想要得到 w 矩阵,它也是一个变量,因为在每次迭代过程中要去调里面的每个值。它是 784 行 100 列,就意味着它前一层有 784 个神经元,后一层有 100 个神经元,这两层之间的 w 矩阵就是 784 行 100 列。
这里有 100 个神经元,所以截距 bias 里面写的是 100,相当于每个线上都有一个单独的 bias,都是 1。
w 最开始需要随机,random_uniform,是均匀分布,意思是每随机其中一个数的时候,在-1 到 1 之间,它的概率都是相同的,叫做均匀分布。根据均匀分布来随机取值,w 矩阵是 784 行 100 列,它有 78400 个数据需要随机出来,里面的每一个数是通过随机得到的,通过 uniform 均匀分布的方式来得到。
如果把它变成正态分布,我们每一次取-1 到+1 到一之间值的时候,0 概率最大。
x = tf.placeholder(name="x")x 是谁我们不知道,因为Tensorflow 主要分为两部分,第一步是来构建一个计算图;第二步是迭代开始算 w 或者 bias 截距。所以在构建计算图的时候,还不知道 x 是谁,也不知道 y 是谁,所以 x=tf.placeholder(name="x")意思是先占个位置。
relu = tf.nn.relu(tf.matmul(W, x) + b)接着要去构建正向传播,计算图。我们看下这里的示意图:
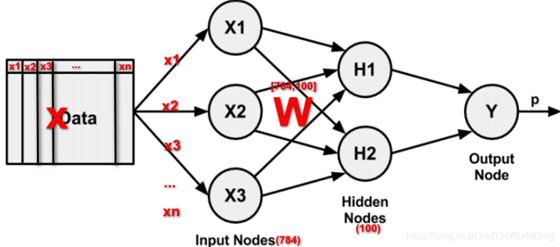
W 构建为 784*100,意思是我们在构建一个输入层和隐藏层之间的 w 矩阵,相当于输入层有 784 个神经元(x1 到 xn 的个数),下一层隐藏层,有 100 个神经元,中间的 w 矩阵,就是 784 行 100 列,所以这样写代码的话,就意味知道前面一层有多少神经元,后面一层有多少神经元。
matmul(W,X)是 w 矩阵和 x 矩阵相乘,就是对应的位置相乘相加。x 矩阵是样本集,当把第一行抽出来的时候,第一行 x1 到 xn 共 784 个数据也就是 1 行 784 列即[1,784]代入到网络拓扑里面,x 传进去就会和 w784 行 100 列即[784,100],输出层得到的是 1 行 100 列的结果。这是对一条样本进行预测,输出的就是这条样本的预测值。也可以对 m 个样本进行预测,输出就是 m 个样本的预算值。相当于 x 是 m*784,w 是 784×100,输出层的结果是 m*100。
前面 b,w,x 就作为输入。+b,b 是 100 个值,就是让输出的结果 m 行 100 列里面的每一个值分别加上 bias 截距。最后形状没变,还是 m 行 100 列。接着再去经过 tf.nn.relu,relu 是 max(0,z),但在 Tensorflow 里面不需要去实现这个公式,它会封好 tf.nn.relu 里面。
到这里为止,完成了一个神经元里面的加和。前面有 784 个输入,784 个输入分别去和 w 矩阵相乘相加;每个神经元身上还有一个截距,最后再把截距加上。因为最后还需要一个非线性的 function 才能完成,所以再接一个 tf.nn.relu。
cost = [..]有了最终的结果的输出,就可以算 Cost 的损失。
前面这一部分在做构建计算图。
下面一部分
sess = tf.Session()tf.session 相当于是来一个会话的上下文,相当于有一个 Tensorflow 环境。
for step in range(0, 10): input = …construct 100-D input array… result = sess.run(cost, feed_dict={x: input}) print(step, result)For…in…是迭代,range(0,10)会迭代十次,在每一次迭代里面 sess.run,在每一次迭代的时候,计算一下 cost 损失,最后把损失结果打印输出一下。
Tensorflow 的流程就是先来构建计算图,然后把数据传进来,算到最后的损失。
拓扑图之有向无环图 DAG
在 tensorflow 里最主要是构建一个有向图,下面这张图是一个有向无环图,解释了上面的代码。

解释下:先通过 tf.bariable 定义一个 b,然后 tf.bariable 定义一个 w,接着 tf.placeholder 定义一个 x,它们都是tensor,就是有向图里面的 b,w,x。然后把这些数据进行一个正向传播,用 tf.matmul 把 w 和 x 进行一个操作,Matmul 是一个操作节点。
把 w,x 拿过来,它在 Matmul 里面进行相应计算,然后进入下一个节点 add。把 b 截距拿过来,把它的结果进一步累加。
这个无环图里 relu 对应着代码 tf.nn.relu,relu 得到的结果,再经过其它的层次的传递,如果后面还有一些其它的神经网络层次,算出 Cost 就是最后一个节点。
每一个代码在 tensorflow 背后都会变成一个图,在构建图的过程当中,没有把数据传进来。它只是在前面 b 和 w 初始化了之后,x 只是用来占个位置,并没有把真正的数据传给它,所以前面只是在构建正向传播的一个流程,并没有真正传数据。
如果说的更严谨一点,到 b,w 的 tf.bariable 为止时候并没有去初始化。只有用 sess.run(w.initialize)时才会真正地把调用的一些函数进行初始化。
如果创建了 session,它就会把 x 读进来,把 w,b 初始化,然后再来进行有向无环图的计算,这样一个传播。
当我们调用 sess.run[cost]的时候,它为了去计算出来 cost,一定要一路追溯回去找 b,w,x 才能算出 relu,然后把 relu 放进来,才能去算出 cost。所以如果为了去算出 cost,前面没有对 b,w,x 进行初始化,它没法往下去执行,就会报错。
其他深度学习框架详细描述
其它深度学习的框架还有很多,其中包括TensorFlow、Caffe、Keras、CNTK、Torch7、MXNet、Leaf、Theano、DeepLearning4、Lasagne、Neon。谷歌的 caffe 开源的,做卷积神经网络的框架;Keras 基于 Tensorflow、Theano 以及 CNTK 更高一层又更深的封装的框架,就是 Tensorflow100 行干的事情,Keras 可能 10 行就完了,更加简化代码。但是学好了 Tensorflow,才能明白它真正是干什么,因为开始它并没有底层的实现,它是基于 CNTK、Tensorflow、Theano 的一个框架,所以你的环境里面必须得有 CNTK、Tensorflow、Theano,然后再去装 Keras 这个模块才能去用。
CNTK 是微软的,Torch7 也是,MXnet 是亚马逊的一个深度学习的框架,它们跟 Tensorflow 都非常的类似。
各大主流框架基本都支持 Python,目前 python 在科学计算和数据挖掘领域可以说是独领风骚。就是在 AI 人工智能这个领域,Python 应用是最多的,未来一定也是最多的。因为 java 干一切首先得创造一个类,然后去 new 一个对象,然后才能去调用这个类里面定义的一些方法,很麻烦。我们做人工智能的时候,可能用不到类和对象这些东西,很多时候函数编程就能解决。所以 Python 函数编程就用的会更多一些,而且 Python 语法更加简洁,它有更多非常方便的 module 模块,不需要自己开发,直接调用就可以。
而且 Python 可以非常方便地做一个项目,而 R 语言它也是做数据分析,做统计学,也可以做机器学习,R 语言它就很难开发成一个 web 项目,很难去做数据库的连接,很难去做爬虫等等。Python 的生态体系比较完善。
在数据挖掘工具链上,Python 有 Numpy,Scipy,Pandas,Scikit-learn,XGBoost 等组件,这些东西在 tensorflow 里面一样可以拿来用,因为它都是 Python 执行的环境。
6.1 Caffe 框架:
Convolutional Architecture for Fast Feature Embedding。
一个被广泛使用的开源深度学习框架,由伯克利视觉中心进行维护
特点一:容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络 。
特点二:训练速度快,能够训练 state-of-the-art 的模型与大规模的数据 。
特点三:组件模块化,可以方便地拓展到新地模型和学习任务上 。
Caffe 核心概念是 Layer,每一个神经网络地模块都是一个 Layer。Layer 接收输入数据,同时经过内部计算产生输出数据。设计网络,需要把各个 Layer 拼接在一起构成完整地网络(通过写 protobuf 配置文件定义)。
比如卷积 Layer,它的输入就是图片全部像素点,内部进行的操作是各种像素的值与 Layer 参数的 convolution 操作,最后输出的是所有卷积核 filter 的结果。
每一个 Layer 需要定义两种运算,一种是正向 forward 运算,从输入数据计算出输出结果。Caffe 的配置文件是一个类似 JSON 的 prototxt 文件,其中使用许多顺序连接的 Layer 来描述神经网络结构,在 prototxt 文件中设计网络结构比较受限,没有像 TensorFlow 或者 Keras 那样在 python 中设计网络结构方便、自由。
配置文件不能用编程方式调整超参数,也没有像 sklearn 那样好用的 estimator 可以方便进行交叉验证、超参数的 Grid Search。
Caffe 在 GPU 上性能很好,一个 GTX1080 训练 AlexNet 一天可以训练上百万张图片,但是目前仅支持单机多 GPU 训练,原生没有支持分布式训练,不过有 CaffeOnSpark,借助雅虎开源的技术结合 spark 分布式框架实现 Caffe 大规模分布式训练。
6.2 Theano 框架:
与 sklearn 一样,Theano 很好的整合了 Numpy ,因为 Theano 非常流行,有许多人写了高质量文档和教程,用户方便查找 Theano 的各种 FAQ,比如如何保持模型,如何运行模型等,不过它更多被当作一个研究工具,而不是当作产品来使用。
Theano 在单 GPU 上执行效率不错,性能和其他框架类似,但是运算时需要将用户的 python 代码转换成 CUDA 代码,再编译为二进制可执行文件,编译复杂模型时间非常久。
不过,Theano 在训练简单网络比如很浅的 MLP 时性能可以比 TensorFlow好,因为全部代码都是运行时编译,不需要像 TensorFlow 那样每次喂给 mini-batch 数据时候都得通过低效的 python 循环来现,Theano 是一个完全基于 Python 的符合计算库,不需要像 Caffe 一样为 Layer 写 C++或 CUDA 代码,用户定义各种运算,Theano 可以自动求导,省去了完全手工写神经网络反向传播的麻烦,也不需要像 Caffe 一样为 Layer 写 C++或者 CUDA 代码。
如果没有 Theano,可能根本不会出现这么多好的 python 深度学习框架,就如没有 python 的科学计算的基石 Numpy,就不会有 Scipy、Sklearn、SkImage,可以说 Theano 就是深度学习界的 Numpy,是其他各类 python 深度学习库的基石 。
但是直接使用 Theano 来设计大型的神经网络还是太繁琐了,用 Theano 实现 Google Inception 就像用 Numpy 实现一个支持向量机 SVM 。事实上,不需要总是从最基础的 tensor 粒度开始设计网络,而是从更上层的 Layer 粒度来设计网络。
6.3 Keras 框架:
Theano 派生出了大量基于它的深度学习库,包括一系列的上层封装,其中大名鼎鼎的 Keras 对神经网络抽象得非常合适,以致于可以随意切换执行计算得后端(目前同时支持 Theano 和 TensorFlow)。
Keras 比较适合在探索阶段快速地尝试各种网络结构,组件都是可插拔的模块,只需要将一个个组件,比如卷积层、激活函数连接起来,但是设计新的模块或者新的 Layer 就不太方便了。它是高度模块化、极简的神经网络库,用 python 实现,同时运行在 TensorFlow 和 Theano 上,意在让用户进行最快的原型试验,让想法变为结果的过程最短。
Theano 和 TensorFlow 的计算图支持更通用的计算,而 Keras 专精于深度学习 。
Theano 和 TensorFlow 更像深度学习领域的 Numpy,而 Keras 是深度学习的 sklearn。
神经网络、损失函数、优化器、初始化方法、激活函数、和正则化等模块都是可以自由组合的 Keras 中的模型都是在 python 中定义的,不需要 Caffe 和 CNTK 等需要额外的配置文件来定义模型。
通过编程方式调试模型结构和各种超参数,几行代码就可以实现一个 MLP,十几行代码实现一个 AlexNet,这在其它框架里面是不可能完成的任务 。
Keras 问题在于目前无法直接使用多 GPU,所有对大规模的数据处理速度没有其他支持多 GPU 和分布式的框架快。
阅读全文: http://gitbook.cn/gitchat/activity/5dac5735de298d4131c57e00
您还可以下载 CSDN 旗下精品原创内容社区 GitChat App ,阅读更多 GitChat 专享技术内容哦。
