【Spark】5、决策树二元分类
本节使用决策树二元分类分析StumbleUpon数据集,预测网页是暂时性的(ephemeral)或是长青的(evergreen),并调校参数找出最佳参数组合,提高预测准确度。
StumbleUpon Evergreen大数据问题场景分析
StumbleUpon是一个个性化的搜索引擎,会按用户的兴趣和网页评分等记录推荐给你感兴趣的网页,有些网页是暂时性的,比如新闻,这些文章可能只是在某一段时间会对读者有意义,而有些则是长青的,读者会对这些文章有长久兴趣
我们这节的目标就是利用决策树二元分类机器学习,建立模型,并用这个模型来预测网页是属于暂时还是长青的,这属于简单的二元分类问题。
1、搜集数据
到这个网址去查看数据https://www.kaggle.com/c/stumbleupon/data
注:下载数据需要注册,注册时需要科学上网,才能加载到验证API
复制到项目目录
cp train.tsv ~/pythonwork/data
cp test.tsv ~/pythonwork/data
hadoop fs -put *.tsv /user/hduser/data
2、数据准备
必须将原始数据集提取特征字段与标签字段,建立训练所需的数据格式LabeledPoint,以随机方式按照8:1:1分为三个部分:训练数据集、验证数据集、测试数据集
训练数据集:trainData:以此数据训练模型
验证数据集:validationData:作为评估模型使用
测试数据集:testData:作为测试数据使用
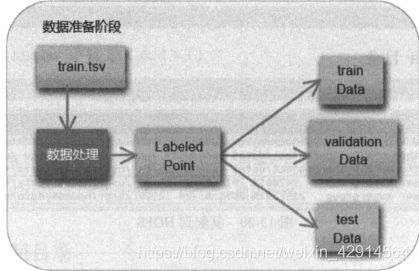
读取数据文件
以YARN模式启动pyspark
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop pyspark --master yarn --deploy-mode client
导入数据
rawDataWithHeader = sc.textFile("/user/hduser/stum/data/train.tsv")
注:文件夹需要读者自己创建
清理数据
从数据文件上看存在以下几个问题:
1、第一项数据是字段名
2、每一项数据以"\t"分隔字段
3、有些字段无数据,用?代替了
以下是解决步骤
删除第一项字段名
header = rawDataWithHeader.first()
rawData = rawDataWithHeader.filter(lambda x:x !=header)
删除双引号
rData = rawData.map(lambda x: x.replace("\"", ""))
获取每一行数据字段
lines = rData.map(lambda x: x.split("\t"))
提取特征字段
import numpy as np
def extract_features(field,categoriesMap,featureEnd):
# 提取分类特征字段
categoryIdx = categoriesMap[field[3]] # 网页分类转换为数值
categoryFeatures = np.zeros(len(categoriesMap)) # 初始化categoryFeatures
categoryFeatures[categoryIdx] = 1 # 设置List相对应的位置是1
# 提取数值字段
numericalFeatures=[convert_float(field) for field in field[4:featureEnd]]
# 返回“分类特征字段” + “数值特征字段”
return np.concatenate((categoryFeatures,numericalFeatures))
def convert_float(x):
# 判断是否为空值数据,如果是返回数值0,不是就转换为float
return (0 if x=="?" else float(x))

创建网页分类字典
categoriesMap = lines.map(lambda fields: fields[3]).distinct().zipWithIndex().collectAsMap()

提取label标签字段
def extract_label(field):
label=field[-1]
return float(label)
该函数传入field参数是单项数据,field[-1]获取最后一个字段,也就是label字段,最后返回float(label)转换为float之后的label
建立训练评估所需数据
创建LabeledPoint数据
from pyspark.mllib.regression import LabeledPoint
labelpointRDD = lines.map( lambda r:
LabeledPoint(
extract_label(r),
extract_features(r,categoriesMap,len(r) - 1)))

以随机方式将数据分为3部分并返回
(trainData,validationData,testData) = labelpointRDD.randomSplit([8,1,1])
将以上步骤封装为一个函数PrepareData:
def PrepareData(sc):
global Path
if sc.master[0:5] == "local":
Path = "file:/root/pythonwork/stum/"
else:
Path = "hdfs://master:9000/user/hduser/stum/"
print("Loading data.....")
rawDataWithHeader = sc.textFile(Path+"data/train.tsv")
header = rawDataWithHeader.first()
rawData = rawDataWithHeader.filter(lambda x:x !=header)
rData = rawData.map(lambda x: x.replace("\"", ""))
lines = rData.map(lambda x: x.split("\t"))
print("Total:"+str(lines.count())+" item")
categoriesMap = lines.map(lambda fields: fields[3]).distinct().zipWithIndex().collectAsMap()
labelpointRDD = lines.map( lambda r:
LabeledPoint(
extract_label(r),
extract_features(r,categoriesMap,len(r) - 1)))
(trainData,validationData,testData) = labelpointRDD.randomSplit([8,1,1])
return (trainData,validationData,testData,categoriesMap)
执行
(trainData,validationData,testData,categoriesMap) = PrepareData(sc)
数据暂存
trainData.persist()
validationData.persist()
testData.persist()
3、训练模型
from pyspark.mllib.tree import DecisionTree
model = DecisionTree.trainClassifier(\
trainData, numClasses=2, categoricalFeaturesInfo={},\
impurity="entropy",maxDepth=5,maxBins=5)

4、使用模型进行预测
建立模型后,可以使用此模型预测test.tsv数据。test.tsv只有feature,使用此特征字段预测网页是暂时的或是长青的
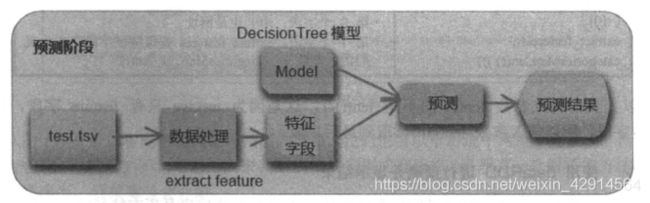
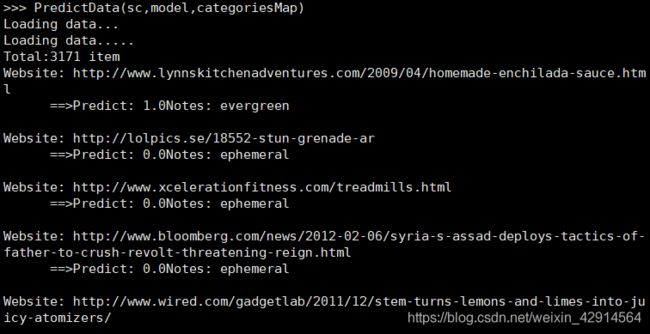
def PredictData(sc,model,categoriesMap):
print("Loading data...")
global Path
if sc.master[0:5] == "local":
Path = "file:/root/pythonwork/stum/"
else:
Path = "hdfs://master:9000/user/alex/stum/"
print("Loading data.....")
rawDataWithHeader = sc.textFile(Path+"data/test.tsv")
header = rawDataWithHeader.first()
rawData = rawDataWithHeader.filter(lambda x:x !=header)
rData = rawData.map(lambda x: x.replace("\"", ""))
lines = rData.map(lambda x: x.split("\t"))
print("Total:"+str(lines.count())+" item")
dataRDD = lines.map(lambda r:(r[0],extract_features(r,categoriesMap,len(r))))
DescDict = {
0:"ephemeral",
1:"evergreen"}
for data in dataRDD.take(10):
predictResult = model.predict(data[1])
print( "Website: "+str(data[0])+"\n"+\
" ==>Predict: "+str(predictResult)+\
"Notes: "+DescDict[predictResult]+"\n")


执行
print("*******Predicting*********")
PredictData(sc,model,categoriesMap)
5、评估准确率
AUC评估
针对二元分类法
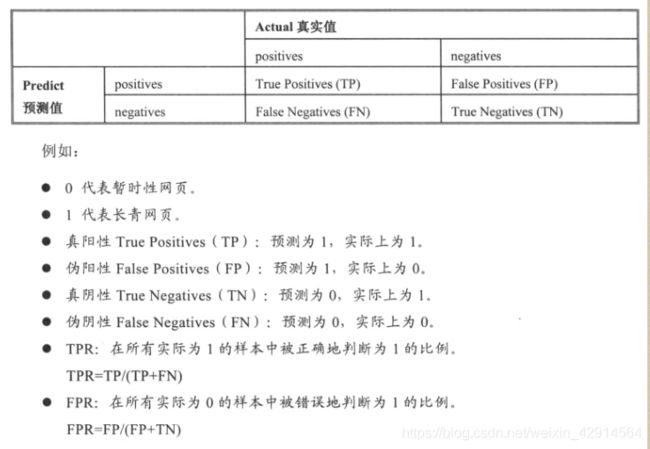
有了TPR、FPR就可以绘出ROC曲线图
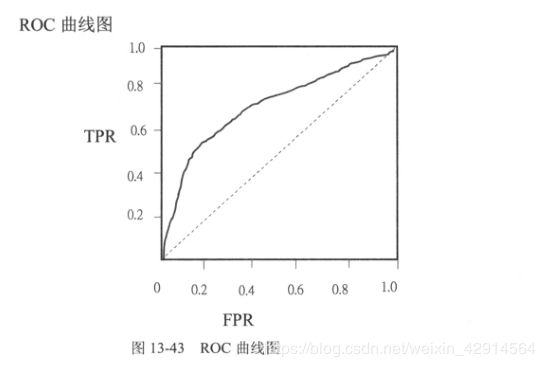
AUC就是ROC曲线下的面积

建立scoreAndLabels
score = model.predict(validationData.map(lambda p: p.features))
scoreAndLabels=score.zip(validationData.map(lambda p:p.label))
scoreAndLabels.take(5)
编写BinaryClassificationMetrics计算AUC
from pyspark.mllib.evaluation import BinaryClassificationMetrics
metrics = BinaryClassificationMetrics(scoreAndLabels)
print("AUC="+str(metrics.areaUnderROC))
将以上两个步骤封装成evaluateModel函数
def evaluateModel(model,validationData)
score = model.predict(validationData.map(lambda p: p.features))
scoreAndLabels=score.zip(validationData.map(lambda p:p.label))
BinaryClassificationMetrics
metrics = BinaryClassificationMetrics(scoreAndLabels)
return(metrics.areaUnderROC)
6、调参
建立trainEvaluateModel
from time import time
def trainEvaluateModel(trainData,validationData,impurityParm,maxDepthParm,maxBinsParm):
startTime = time()
model = DescisionTree.trainClassifier(trainData,numClasses=2,categoricalFeaturesInfo={},impurity=impurityParm,maxDepth=maxDepthParm,maxBins=maxBinsParm)
AUC=evaluateModel(model,validationData)
duration=time()-startTime
print(
"training evaluate:"+\
"impurity="+str(impurityParm)+\
"maxDepth="+str(maxDepthParm)+\
"maxBins="+str(maxBinsParm)+"\n"+\
"==>duration="+str(duration)+\
"Result AUC="+str(AUC))
return (AUC,duration,impurityParm,maxDepthParm,maxBinsParm,model)
解释
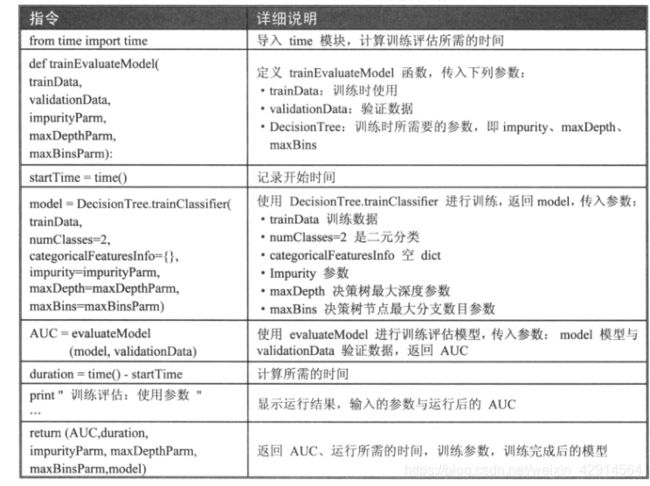
运行
(AUC,duration,impurityParm,maxDepthParm,maxBinsParm,model)=\
trainEvaluateModel(trainData,validationData,"entropy",5,5)
评估impurity参数
impurity=["gini","entropy"]
maxDepthList=[10]
maxBinsList=[10]
metric=[trainEvaluateModel(trainData,validationData,impurity,maxDepthList,maxBinsList)] for impurity in impurityList for maxDepth in maxDepthList for maxBins in maxBinsList
将metric转换为Pandas DataFrame
import pandas as pd
IndexList=impurityList
df = pd.DataFrame(metrics,index=IndexList,columns=['AUC','duration','impurity','maxDepth','maxBins','model'])
将参数评估封装为evalParameter
def evalParameter(trainData,validation,evalparm,impurityList,maxDepthList,maxBinsList):
metric=[trainEvaluateModel(trainData,validationData,impurity,maxDepthList,maxBinsList)] for impurity in impurityList for maxDepth in maxDepthList for maxBins in maxBinsList
if evalparm=="impurity":
IndexList=impurityList[:]
elif evalparm=="maxDepth":
IndexList=maxDepthList[:]
elif evalparm=="maxBins":
IndexList=maxBinsList[:]
df = pd.DataFrame(metrics,index=IndexList,columns=['AUC','duration','impurity','maxDepth','maxBins','model'])
return df
评估所有参数
def evalAllParameter(trainData, validationData,impurityList, maxDepthList, maxBinsList):
metric=[trainEvaluateModel(trainData,validationData,impurity,maxDepthList,maxBinsList) for impurity in impurityList for maxDepth in maxDepthList for maxBins in maxBinsList]
Smetrics = sorted(metrics,key=lambda k:k[0],reverse=True)
bestParameter=Smetrics[0]
return bestParameter[5]
调用方式:

是否过度训练
evaluateModel(model,testData)
如果这个值与训练阶段相差过大,代表过度训练,如果相差不大,则代表没问题