从零开始写Python爬虫 --- 1.7 爬虫实践: 排行榜小说批量下载
从零开始写Python爬虫 --- 1.7 爬虫实践: 排行榜小说批量下载
本来只是准备做一个爬起点小说名字的爬虫,后来想了一下,为啥不顺便把小说的内容也爬下来呢?于是我就写了这个爬虫,他爬下了各类小说排行榜上的所有章节内容,并保存到本地。仔细想了一下,各种盗版小说阅读器,是不是就是这样做的呢?
目标分析:
首先来看看我们排行榜的地址:
http://www.qu.la/paihangbang/
我们的目的很明确:
找到各类排行旁的的每一部小说的名字,和在该网站的链接:
观察一下网页的结构:
我们很容易就能发现,每一个分类都是包裹在:
之中
这种调理清晰的网站,大大方便了我们爬虫的编写
小说标题和链接:
我们在刚才那个div里自己寻找:
<div class="index_toplist mright mbottom">
<div class="toptab" id="top_all_1">
<span>玄幻奇幻排行span><div>
<div class="topbooks" id="con_o1g_1" style="display: block;">
<ul>
<li><span class="hits">05-06span><span class="num">1.span><a href="/book/168/" title="择天记" target="_blank">择天记a>li>
<li><span class="hits">05-06span><span class="num">2.span><a href="/book/176/" title="大主宰" target="_blank">大主宰a>li>
<li><span class="hits">05-06span><span class="num">3.span><a href="/book/4140/" title="太古神王" target="_blank">太古神王a>li>
<li><span class="hits">05-06span><span class="num">4.span><a href="/book/5094/" title="雪鹰领主" target="_blank">雪鹰领主a>li>
<li><span class="hits">05-01span><span class="num">15.span><a href="/book/365/" title="武动乾坤" target="_blank">武动乾坤a>li>
ul>div>
发现所有的小说都是在一个个列表里,并且里面清晰的定义了:
标题:title = div.a['title']
链接:link = 'http://www.qu.la/' + div.a['href']
这样一来,我们只需要在当前页面找到所有小说的连接,并保存在列表就行了。
列表去重的小技巧:
信息的同学会发现,就算是不同类别的小说,也是会重复出现在排行榜的。
这样无形之间就会浪费我们很多资源,尤其是在面对爬大量网页的时候。
那么我们如何从抓取的url列表里去重呢?
刚学Python的小伙伴可能会去实现一个循环算法,来去重,
但是Python的强大之处就在于他可以通过及其优美的方式来解决很多问题,这里其实只要一行代码就能解决:
url_list = list(set(url_list))
这里我们调用了一个list的构造函数set:这样就能保证列表里没有重复的元素了。是不是很简单?
单个小说所有章节链接:
首先我们从前面获取到的小说url连接选取一个做实验:
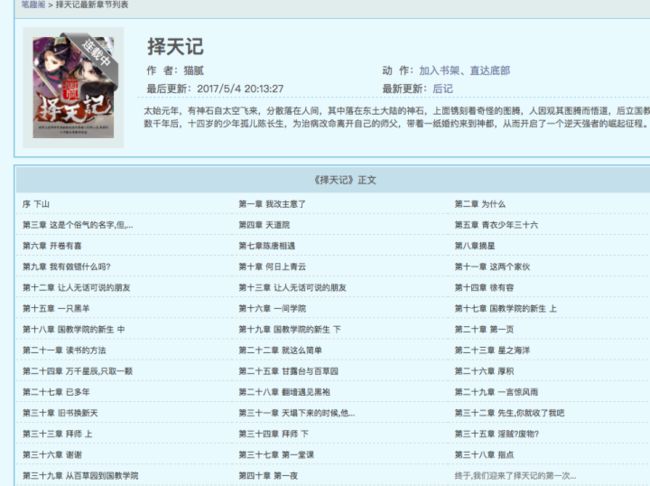
比如我最爱的择天记:
http://www.qu.la/book/168/
依然是无比清晰的网页结构,点个赞:
<div class="box_con">
<div id="list">
<dl><dt>《择天记》正文dt>
<dd> <a style="" href="/book/168/1748915.html">序 下山a>dd>
<dd> <a style="" href="/book/168/1748916.html">第一章 我改主意了a>dd>
<dd> <a style="" href="/book/168/1748917.html">第二章 为什么a>dd>
<dd> <a style="" href="/book/168/1748924.html">第九章 我有做错什么吗?a>dd>
div>
我们可以很容易的找到对应章节的连接:
这个代码是节选,不能直接用!后面会有说明
link='http://www.qu.la/' + url.a['href']
好的,这样我们就能把一篇小说的所有章节的链接爬下来了。
剩下最后一步:爬取文章内容:
文章内容的爬取:
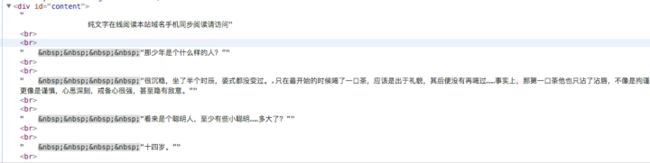
首先我们打开一章,并查看他的源代码:
我们能发现所有的正文内容,都保存在:
所有的章节名就更简单了:
第一章 我改主意了
那我们通过bs4库的各种标签的查找方法,就能很简单的找到啦
好了,让我们看看具体代码的实现:
代码的实现:
模块化,函数式编程是一个非常好的习惯,我们坚持把每一个独立的功能都写成函数,这样会使你的代码简单又可复用。
网页抓取头:
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status
# 我手动测试了编码。并设置好,这样有助于效率的提升
r.encoding = ('utr-8')
return r.text
except:
return "Someting Wrong!"
获取排行榜小说及其链接:
def get_content(url):
'''
爬取每一类型小说排行榜,
按顺序写入文件,
文件内容为 小说名字+小说链接
将内容保存到列表
并且返回一个装满url链接的列表
'''
url_list = []
html = get_html(url)
soup = bs4.BeautifulSoup(html, 'lxml')
# 由于小说排版的原因,历史类和完本类小说不在一个div里
category_list = soup.find_all('div', class_='index_toplist mright mbottom')
history_finished_list = soup.find_all(
'div', class_='index_toplist mbottom')
for cate in category_list:
name = cate.find('div', class_='toptab').span.string
with open('novel_list.csv', 'a+') as f:
f.write("\n小说种类:{} \n".format(name))
# 我们直接通过style属性来定位总排行榜
general_list = cate.find(style='display: block;')
# 找到全部的小说名字,发现他们全部都包含在li标签之中
book_list = general_list.find_all('li')
# 循环遍历出每一个小说的的名字,以及链接
for book in book_list:
link = 'http://www.qu.la/' + book.a['href']
title = book.a['title']
# 我们将所有文章的url地址保存在一个列表变量里
url_list.append(link)
# 这里使用a模式,防止清空文件
with open('novel_list.csv', 'a') as f:
f.write("小说名:{:<} \t 小说地址:{:<} \n".format(title, link))
for cate in history_finished_list:
name = cate.find('div', class_='toptab').span.string
with open('novel_list.csv', 'a') as f:
f.write("\n小说种类:{} \n".format(name))
general_list = cate.find(style='display: block;')
book_list = general_list.find_all('li')
for book in book_list:
link = 'http://www.qu.la/' + book.a['href']
title = book.a['title']
url_list.append(link)
with open('novel_list.csv', 'a') as f:
f.write("小说名:{:<} \t 小说地址:{:<} \n".format(title, link))
return url_list
获取单本小说的所有章节链接:
def get_txt_url(url):
'''
获取该小说每个章节的url地址:
并创建小说文件
'''
url_list = []
html = get_html(url)
soup = bs4.BeautifulSoup(html, 'lxml')
lista = soup.find_all('dd')
txt_name = soup.find('h1').text
with open('/Users/ehco/Documents/codestuff/Python-crawler/小说/{}.txt'.format(txt_name), "a+") as f:
f.write('小说标题:{} \n'.format(txt_name))
for url in lista:
url_list.append('http://www.qu.la/' + url.a['href'])
return url_list, txt_name
获取单页文章的内容并保存到本地:
这里有个小技巧:
我们从网上趴下来的文件很多时候都是带着
之类的格式化标签,
我们可以通过一个简单的方法把他过滤掉:
html = get_html(url).replace('
', '\n')
我这里单单过滤了一种标签,并将其替换成‘\n’用于文章的换行,
具体怎么扩展,大家可以开动一下自己的脑袋啦
还有,我这里的代码是不能直接在你们的机子上用的,
因为在写入文件的时候,绝对目录不一样
def get_one_txt(url, txt_name):
'''
获取小说每个章节的文本
并写入到本地
'''
html = get_html(url).replace('
', '\n')
soup = bs4.BeautifulSoup(html, 'lxml')
try:
txt = soup.find('div', id='content').text.replace(
'chaptererror();', '')
title = soup.find('title').text
with open('/Users/ehco/Documents/codestuff/Python-crawler/小说/{}.txt'.format(txt_name), "a") as f:
f.write(title + '\n\n')
f.write(txt)
print('当前小说:{} 当前章节{} 已经下载完毕'.format(txt_name, title))
except:
print('someting wrong')
缺点:
本次爬虫写的这么顺利,更多的是因为爬的网站是没有反爬虫技术,以及文章分类清晰,结构优美。
但是,按照我们的这篇文的思路去爬取小说,
我大概计算了一下:
一篇文章需要:0.5s
一本小说(1000张左右):8.5分钟
全部排行榜(60本): 8.5小时!
是的! 时间太长了!
那么,这种单线程的爬虫,速度如何能提高呢?
自己洗个多线程模块?
其实还有更好的方式:下一个大的章节我们将一起学习Scrapy框架
学到那里的时候,我再把这里代码重构一边,
你会惊奇的发现,速度几十倍甚至几百倍的提高了!
这其实也是多线程的威力!
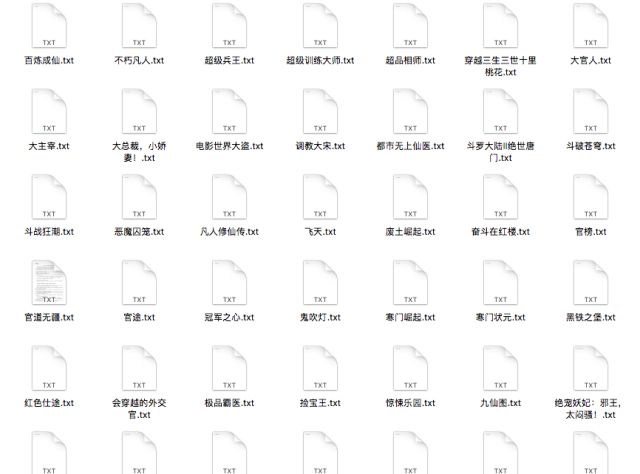
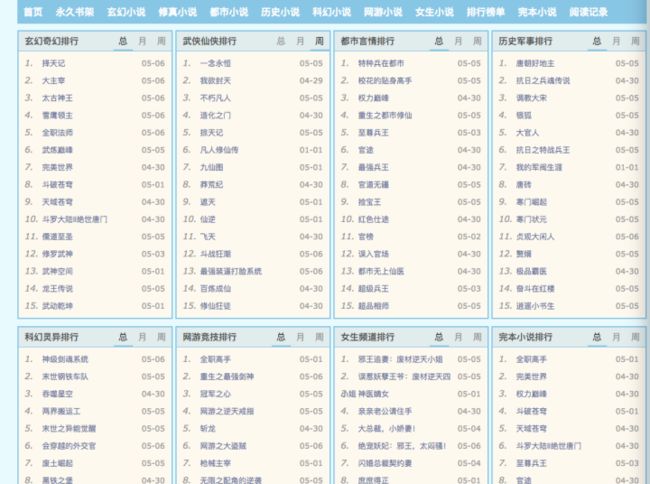
最后看一下结果吧:
排行榜结果:
小说结果:
学到这里是不是越来越喜欢爬虫这个神奇的东西了呢?
加油,更神奇的东西还在后面呢!
每天的学习记录都会 同步更新到:
微信公众号: findyourownway
知乎专栏:从零开始写Python爬虫 - 知乎专栏
blog : www.ehcoblog.ml
Github: Ehco1996/Python-crawler