task03 字符识别模型
Datawhale 零基础入门CV赛事-Task3 字符识别模型
文章目录
- Datawhale 零基础入门CV赛事-Task3 字符识别模型
- 3 数据读取与数据扩增
- 3.1 学习目标
- 3.2 CNN介绍
- 3.3 CNN发展
- LeNet-5(1998)
- AlexNet(2012)
- VGG-16(2014)
- Inception-v1 (2014)
- ResNet-50 (2015)
- LeNet 模型
- AlexNet
- VGG( 使用重复元素的网络)
- NiN(⽹络中的⽹络)
- GoogLeNet
- GoogLeNet模型
- 卷积神经网络的基础概念(是卷积层和池化层,并解释填充、步幅、输入通道和输出通道的含义。)
- 二维互相关运算
- 互相关运算与卷积运算
- 特征图与感受野
- 填充和步幅
- 填充
- 步幅
- 多输入通道
- 1x1卷积层
- 卷积层与全连接层的对比
- 池化
- 二维池化层
- 模型间的对比
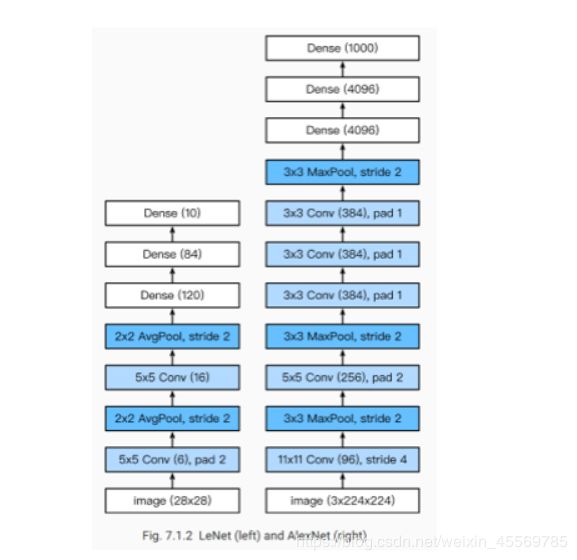
- LeNet与AlexNet的结构差异,并尝试解释AlexNet为什么会具有对计算机视觉任务优越的处理性能。
- 对比AlexNet、VGG和NiN、GoogLeNet的模型参数尺寸,从理论的层面分析为什么后两个网络可以显著减小模型参数尺寸?
- 尝试对AlexNet模型进行简化并将简化后的结构、节省的训练时间以及下降的准确率等相关指标以表格的形式进行总结分析。
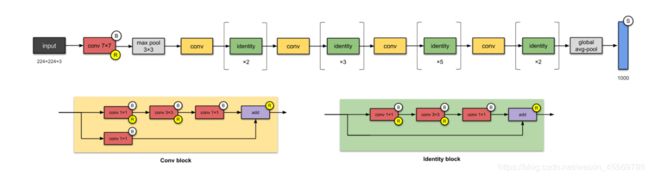
- GoogLeNet有数个后续版本,包括加入批量归一化层 [1]、对Inception块做调整 [2] 和加入残差连接 [3]
- Pytorch构建CNN模型
3 数据读取与数据扩增
本章将会讲解卷积神经网络(Convolutional Neural Network, CNN)的常见层,并从头搭建一个字符识别模型。
3.1 学习目标
- 学习CNN基础和原理
- 使用Pytorch框架构建CNN模型,并完成训练
3.2 CNN介绍
卷积神经网络(简称CNN)是一类特殊的人工神经网络,是深度学习中重要的一个分支。CNN在很多领域都表现优异,精度和速度比传统计算学习算法高很多。特别是在计算机视觉领域,CNN是解决图像分类、图像检索、物体检测和语义分割的主流模型。
CNN每一层由众多的卷积核组成,每个卷积核对输入的像素进行卷积操作,得到下一次的输入。随着网络层的增加卷积核会逐渐扩大感受野,并缩减图像的尺寸。
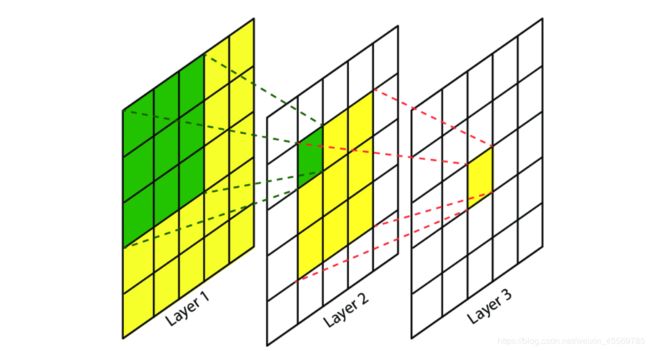
CNN是一种层次模型,输入的是原始的像素数据。CNN通过卷积(convolution)、池化(pooling)、非线性激活函数(non-linear activation function)和全连接层(fully connected layer)构成。
如下图所示为LeNet网络结构,是非常经典的字符识别模型。两个卷积层,两个池化层,两个全连接层组成。卷积核都是5×5,stride=1,池化层使用最大池化。
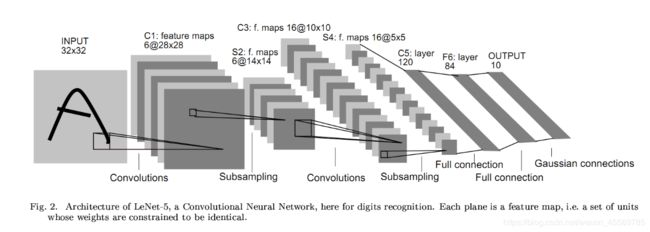
通过多次卷积和池化,CNN的最后一层将输入的图像像素映射为具体的输出。如在分类任务中会转换为不同类别的概率输出,然后计算真实标签与CNN模型的预测结果的差异,并通过反向传播更新每层的参数,并在更新完成后再次前向传播,如此反复直到训练完成 。
与传统机器学习模型相比,CNN具有一种端到端(End to End)的思路。在CNN训练的过程中是直接从图像像素到最终的输出,并不涉及到具体的特征提取和构建模型的过程,也不需要人工的参与。
3.3 CNN发展
随着网络结构的发展,研究人员最初发现网络模型结构越深、网络参数越多模型的精度更优。比较典型的是AlexNet、VGG、InceptionV3和ResNet的发展脉络。
-
LeNet-5(1998)

-
AlexNet(2012)

-
VGG-16(2014)

-
Inception-v1 (2014)
-
ResNet-50 (2015)
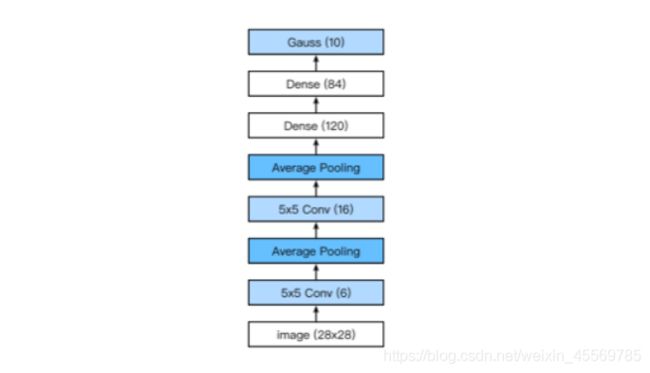
LeNet 模型
LeNet分为卷积层块和全连接层块两个部分。下面我们分别介绍这两个模块。
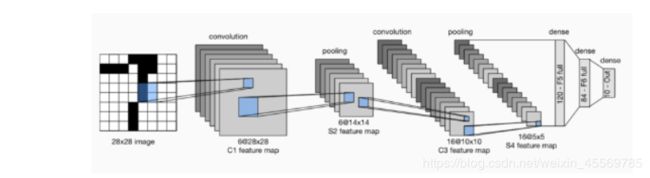
卷积层块里的基本单位是卷积层后接平均池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的平均池化层则用来降低卷积层对位置的敏感性。
卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用 5 × 5 5 \times 5 5×5的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。
全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
在卷积层块中输入的高和宽在逐层减小。卷积层由于使用高和宽均为5的卷积核,从而将高和宽分别减小4,而池化层则将高和宽减半,但通道数则从1增加到16。全连接层则逐层减少输出个数,直到变成图像的类别数10。
#net
class Flatten(torch.nn.Module): #展平操作
def forward(self, x):
return x.view(x.shape[0], -1)
class Reshape(torch.nn.Module): #将图像大小重定型
def forward(self, x):
return x.view(-1,1,28,28) #(B x C x H x W)
net = torch.nn.Sequential( #Lelet
Reshape(),
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), #b*1*28*28 =>b*6*28*28
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*6*28*28 =>b*6*14*14
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), #b*6*14*14 =>b*16*10*10
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*16*10*10 => b*16*5*5
Flatten(), #b*16*5*5 => b*400
nn.Linear(in_features=16*5*5, out_features=120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
X = torch.randn(size=(1,1,28,28), dtype = torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
Reshape output shape: torch.Size([1, 1, 28, 28])
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
AlexNet
首次证明了学习到的特征可以超越⼿⼯设计的特征,从而⼀举打破计算机视觉研究的前状。
特征:
- 8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。
- 将sigmoid激活函数改成了更加简单的ReLU激活函数。
- 用Dropout来控制全连接层的模型复杂度。
- 引入数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
#由于使用CPU镜像,精简网络,若为GPU镜像可添加该层
#nn.Linear(4096, 4096),
#nn.ReLU(),
#nn.Dropout(0.5),
nn.Linear(4096, 1000),
)
net = AlexNet()
print(net)
AlexNet(
(conv): Sequential(
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU()
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU()
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=6400, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=1000, bias=True)
)
)
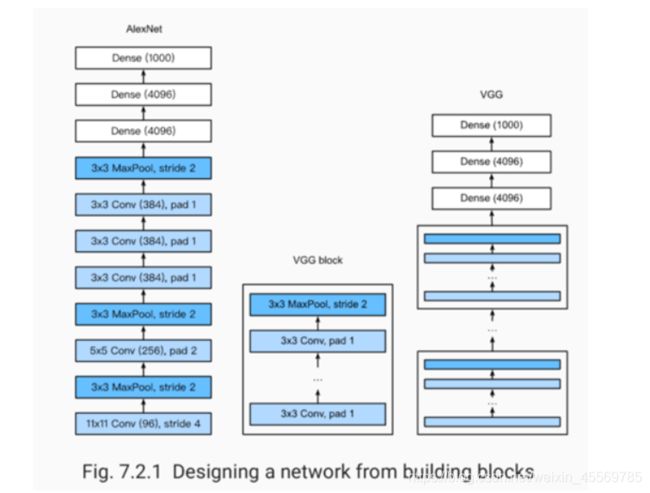
VGG( 使用重复元素的网络)
VGG:通过重复使⽤简单的基础块来构建深度模型。
Block:数个相同的填充为1、窗口形状为 3 × 3 3\times 3 3×3的卷积层,接上一个步幅为2、窗口形状为 2 × 2 2\times 2 2×2的最大池化层。
卷积层保持输入的高和宽不变,而池化层则对其减半。
def vgg_block(num_convs, in_channels, out_channels): #卷积层个数,输入通道数,输出通道数
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 512 * 7 * 7 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(Flatten(),#d2l.FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
net = vgg(conv_arch, fc_features, fc_hidden_units)
X = torch.rand(1, 1, 224, 224)
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
vgg_block_1 output shape: torch.Size([1, 64, 112, 112])
vgg_block_2 output shape: torch.Size([1, 128, 56, 56])
vgg_block_3 output shape: torch.Size([1, 256, 28, 28])
vgg_block_4 output shape: torch.Size([1, 512, 14, 14])
vgg_block_5 output shape: torch.Size([1, 512, 7, 7])
fc output shape: torch.Size([1, 10])
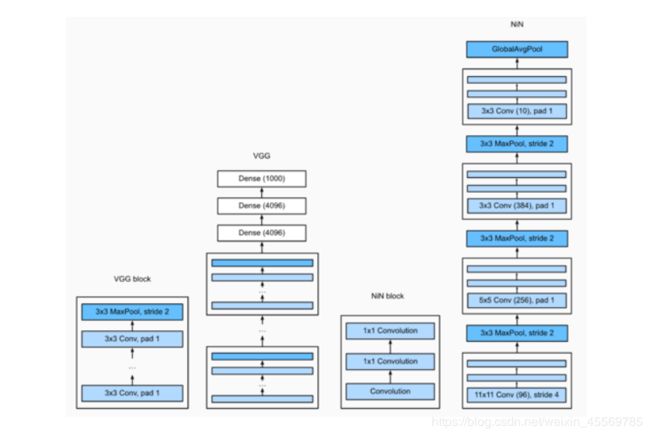
NiN(⽹络中的⽹络)
LeNet、AlexNet和VGG:先以由卷积层构成的模块充分抽取 空间特征,再以由全连接层构成的模块来输出分类结果。
NiN:串联多个由卷积层和“全连接”层构成的小⽹络来构建⼀个深层⽹络。
⽤了输出通道数等于标签类别数的NiN块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。
1×1卷积核作用
1.放缩通道数:通过控制卷积核的数量达到通道数的放缩。
2.增加非线性。1×1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性。
3.计算参数少
def nin_block(in_channels, out_channels, kernel_size, stride, padding):
blk = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU())
return blk
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, stride=4, padding=0),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(96, 256, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(256, 384, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, stride=1, padding=1),
GlobalAvgPool2d(),
# 将四维的输出转成二维的输出,其形状为(批量大小, 10)
Flatten())#d2l.FlattenLayer())
X = torch.rand(1, 1, 224, 224)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
0 output shape: torch.Size([1, 96, 54, 54])
1 output shape: torch.Size([1, 96, 26, 26])
2 output shape: torch.Size([1, 256, 26, 26])
3 output shape: torch.Size([1, 256, 12, 12])
4 output shape: torch.Size([1, 384, 12, 12])
5 output shape: torch.Size([1, 384, 5, 5])
6 output shape: torch.Size([1, 384, 5, 5])
7 output shape: torch.Size([1, 10, 5, 5])
8 output shape: torch.Size([1, 10, 1, 1])
9 output shape: torch.Size([1, 10])
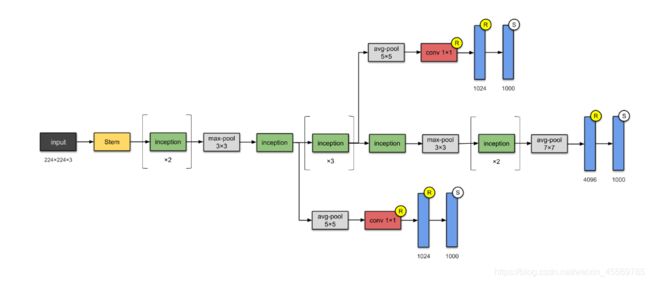
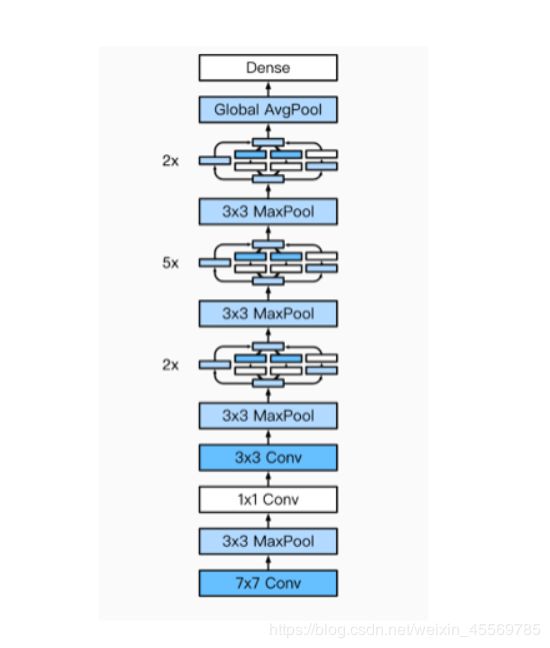
GoogLeNet
- 由Inception基础块组成。
- Inception块相当于⼀个有4条线路的⼦⽹络。它通过不同窗口形状的卷积层和最⼤池化层来并⾏抽取信息,并使⽤1×1卷积层减少通道数从而降低模型复杂度。
- 可以⾃定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。

GoogLeNet模型
完整模型结构
class Inception(nn.Module):
# c1 - c4为每条线路里的层的输出通道数
def __init__(self, in_c, c1, c2, c3, c4):
super(Inception, self).__init__()
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_c, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
GlobalAvgPool2d())
net = nn.Sequential(b1, b2, b3, b4, b5,
Flatten(), nn.Linear(1024, 10))
net = nn.Sequential(b1, b2, b3, b4, b5, Flatten(), nn.Linear(1024, 10))
X = torch.rand(1, 1, 96, 96)
for blk in net.children():
X = blk(X)
print('output shape: ', X.shape)
output shape: torch.Size([1, 64, 24, 24])
output shape: torch.Size([1, 192, 12, 12])
output shape: torch.Size([1, 480, 6, 6])
output shape: torch.Size([1, 832, 3, 3])
output shape: torch.Size([1, 1024, 1, 1])
output shape: torch.Size([1, 1024])
output shape: torch.Size([1, 10])
卷积神经网络的基础概念(是卷积层和池化层,并解释填充、步幅、输入通道和输出通道的含义。)
二维互相关运算
二维互相关(cross-correlation)运算的输入是一个二维输入数组和一个二维核(kernel)数组,输出也是一个二维数组,其中核数组通常称为卷积核或过滤器(filter)。卷积核的尺寸通常小于输入数组,卷积核在输入数组上滑动,在每个位置上,卷积核与该位置处的输入子数组按元素相乘并求和,得到输出数组中相应位置的元素。图1展示了一个互相关运算的例子,阴影部分分别是输入的第一个计算区域、核数组以及对应的输出。
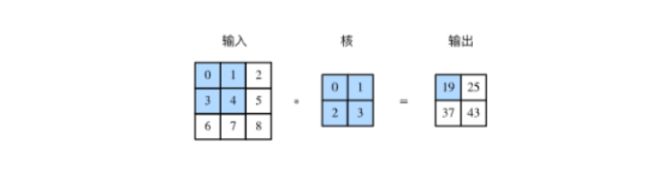
图1 二维互相关运算
下面我们用corr2d函数实现二维互相关运算,它接受输入数组X与核数组K,并输出数组Y。
互相关运算与卷积运算
卷积层得名于卷积运算,但卷积层中用到的并非卷积运算而是互相关运算。我们将核数组上下翻转、左右翻转,再与输入数组做互相关运算,这一过程就是卷积运算。由于卷积层的核数组是可学习的,所以使用互相关运算与使用卷积运算并无本质区别。
特征图与感受野
二维卷积层输出的二维数组可以看作是输入在空间维度(宽和高)上某一级的表征,也叫特征图(feature map)。影响元素 x x x的前向计算的所有可能输入区域(可能大于输入的实际尺寸)叫做 x x x的感受野(receptive field)。
以图1为例,输入中阴影部分的四个元素是输出中阴影部分元素的感受野。我们将图中形状为 2 × 2 2 \times 2 2×2的输出记为 Y Y Y,将 Y Y Y与另一个形状为 2 × 2 2 \times 2 2×2的核数组做互相关运算,输出单个元素 z z z。那么, z z z在 Y Y Y上的感受野包括 Y Y Y的全部四个元素,在输入上的感受野包括其中全部9个元素。可见,我们可以通过更深的卷积神经网络使特征图中单个元素的感受野变得更加广阔,从而捕捉输入上更大尺寸的特征。
填充和步幅
我们介绍卷积层的两个超参数,即填充和步幅,它们可以对给定形状的输入和卷积核改变输出形状。
填充
填充(padding)是指在输入高和宽的两侧填充元素(通常是0元素),图2里我们在原输入高和宽的两侧分别添加了值为0的元素。

图2 在输入的高和宽两侧分别填充了0元素的二维互相关计算
如果原输入的高和宽是 n h n_h nh和 n w n_w nw,卷积核的高和宽是 k h k_h kh和 k w k_w kw,在高的两侧一共填充 p h p_h ph行,在宽的两侧一共填充 p w p_w pw列,则输出形状为:
( n h + p h − k h + 1 ) × ( n w + p w − k w + 1 ) (n_h+p_h-k_h+1)\times(n_w+p_w-k_w+1) (nh+ph−kh+1)×(nw+pw−kw+1)
我们在卷积神经网络中使用奇数高宽的核,比如 3 × 3 3 \times 3 3×3, 5 × 5 5 \times 5 5×5的卷积核,对于高度(或宽度)为大小为 2 k + 1 2 k + 1 2k+1的核,令步幅为1,在高(或宽)两侧选择大小为 k k k的填充,便可保持输入与输出尺寸相同。
步幅
在互相关运算中,卷积核在输入数组上滑动,每次滑动的行数与列数即是步幅(stride)。此前我们使用的步幅都是1,图3展示了在高上步幅为3、在宽上步幅为2的二维互相关运算。
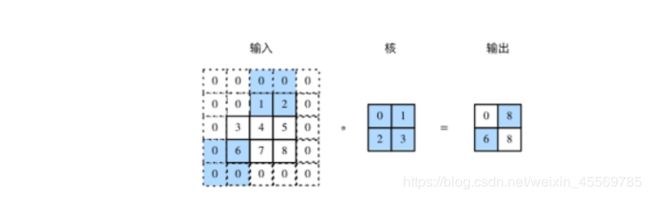
图3 高和宽上步幅分别为3和2的二维互相关运算
一般来说,当高上步幅为 s h s_h sh,宽上步幅为 s w s_w sw时,输出形状为:
⌊ ( n h + p h − k h + s h ) / s h ⌋ × ⌊ ( n w + p w − k w + s w ) / s w ⌋ \lfloor(n_h+p_h-k_h+s_h)/s_h\rfloor \times \lfloor(n_w+p_w-k_w+s_w)/s_w\rfloor ⌊(nh+ph−kh+sh)/sh⌋×⌊(nw+pw−kw+sw)/sw⌋
如果 p h = k h − 1 p_h=k_h-1 ph=kh−1, p w = k w − 1 p_w=k_w-1 pw=kw−1,那么输出形状将简化为 ⌊ ( n h + s h − 1 ) / s h ⌋ × ⌊ ( n w + s w − 1 ) / s w ⌋ \lfloor(n_h+s_h-1)/s_h\rfloor \times \lfloor(n_w+s_w-1)/s_w\rfloor ⌊(nh+sh−1)/sh⌋×⌊(nw+sw−1)/sw⌋。更进一步,如果输入的高和宽能分别被高和宽上的步幅整除,那么输出形状将是 ( n h / s h ) × ( n w / s w ) (n_h / s_h) \times (n_w/s_w) (nh/sh)×(nw/sw)。
当 p h = p w = p p_h = p_w = p ph=pw=p时,我们称填充为 p p p;当 s h = s w = s s_h = s_w = s sh=sw=s时,我们称步幅为 s s s。
多输入通道
卷积层的输入可以包含多个通道,图4展示了一个含2个输入通道的二维互相关计算的例子。

图4 含2个输入通道的互相关计算
假设输入数据的通道数为 c i c_i ci,卷积核形状为 k h × k w k_h\times k_w kh×kw,我们为每个输入通道各分配一个形状为 k h × k w k_h\times k_w kh×kw的核数组,将 c i c_i ci个互相关运算的二维输出按通道相加,得到一个二维数组作为输出。我们把 c i c_i ci个核数组在通道维上连结,即得到一个形状为 c i × k h × k w c_i\times k_h\times k_w ci×kh×kw的卷积核。
1x1卷积层
最后讨论形状为 1 × 1 1 \times 1 1×1的卷积核,我们通常称这样的卷积运算为 1 × 1 1 \times 1 1×1卷积,称包含这种卷积核的卷积层为 1 × 1 1 \times 1 1×1卷积层。图5展示了使用输入通道数为3、输出通道数为2的 1 × 1 1\times 1 1×1卷积核的互相关计算。
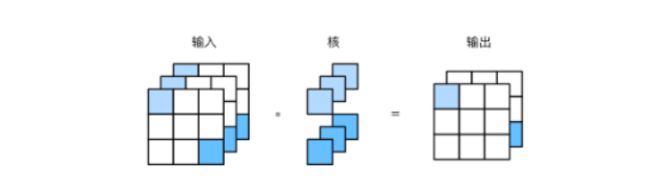
图5 1x1卷积核的互相关计算。输入和输出具有相同的高和宽
1 × 1 1 \times 1 1×1卷积核可在不改变高宽的情况下,调整通道数。 1 × 1 1 \times 1 1×1卷积核不识别高和宽维度上相邻元素构成的模式,其主要计算发生在通道维上。假设我们将通道维当作特征维,将高和宽维度上的元素当成数据样本,那么 1 × 1 1\times 1 1×1卷积层的作用与全连接层等价。
卷积层与全连接层的对比
二维卷积层经常用于处理图像,与此前的全连接层相比,它主要有两个优势:
一是全连接层把图像展平成一个向量,在输入图像上相邻的元素可能因为展平操作不再相邻,网络难以捕捉局部信息。而卷积层的设计,天然地具有提取局部信息的能力。
二是卷积层的参数量更少。不考虑偏置的情况下,一个形状为 ( c i , c o , h , w ) (c_i, c_o, h, w) (ci,co,h,w)的卷积核的参数量是 c i × c o × h × w c_i \times c_o \times h \times w ci×co×h×w,与输入图像的宽高无关。假如一个卷积层的输入和输出形状分别是 ( c 1 , h 1 , w 1 ) (c_1, h_1, w_1) (c1,h1,w1)和 ( c 2 , h 2 , w 2 ) (c_2, h_2, w_2) (c2,h2,w2),如果要用全连接层进行连接,参数数量就是 c 1 × c 2 × h 1 × w 1 × h 2 × w 2 c_1 \times c_2 \times h_1 \times w_1 \times h_2 \times w_2 c1×c2×h1×w1×h2×w2。使用卷积层可以以较少的参数数量来处理更大的图像。
池化
二维池化层
池化层主要用于缓解卷积层对位置的过度敏感性。同卷积层一样,池化层每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算输出,池化层直接计算池化窗口内元素的最大值或者平均值,该运算也分别叫做最大池化或平均池化。图6展示了池化窗口形状为 2 × 2 2\times 2 2×2的最大池化。
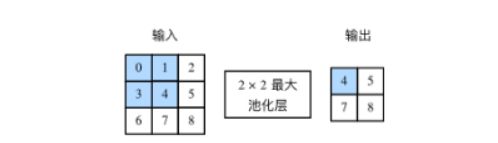
图6 池化窗口形状为 2 x 2 的最大池化
二维平均池化的工作原理与二维最大池化类似,但将最大运算符替换成平均运算符。池化窗口形状为 p × q p \times q p×q的池化层称为 p × q p \times q p×q池化层,其中的池化运算叫作 p × q p \times q p×q池化。
池化层也可以在输入的高和宽两侧填充并调整窗口的移动步幅来改变输出形状。池化层填充和步幅与卷积层填充和步幅的工作机制一样。
在处理多通道输入数据时,池化层对每个输入通道分别池化,但不会像卷积层那样将各通道的结果按通道相加。这意味着池化层的输出通道数与输入通道数相等。
模型间的对比
LeNet与AlexNet的结构差异,并尝试解释AlexNet为什么会具有对计算机视觉任务优越的处理性能。
1.AlexNet使用了更加简单的ReLU激活函数,而LeNet使用的是Sigmoid激活函数
2.AlexNet还在LeNet的基础上增加了三个卷积层
3.AlexNet用Dropout 来控制全连接层的模型复杂的,防止过拟合
4.AlexNet引入了数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
5.AlexNet使用的是最大池化,抓住最重要的特征,在模型上会有稀疏的作用,而LeNet使用的是平均池化
6.AlexNet的卷积通道数是LeNet的数十倍,多的卷积通道数代表的是更多的特征
对比AlexNet、VGG和NiN、GoogLeNet的模型参数尺寸,从理论的层面分析为什么后两个网络可以显著减小模型参数尺寸?
1.NiN是串联了多个由卷积层和"全连接层"构成的小网络来构建一个深层网络(使用了1*1的卷积层来代替了全连接层,1x1的卷积层,可以看成全连接层,其中空间维度(高和宽)上的每个元素相当于样本,通道相当于特征。因此,NIN使用1x1卷积层来替代全连接层,从而使空间信息能够自然传递到后面的层。)
2.而且其去掉了最后的三个全连接层,而是用了一个平均池化层来作为代替(通过调整输出的通道数使其输出仍为类别数),这里的全局平均池化层的设计显著的减少了模型的参数尺寸同时也缓解了过拟合,但是这个设计也会造成模型的训练时间的增加。
而且其使用1*1的卷积核也会减少计算的参数。
3.GoogLeNet应该也是使用了全局平均池化层的设计显著的减少了模型的参数尺寸但其后面又引入了dense所以其全局平均池化层输出的通道不一定是类别数
尝试对AlexNet模型进行简化并将简化后的结构、节省的训练时间以及下降的准确率等相关指标以表格的形式进行总结分析。
| 简化的操作 | 训练时间 | 准确率 |
|---|---|---|
| 将全连接层的参数由1000->10;epochs->3 | 265.6 s | 0.863 |
| 删除网络中群连接层4096到4096的那一层 | 213.5 s | 0.887 |
| -------- | -------- | -------- |
| 删除输出通道数数和输入通道数相等的卷积层 | 190.9 s | 0.886 |
| 增大学习率lr:0.001->0.004 | 80.0 s | 0.890 |
| -------- | -------- | -------- |
| 减小学习率 lr:0.004→0.002 | 80.3 s | 0.908 |
GoogLeNet有数个后续版本,包括加入批量归一化层 [1]、对Inception块做调整 [2] 和加入残差连接 [3]
| V1 | 使用了1*1的卷积核来压缩通道数 |
|---|---|
| V2 | 在Inception的内部采用标准化卷积核 |
| V3 | 将“标准化”推广到一般情况,并加入了BN |
| V4 | 在V3的基础上选定了更合适的超参 |
| Inception-ResNet网络 | 引入residual connection直连,把Inception和ResNet结合起来 |
[1] Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.
[2] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2818-2826).
[3] Szegedy, C., Ioffe, S., Vanhoucke, V., & Alemi, A. A. (2017, February). Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 4, p. 12).
Pytorch构建CNN模型
在上一章节我们讲解了如何使用Pytorch来读取赛题数据集,本节我们使用本章学习到的知识构件一个简单的CNN模型,完成字符识别功能。
在Pytorch中构建CNN模型非常简单,只需要定义好模型的参数和正向传播即可,Pytorch会根据正向传播自动计算反向传播。
在本章我们会构建一个非常简单的CNN,然后进行训练。这个CNN模型包括两个卷积层,最后并联6个全连接层进行分类。
import os, sys, glob, shutil, json
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
import cv2
from PIL import Image
import numpy as np
from tqdm import tqdm, tqdm_notebook
%pylab inline
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
Populating the interactive namespace from numpy and matplotlib
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
import os, sys, glob, shutil, json
# 定义模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
# CNN提取特征模块
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.MaxPool2d(2),
)
#
self.fc1 = nn.Linear(32*3*7, 11)
self.fc2 = nn.Linear(32*3*7, 11)
self.fc3 = nn.Linear(32*3*7, 11)
self.fc4 = nn.Linear(32*3*7, 11)
self.fc5 = nn.Linear(32*3*7, 11)
self.fc6 = nn.Linear(32*3*7, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
c6 = self.fc6(feat)
return c1, c2, c3, c4, c5, c6
model = SVHN_Model1()
X = torch.rand(1,3,64,128)
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in model.cnn.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
0 output shape: torch.Size([1, 16, 31, 63])
1 output shape: torch.Size([1, 16, 31, 63])
2 output shape: torch.Size([1, 16, 15, 31])
3 output shape: torch.Size([1, 32, 7, 15])
4 output shape: torch.Size([1, 32, 7, 15])
5 output shape: torch.Size([1, 32, 3, 7])
接下来是训练代码:
class SVHNDataset(Dataset):
def __init__(self, img_path, img_label, transform=None):
self.img_path = img_path
self.img_label = img_label
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
img = Image.open(self.img_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
lbl = np.array(self.img_label[index], dtype=np.int)
lbl = list(lbl) + (5 - len(lbl)) * [10]
return img, torch.from_numpy(np.array(lbl[:5]))
def __len__(self):
return len(self.img_path)
train_path = glob.glob('./input/train/train/*.png')
train_path.sort()
train_json = json.load(open('./input/train.json'))
train_label = [train_json[x]['label'] for x in train_json]
print(len(train_path), len(train_label))
train_loader = torch.utils.data.DataLoader(
SVHNDataset(train_path, train_label,
transforms.Compose([
transforms.Resize((64, 128)),
transforms.RandomCrop((60, 120)),
transforms.ColorJitter(0.3, 0.3, 0.2),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=40,
shuffle=True,
num_workers=0,
)
30000 30000
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), 0.005)
loss_plot, c0_plot = [], []
# 迭代10个Epoch
for epoch in range(1):
for data in train_loader:
data[1] = data[1].long()
c0, c1, c2, c3, c4, c5 = model(data[0])
loss = criterion(c0, data[1][:, 0]) + \
criterion(c1, data[1][:, 1]) + \
criterion(c2, data[1][:, 2]) + \
criterion(c3, data[1][:, 3]) + \
criterion(c4, data[1][:, 4]) #+ \
# criterion(c5, data[1][:, 5])
loss /= 5#6
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_plot.append(loss.item())
c0_plot.append((c0.argmax(1) == data[1][:, 0]).sum().item()*1.0 / c0.shape[0])
print(c0.argmax(1))
print(data[1])
break
print(epoch,loss_plot,c0_plot)
tensor([1, 3, 1, 1, 2, 1, 1, 2, 7, 2, 2, 2, 1, 5, 3, 2, 1, 2, 2, 2, 1, 1, 1, 2,
1, 1, 2, 2, 6, 2, 1, 1, 2, 2, 1, 1, 1, 1, 1, 2],
grad_fn=)
tensor([[ 1, 5, 10, 10, 10],
[ 8, 5, 10, 10, 10],
[ 9, 2, 10, 10, 10],
[ 3, 1, 10, 10, 10],
[ 2, 5, 4, 10, 10],
[ 4, 4, 10, 10, 10],
[ 1, 5, 7, 5, 10],
[ 7, 0, 10, 10, 10],
[ 1, 7, 10, 10, 10],
[ 1, 4, 8, 10, 10],
[ 2, 2, 10, 10, 10],
[ 1, 6, 4, 10, 10],
[ 1, 5, 4, 10, 10],
[ 5, 7, 10, 10, 10],
[ 7, 10, 10, 10, 10],
[ 1, 2, 0, 10, 10],
[ 3, 10, 10, 10, 10],
[ 3, 3, 10, 10, 10],
[ 9, 3, 10, 10, 10],
[ 1, 4, 4, 10, 10],
[ 1, 3, 10, 10, 10],
[ 5, 4, 5, 10, 10],
[ 1, 3, 10, 10, 10],
[ 2, 5, 10, 10, 10],
[ 4, 10, 10, 10, 10],
[ 8, 1, 2, 10, 10],
[ 2, 5, 0, 10, 10],
[ 2, 6, 10, 10, 10],
[ 6, 10, 10, 10, 10],
[ 2, 0, 10, 10, 10],
[ 1, 9, 0, 6, 10],
[ 1, 3, 4, 10, 10],
[ 3, 8, 10, 10, 10],
[ 1, 4, 10, 10, 10],
[ 1, 2, 1, 9, 10],
[ 1, 3, 6, 10, 10],
[ 6, 7, 10, 10, 10],
[ 1, 1, 10, 10, 10],
[ 1, 2, 10, 10, 10],
[ 2, 1, 2, 10, 10]])
0 [1.054978370666504] [0.5]
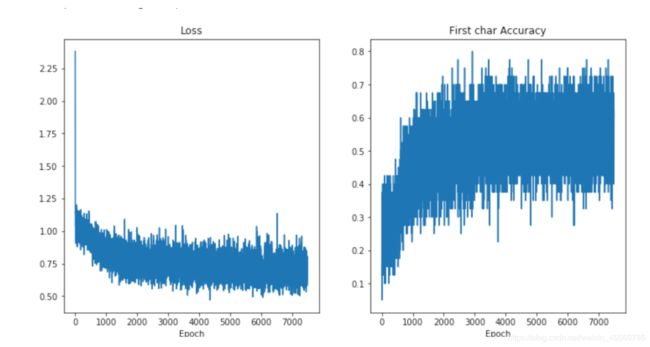
在训练完成后我们可以将训练过程中的损失和准确率进行绘制,如下图所示。从图中可以看出模型的损失在迭代过程中逐渐减小,字符预测的准确率逐渐升高。
当然为了追求精度,也可以使用在ImageNet数据集上的预训练模型,具体方法如下:
class SVHN_Model2(SVHN_Model1):#nn.Module
def __init__(self):
super(SVHN_Model1, self).__init__()
model_conv = models.resnet50(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4, c5
net = SVHN_Model2()
print(net)
SVHN_Model2(
(cnn): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(5): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(6): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(7): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(8): AdaptiveAvgPool2d(output_size=1)
)
(fc1): Linear(in_features=512, out_features=11, bias=True)
(fc2): Linear(in_features=512, out_features=11, bias=True)
(fc3): Linear(in_features=512, out_features=11, bias=True)
(fc4): Linear(in_features=512, out_features=11, bias=True)
(fc5): Linear(in_features=512, out_features=11, bias=True)
)
X = torch.rand(1,3,64,128)
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in net.cnn.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
0 output shape: torch.Size([1, 64, 32, 64])
1 output shape: torch.Size([1, 64, 32, 64])
2 output shape: torch.Size([1, 64, 32, 64])
3 output shape: torch.Size([1, 64, 16, 32])
4 output shape: torch.Size([1, 64, 16, 32])
5 output shape: torch.Size([1, 128, 8, 16])
6 output shape: torch.Size([1, 256, 4, 8])
7 output shape: torch.Size([1, 512, 2, 4])
8 output shape: torch.Size([1, 512, 1, 1])
### 3.5 本章小节
在本章中我们介绍了CNN以及CNN的发展,并使用Pytorch构建构建了一个简易的CNN模型来完成字符分类任务。