利用python进行数据分析学习笔记1(数据加载,存储与文件格式)
读写文本格式的数据

将工作目录下的一个csv文件读入一个DataFrame中
df = pd.read_csv('examples/ex1.csv')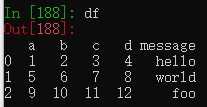
也可以是哟个read_table方法,并指定分隔符
pd.read_table('examples/ex1.csv',sep=',')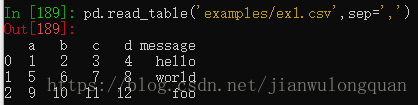
有些数据文件没有标题行,如果直接读取,会将第一行默认设置为标题行,传入header=None参数可以避免。
pd.read_csv('examples/ex2.csv') #将第一行设置为标题行
pd.read_csv('examples/ex2.csv',header=None)
也可以通过name参数手动设定标题行。
pd.read_csv('examples/ex2.csv',names=['a','b','c','d','message'])
通过index_col参数可以将源数据的某列设置为行索引列。
names = ['a','b','c','d','message']
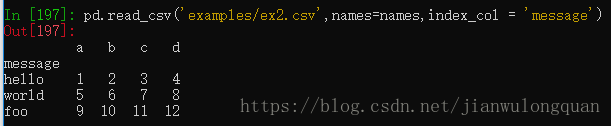
pd.read_csv('examples/ex2.csv',names=names,index_col = 'message')将names列表设置为标题行,index_col参数将message列设置为行索引列。
可以设置多个列为行索引列,做成层次化索引。
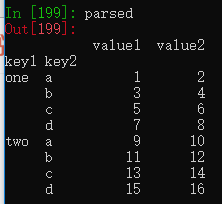
parsed = pd.read_csv('examples/csv_mindex.csv',index_col=['key1','key2'])设置key1和key2两层索引
有些表格可能不是用固定的分隔符来分隔字段的。
list(open('examples/ex3.txt'))
上面的文件中的数据使用数量不同的空白字符间隔开的,可以传入一个正则表达式作为分隔符。
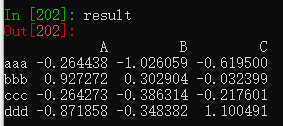
result = pd.read_table('examples/ex3.txt',sep='\s+')
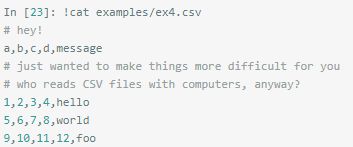
有时数据文件中不一定全都是数据。
比如这个数据文间的0、2、3行都是注释
通过skiprows参数可以跳过数据文件的指定行。
pd.read_csv('examples/ex4.csv',skiprows=[0,2,3])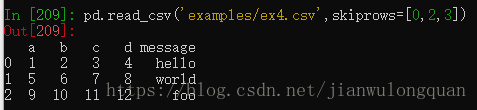
读取的数据文件中可能会存在缺失值。
result = pd.read_csv('examples/ex5.csv')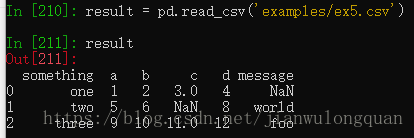
使用isnull方法可以返回一个布尔型DataFrame,缺失值会显示为True。

据说na_values参数可以设置不同的标记值来表示缺失值
result = pd.read_csv('examples/ex5.csv', na_values=['test'])
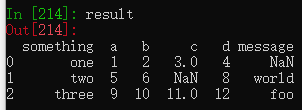
实际好像没什么卵用。
将各列的缺失值用不同的NA标记值。
sentinels = {'message': ['foo', 'NA'], 'something': ['two']}
pd.read_csv('examples/ex5.csv', na_values=sentinels)read_csv/read_table的一些参数介绍。


逐块读取文本文件
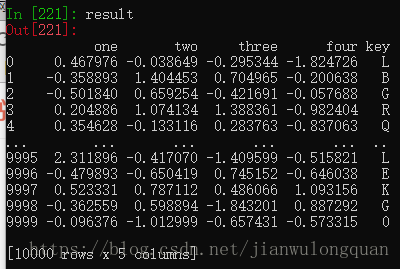
看大文件之前可以设置最大显示行数为10行。
pd.options.display.max_rows = 10
result = pd.read_csv('examples/ex6.csv')显示头五行和尾五行。
read_csv方法中可以设置nrows参数控制读取行数。
pd.read_csv('examples/ex6.csv',nrows=5) #只读五行
要逐块读取文件,设置chunksize参数。
chunker = pd.read_csv('examples/ex6.csv',chunksize=1000) #将10000行的数据文件拆分成10个1000行。
tot = pd.Series([]) #创建一个空Series
for piece in chunker: #迭代10个数据块
tot = tot.add(piece['key'].value_counts(),fill_value=0)
#对每个数据块进行分类求和,key列中有字母也有数字,求出它们的数量
tot = tot.sort_values(ascending=False) #降序排序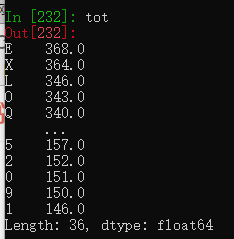
通过sort_index方法可以对索引进行排序
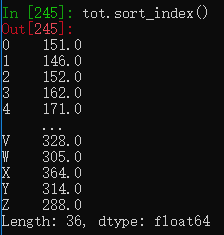
将数据写出到文本格式
通过to_csv方法,可以将数据写到一个用逗号分隔的文件中。
data = pd.read_csv('examples/ex5.csv') #读取文件数据
data.to_csv('examples/test.csv') #将文件数据转存到另外一个文件中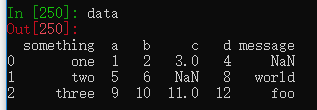
test = pd.read_csv('examples/test.csv')默认是逗号分隔,可以选择其他分隔符。
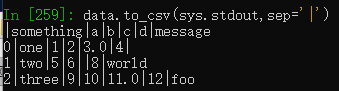
缺失值会用空字符串来表示,可以通过na_rep参数设置为其他标记值。
data.to_csv(sys.stdout,na_rep='test')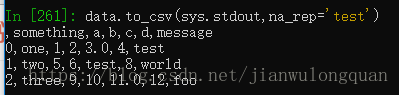
设置index和header参数可以不保存行索引或者列索引
data.to_csv(sys.stdout,index=False,header=False)
还可以设置columns参数选择写入部分数据。
data.to_csv(sys.stdout,index=False,columns=['a','b','c'])
Series也有to_csv方法
dates = pd.date_range('1/1/2000',periods=7) #创建一个日期序列
ts = pd.Series(np.arange(7),index=dates) #将日期序列作为Series的索引
ts.to_csv('examples/tseries.csv')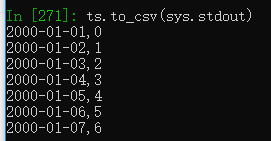
处理分隔符格式
有一个数据文件如下

对任何单字符分隔符文件,可直接用python内置的csv模块,将任意已打开的文件或文件型的对象传给csv.reader
import csv
f = open('examples/ex7.csv')
reader = csv.reader(f)打开指定文件,通过csv模块的reader方法将数据读取至一个变量中。
for line in reader:
print(line)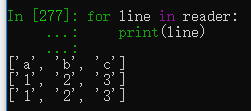
为得到一个格式合理的数据,先进行整理
with open('examples/ex7.csv') as f:
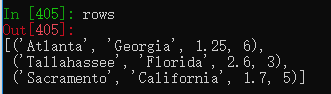
lines = list(csv.reader(f)) #读取文件到一个多行列表![]()
header,values = lines[0],lines[1:] #分标题行和数据行
构造字典
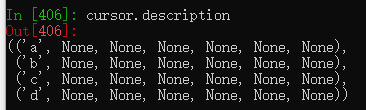
data_dic = {h:v for h,v in zip(header,zip(*values))}![]()
JSON数据
JSON数据示例

通过json.loads将str类型的数据转成dict。

通过json.dumps函数将dict转为str

将JSON对象转为DataFrame最简单的方法是向DataFrame构造器传入一个字典的列表,选取数据字段的子集。
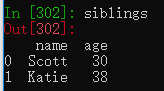
siblings = pd.DataFrame(result['siblings'],columns=['name','age'])将字典result中的siblings键对应的数据取出,并选择性地只取name和age列数据。
pd.read_json可以自动将json数据转换为Series或DataFrame

源文件是一个含有三个dict的list。
data = pd.read_json('examples/example.json')
将数据从pandas输出到JSON,可以用to_json方法
![]()
默认返回一个dict的字符串,以列索引为键,值是行索引和数值组成dict。

XML和HTML:Web信息收集
pandas.read_html默认条件下会搜索,解析