【TensorFlow-windows】学习笔记六——变分自编码器
#前言
对理论没兴趣的直接看代码吧,理论一堆,而且还有点复杂,我自己的描述也不一定准确,但是代码就两三句话搞定了。
国际惯例,参考博文
论文:Tutorial on Variational Autoencoders
【干货】一文读懂什么是变分自编码器
CS598LAZ - Variational Autoencoders
MusicVAE: Creating a palette for musical scores with machine learning
【Learning Notes】变分自编码器(Variational Auto-Encoder,VAE)
花式解释AutoEncoder与VAE
#理论
##基础知识
似然函数(引自百度百科)
似然函数是关于统计模型中的参数的函数,表示模型参数的似然性。在给定输出 x x x时,关于参数 θ \theta θ的似然函数 L ( θ ∣ x ) L(\theta|x) L(θ∣x)在数值上等于给定参数 θ \theta θ后变量 X X X的概率:
L ( θ ∣ x ) = P ( X = x ∣ θ ) L(\theta|x)=P(X=x|\theta) L(θ∣x)=P(X=x∣θ)
有两个比较有趣的说法来区分概率与似然的关系,比如抛硬币的例子:
- 概率说法:对于“一枚正反对称的硬币上抛十次”这种事件,问硬币落地时十次都是正面向上的“概率”是多少
- 似然说法:对于“一枚硬币上抛十次”,问这枚硬币正反面对称的“似然”程度是多少。
极大似然估计
(摘自西瓜书)两大学派:
- 频率主义学:参数是固定的,通过优化似然函数来确定参数
- 贝叶斯学派:参数是变化的,且本身具有某种分布,先假设参数服从某个先验分布,然后基于观测到的数据来计算参数的后验分布
极大似然估计(Maximum Likelihood Estimation,MLE)源自频率主义学。
假设 D D D是第 c c c类样本的集合,比如所有的数字 3 3 3的图片集合,假设它们是独立同分布的,则参数 θ \theta θ对于数据集 D D D的似然是:
P ( D ∣ θ ) = ∏ x ∈ D P ( x ∣ θ ) P(D|\theta)=\prod_{x\in D}P(x|\theta) P(D∣θ)=x∈D∏P(x∣θ)
极大似然估计就是寻找一个 θ \theta θ使得样本 x x x出现的概率最大
但是上面的连乘比较难算,这就出现了对数似然:
L ( θ ) = log P ( D ∣ θ ) = ∑ x ∈ D log P ( x ∣ D ) L(\theta)=\log P(D|\theta)=\sum_{x\in D}\log P(x|D) L(θ)=logP(D∣θ)=x∈D∑logP(x∣D)
我们的目标就是求参数 θ \theta θ的极大似然估计 θ ^ \hat{\theta} θ^
θ ^ = arg max θ L ( θ ) \hat{\theta}=\arg \max_{\theta}L(\theta) θ^=argθmaxL(θ)
例子:在连续属性情况下,如果样本集合概率密度函数 p ( x ∣ c ) ∼ N ( μ , σ 2 ) p(x|c)\sim N(\mu,\sigma^2) p(x∣c)∼N(μ,σ2),那么参数 μ , σ 2 \mu,\sigma^2 μ,σ2的极大似然估计就是
μ ^ = 1 ∣ D ∣ ∑ x ∈ D x σ ^ 2 = 1 ∣ D ∣ ∑ x ∈ D ( x − μ ^ ) ( x − μ ^ ) T \begin{aligned} \hat{\mu}&=\frac{1}{|D|}\sum_{x\in D}x\\ \hat{\sigma}^2&=\frac{1}{|D|}\sum_{x \in D}(x-\hat{\mu})(x-\hat{\mu})^T \end{aligned} μ^σ^2=∣D∣1x∈D∑x=∣D∣1x∈D∑(x−μ^)(x−μ^)T
其实就是计算均值和方差了。这样想,这些样本就服从这个高斯分布,那么把高斯分布直接当做参数,一定能够大概率得到此类样本,也就是说用 3 3 3的样本所服从的高斯分布作为模型参数一定能使 3 3 3出现的概率 P ( x ∣ θ ) P(x|\theta) P(x∣θ)最大。
###期望值最大化算法(EM)
这一部分简单说一下即可,详细的在我前面的博客HMM——前向后向算法中有介绍,主要有两步:
-
E步:求Q函数 Q ( θ , θ ( i ) ) Q(\theta,\theta^{(i)}) Q(θ,θ(i)),这个 θ ( i ) \theta^{(i)} θ(i)就是当前迭代次数 i i i对应的参数值,Q函数实际就是对数联合似然函数 log P ( X , Z ∣ θ ) \log P(X,Z|\theta) logP(X,Z∣θ)在分布 P ( Z ∣ X , θ ( i ) ) P(Z|X,\theta^{(i)}) P(Z∣X,θ(i))下的期望
Q ( θ , θ ( i ) ) = E Z ∣ X , θ ( i ) L ( θ ∣ X , Z ) = E z [ log P ( X , Z ∣ θ ) ∣ X , θ ( i ) ] = ∑ Z P ( Z ∣ X , θ ( i ) ) log P ( X , Z ∣ θ ) \begin{aligned} Q(\theta,\theta^{(i)})&=E_{Z|X,\theta^{(i)}}L(\theta|X,Z)\\ &=E_z\left[\log P(X,Z|\theta)|X,\theta^{(i)}\right]\\ &=\sum_Z P(Z|X,\theta^{(i)})\log P(X,Z|\theta) \end{aligned} Q(θ,θ(i))=EZ∣X,θ(i)L(θ∣X,Z)=Ez[logP(X,Z∣θ)∣X,θ(i)]=Z∑P(Z∣X,θ(i))logP(X,Z∣θ) -
M步:求使得Q函数最大化的参数 θ \theta θ,并将其作为下一步的 θ ( i ) \theta^{(i)} θ(i)
θ ( i + 1 ) = arg max θ Q ( θ , θ ( i ) ) \theta^{(i+1)}=\arg\max_\theta Q(\theta,\theta^{(i)}) θ(i+1)=argθmaxQ(θ,θ(i))
从西瓜书上再摘点主要内容过来:
有时候样本的一些属性可以观测到,而另一些属性观测不到,所以就定义未观测变量为隐变量,设 X X X为可观测变量, Z Z Z为隐变量, θ \theta θ为模型参数,则可写出对数似然:
L ( θ ∣ X , Z ) = ln P ( X , Z ∣ θ ) L(\theta|X,Z)=\ln P(X,Z|\theta) L(θ∣X,Z)=lnP(X,Z∣θ)
但是 Z Z Z又不知道,所以采用边缘化(marginal)方法消除它
L ( θ ∣ X ) = ln P ( X ∣ θ ) = ln ∑ Z P ( X , Z ∣ θ ) = ∑ i = 1 N ln { ∑ Z P ( x i , Z ∣ θ ) } L(\theta|X)=\ln P(X|\theta)=\ln\sum_Z P(X,Z|\theta)=\sum_{i=1}^N\ln\left\{\sum_Z P(x_i,Z|\theta)\right\} L(θ∣X)=lnP(X∣θ)=lnZ∑P(X,Z∣θ)=i=1∑Nln{Z∑P(xi,Z∣θ)}
使用EM算法求解参数的方法是:
- 基于 θ ( i ) \theta^{(i)} θ(i)推断隐变量 Z Z Z的期望,记为 Z t Z^t Zt
- 基于已观测变量 X X X和 Z t Z^t Zt对参数 θ \theta θ做极大似然估计,求得 θ ( i + 1 ) \theta^{(i+1)} θ(i+1)
【注】是不是感觉很像坐标下降法
变分推断
(摘自西瓜书)
变分推断是通过使用已知简单分布来逼近需推断的复杂分布,并通过限制近似分布的类型,从而得到一种局部最优,但具有确定解的近似后验分布。
继续看上面的EM算法的M步,我们得到了:
θ ( i + 1 ) = arg max θ Q ( θ , θ ( i ) ) = arg max θ ∑ Z P ( Z ∣ x , θ ( i ) ) ln P ( x , Z ∣ θ ) \begin{aligned} \theta^{(i+1)}&=\arg\max_\theta Q(\theta,\theta^{(i)})\\ &=\arg\max_\theta \sum_ZP\left(Z|x,\theta^{(i)}\right)\ln P(x,Z|\theta) \end{aligned} θ(i+1)=argθmaxQ(θ,θ(i))=argθmaxZ∑P(Z∣x,θ(i))lnP(x,Z∣θ)
还记得 Q Q Q函数的意义吧,对数联合似然函数 ln P ( X , Z ∣ θ ) \ln P(X,Z|\theta) lnP(X,Z∣θ)在分布 P ( Z ∣ X , θ ( i ) ) P(Z|X,\theta^{(i)}) P(Z∣X,θ(i))下的期望。当分布 P ( Z ∣ X , θ ( i ) ) P(Z|X,\theta^{(i)}) P(Z∣X,θ(i))与变量 Z Z Z的真实后验分布相等的时候, Q Q Q函数就近似于对数似然函数,因而EM算法能够获得稳定的参数 θ \theta θ,且隐变量 Z Z Z的分布也能通过该参数获得。
但是通常情况下, P ( Z ∣ X , θ ( i ) ) P(Z|X,\theta^{(i)}) P(Z∣X,θ(i))只是隐变量 Z Z Z所服从的真实分布的近似,若用 Q ( Z ) Q(Z) Q(Z)表示,则
ln P ( X ) = L ( Q ) + K L ( Q ∣ ∣ P ) \ln P(X)=L(Q)+KL(Q||P) lnP(X)=L(Q)+KL(Q∣∣P)
其中
L ( Q ) = ∫ Q ( Z ) ln { P ( X , Z ) Q ( Z ) } d Z K L ( Q ∣ ∣ P ) = − ∫ Q ( Z ) ln P ( Z ∣ X ) Q ( Z ) d Z L(Q)=\int Q(Z)\ln\left\{\frac{P(X,Z)}{Q(Z)}\right\}dZ\\ KL(Q||P)=-\int Q(Z)\ln \frac{P(Z|X)}{Q(Z)}dZ L(Q)=∫Q(Z)ln{Q(Z)P(X,Z)}dZKL(Q∣∣P)=−∫Q(Z)lnQ(Z)P(Z∣X)dZ
但是,这个 Z Z Z模型可能很复杂,导致E步的 P ( Z ∣ X , θ ) P(Z|X,\theta) P(Z∣X,θ)比较难推断,这时候就借用变分推断了,假设 Z Z Z服从分布
Q ( Z ) = ∏ i = 1 M Q i ( Z i ) Q(Z)=\prod_{i=1}^MQ_i(Z_i) Q(Z)=i=1∏MQi(Zi)
也就是说多变量 Z Z Z可拆解为一系列相互独立的多变量 Z i Z_i Zi,可以另 Q i Q_i Qi是非常简单的分布。
【PS】浅尝辄止了,经过层层理论已经引出了变分自编码的主要思想,变分推断,使用简单分布逼近复杂分布,实际上,变分自编码所使用的简单分布就是高斯分布,用多个高斯分布来逼近隐变量,随后利用服从这些分布的隐变量重构我们想要的数据。
变分自编码
先看优化目标ELBO(Evidence Lower Bound):
E L B O = log p ( x ) − K L [ q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ] ELBO=\log p(x)-KL\left[q(z|x)||p(z|x)\right] ELBO=logp(x)−KL[q(z∣x)∣∣p(z∣x)]
其中 q q q是假设分布, p p p是真实分布,我们希望最大化第一项而最小化KL距离,所以整个规则就是最大化 E L B O ELBO ELBO,但是这里面有个 p ( z ∣ x ) p(z|x) p(z∣x)代表隐变量的真实分布,这个是无法求解的,所以需要简化:
简化结果是:
log p ( x ) − K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) = E z ∼ q [ log P ( x ∣ z ) ] − K L ( q ( z ) ∣ ∣ p ( z ) ) \log p(x)-KL(q(z)||p(z|x))=E_{z\sim q}\left[\log P(x|z)\right]-KL(q(z)||p(z)) logp(x)−KL(q(z)∣∣p(z∣x))=Ez∼q[logP(x∣z)]−KL(q(z)∣∣p(z))
证明:
假设KL距离为 K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) = E z ∼ q [ log q ( z ) − log p ( z ∣ x ) ] KL(q(z)||p(z|x))=E_{z\sim q}\left[\log q(z)-\log p(z|x)\right] KL(q(z)∣∣p(z∣x))=Ez∼q[logq(z)−logp(z∣x)]
那么直接使用贝叶斯准则:
- p ( z ∣ x ) = p ( x ∣ z ) p ( z ) p ( x ) p(z|x)=\frac{p(x|z)p(z)}{p(x)} p(z∣x)=p(x)p(x∣z)p(z)
- log p ( z ∣ x ) = log p ( x ∣ z ) + log p ( z ) − log p ( x ) \log p(z|x)=\log p(x|z)+\log p(z)-\log p(x) logp(z∣x)=logp(x∣z)+logp(z)−logp(x)
- p ( x ) p(x) p(x)不依赖于z
可以得到:
K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) = E z ∼ q ( log q ( z ) − log p ( x ∣ z ) − log p ( z ) ) + log p ( x ) KL(q(z)||p(z|x))=E_{z\sim q}(\log q(z)-\log p(x|z)-\log p(z))+\log p(x) KL(q(z)∣∣p(z∣x))=Ez∼q(logq(z)−logp(x∣z)−logp(z))+logp(x)
其中 E z ∼ q ( log q ( z ) − log p ( z ) ) = K L ( q ( z ) ∣ ∣ p ( z ) ) E_{z\sim q}(\log q(z)-\log p(z))=KL(q(z)||p(z)) Ez∼q(logq(z)−logp(z))=KL(q(z)∣∣p(z))
所以就能继续简化那个 K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) KL(q(z)||p(z|x)) KL(q(z)∣∣p(z∣x))了:
log p ( x ) − K L ( q ( z ) ∣ p ( z ∣ x ) ) = E z ∼ q [ log p ( x ∣ z ) ] − K L ( q ( z ) ∣ ∣ p ( z ) ) \log p(x)-KL(q(z)|p(z|x))=E_{z\sim q}[\log p(x|z)]-KL(q(z)||p(z)) logp(x)−KL(q(z)∣p(z∣x))=Ez∼q[logp(x∣z)]−KL(q(z)∣∣p(z))
证毕
但是我们的优化目标是
E L B O = log p ( x ) − K L [ q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ] ELBO=\log p(x)-KL\left[q(z|x)||p(z|x)\right] ELBO=logp(x)−KL[q(z∣x)∣∣p(z∣x)]
发现一个是 q ( z ) q(z) q(z)一个是 q ( z ∣ x ) q(z|x) q(z∣x),怎么办呢?看论文第8页有这样一句话:
Note that X is fixed, and Q can be any distribution, not just a distribution which does a good job mapping X to the z’s that can produce X. Since we’re interested in inferring P(X), it makes sense to construct a Q which does depend on X, and in particular, one which makes D [Q(z)k|P(z|X)] small
翻译一下意思就是: X X X是固定的(因为它是样本集),Q也可是任意分布,并非仅是能够生成 X X X的分布,因为我们想推断 P ( X ) P(X) P(X),那么构建一个依赖于 X X X的 Q Q Q分布是可行的,还能让 K L ( Q ( z ) ∣ ∣ P ( z ∣ X ) ) KL(Q(z)||P(z|X)) KL(Q(z)∣∣P(z∣X))较小:
log p ( x ) − K L ( q ( z ∣ x ) ∣ p ( z ∣ x ) ) = E z ∼ q [ log p ( x ∣ z ) ] − K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) \log p(x)-KL(q(z|x)|p(z|x))=E_{z\sim q}[\log p(x|z)]-KL(q(z|x)||p(z)) logp(x)−KL(q(z∣x)∣p(z∣x))=Ez∼q[logp(x∣z)]−KL(q(z∣x)∣∣p(z))
这个式子就是变分自编码的核心了
这样我们就知道了优化目标(等号右边的时候),我们看看变换后的式子为什么能够计算?
首先没了 p ( z ∣ x ) p(z|x) p(z∣x),其次每一项都能计算,我们挨个来看:
-
如何计算 q ( z ∣ x ) q(z|x) q(z∣x)?
我们可以使用神经网络逼近 q ( z ∣ x ) q(z|x) q(z∣x),假设 q ( z ∣ x ) q(z|x) q(z∣x)服从高斯分布 N ( μ , σ ) N(\mu,\sigma) N(μ,σ)- 神经网络的输出就是均值 μ \mu μ和方差 σ \sigma σ
- 输入是图片,输出是分布
计算 q ( z ∣ x ) q(z|x) q(z∣x)就是编码过程了
-
如果计算 p ( x ∣ z ) ? 用 一 个 神 经 网 络 去 逼 近 p(x|z)? 用一个神经网络去逼近 p(x∣z)?用一个神经网络去逼近p(x|z) , 假 设 神 经 网 络 输 出 是 ,假设神经网络输出是 ,假设神经网络输出是f(z)$
假设 p ( x ∣ z ) p(x|z) p(x∣z)服从另一种高斯分布- x = f ( z ) + η x=f(z)+\eta x=f(z)+η,其中 η ∼ N ( 0 , I ) \eta\sim N(0,I) η∼N(0,I)
- 简化成 l 2 l_2 l2损失: ∣ ∣ X − f ( z ) ∣ ∣ 2 ||X-f(z)||^2 ∣∣X−f(z)∣∣2
计算 p ( x ∣ z ) p(x|z) p(x∣z)就是解码过程了
最终损失就是
L = ∣ ∣ X − f ( z ) ∣ ∣ 2 − λ ⋅ K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) L=||X-f(z)||^2-\lambda\cdot KL(q(z|x)||p(z)) L=∣∣X−f(z)∣∣2−λ⋅KL(q(z∣x)∣∣p(z))
在这里,我们先不看这个最终损失的式子,我们去瞅瞅未经过 l 2 l_2 l2简化的的优化目标
E L B O = E z ∼ q [ log p ( x ∣ z ) ] − K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) ELBO=E_{z\sim q}[\log p(x|z)]-KL(q(z|x)||p(z)) ELBO=Ez∼q[logp(x∣z)]−KL(q(z∣x)∣∣p(z))
-
计算第二项的
KL散度
我们经常选择 q ( z ∣ x ) = N ( z ∣ μ ( x ; θ ) , Σ ( x ; θ ) ) q(z|x)=N(z|\mu(x;\theta),\Sigma(x;\theta)) q(z∣x)=N(z∣μ(x;θ),Σ(x;θ)),这里面 μ , Σ \mu,\Sigma μ,Σ通常是任意确定的函数,且其参数 θ \theta θ能够从数据中学习。通常通过神经网络获取,并且 Σ \Sigma Σ被限制为一个对角阵。这样选择的好处是便于计算,仅此而已,那么右边的 K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) KL(q(z|x)||p(z)) KL(q(z∣x)∣∣p(z))就编程了两个多元高斯分布的KL距离,有闭式解为:
D ( N ( μ 0 , Σ 0 ) ∣ ∣ N ( μ 1 , Σ 1 ) ) = 1 2 ( t r ( Σ 1 − 1 Σ 0 ) + ( μ 1 − μ 0 ) T Σ 1 − 1 ( μ 1 − μ 0 ) − k + log ( det Σ 1 det Σ 0 ) D(N(\mu_0,\Sigma_0)||N(\mu_1,\Sigma_1))=\\ \frac{1}{2}\left(tr(\Sigma^{-1}_1\Sigma_0\right)+(\mu_1-\mu_0)^T\Sigma_1^{-1}(\mu_1-\mu_0)-k+\log(\frac{\det \Sigma_1}{\det \Sigma_0}) D(N(μ0,Σ0)∣∣N(μ1,Σ1))=21(tr(Σ1−1Σ0)+(μ1−μ0)TΣ1−1(μ1−μ0)−k+log(detΣ0detΣ1)
其中 k k k是分布的维数,而在变分推断中,经常又被简化成
D ( N ( μ ( x ) , Σ ( x ) ) ∣ ∣ N ( 0 , I ) ) = 1 2 ( t r ( Σ ( x ) ) + ( μ ( x ) ) T ( μ ( x ) ) − k + log det ( Σ ( x ) ) D(N(\mu(x),\Sigma(x))||N(0,I))=\\ \frac{1}{2}\left(tr(\Sigma(x)\right)+(\mu(x))^T(\mu(x))-k+\log\det(\Sigma(x)) D(N(μ(x),Σ(x))∣∣N(0,I))=21(tr(Σ(x))+(μ(x))T(μ(x))−k+logdet(Σ(x)) -
计算第一项 E z ∼ q E_{z\sim q} Ez∼q
论文中说这一项的计算有点小技巧(tricky),本来是可以通过采样的方法估计 E z ∼ q ( log p ( x ∣ z ) ) E_{z\sim q}(\log p(x|z)) Ez∼q(logp(x∣z)),但是只有将很多的 z z z通过 f f f式子(解码部分)输出以后才能得到较好的估计结果,这个计算量很大,因此想到了随机梯度下降,我们可以拿一个样本 z z z,将 p ( x ∣ z ) p(x|z) p(x∣z)作为 E z ∼ q ( log p ( x ∣ z ) ) E_{z\sim q}(\log p(x|z)) Ez∼q(logp(x∣z))的估计,所以式子又变成了:
E x ∼ D ( log p ( x ) − K L ( q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) ) = E x ∼ D [ E z ∼ q [ log p ( x ∣ z ) ] ] − K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) E_{x\sim D}(\log p(x)-KL(q(z|x)||p(z|x)))=\\ E_{x\sim D}\left[E_{z\sim q}\left[\log p(x|z)\right]\right]-KL(q(z|x)||p(z)) Ex∼D(logp(x)−KL(q(z∣x)∣∣p(z∣x)))=Ex∼D[Ez∼q[logp(x∣z)]]−KL(q(z∣x)∣∣p(z))
意思就是我们从样本集合 D D D中取一个样本 x x x来计算,所以对于单个,可以计算下式梯度:
log p ( x ∣ z ) − K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) \log p(x|z)-KL(q(z|x)||p(z)) logp(x∣z)−KL(q(z∣x)∣∣p(z))
这样消除了 E z ∼ q E_{z\sim q} Ez∼q中对 q q q的依赖。论文中有个图很好

其实 log p ( x ∣ z ) − K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) \log p(x|z)-KL(q(z|x)||p(z)) logp(x∣z)−KL(q(z∣x)∣∣p(z))刚好就是左图,主要就是反传的时候没法计算梯度,看左图红框部分,这一部分是随机采样,是无法计算梯度的,那么文中就说了一个技巧:重新参数化(reparameterization trick),给定了 μ ( x ) , Σ ( x ) \mu(x),\Sigma(x) μ(x),Σ(x)也就是 Q ( z ∣ x ) Q(z|x) Q(z∣x)的均值和方差,我们先从 N ( 0 , I ) N(0,I) N(0,I)中采样,然后计算 z = μ ( x ) + Σ 1 2 ∗ ϵ z=\mu(x)+\Sigma^{\frac{1}{2}}*\epsilon z=μ(x)+Σ21∗ϵ,所以我们又可以计算下式的梯度了:
E x ∼ D [ E ϵ ∼ N ( 0 , I ) [ log p ( x ∣ z = μ ( x ) + Σ 1 / 2 ( x ) ∗ ϵ ) ] − K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) ] E_{x\sim D}\left[E_{\epsilon\sim N(0,I)}\left[\log p(x|z=\mu(x)+\Sigma^{1/2}(x)*\epsilon)\right]-KL(q(z|x)||p(z)) \right] Ex∼D[Eϵ∼N(0,I)[logp(x∣z=μ(x)+Σ1/2(x)∗ϵ)]−KL(q(z∣x)∣∣p(z))]
这就完成了从左图到右图的转变。
代码实现-模型训练及保存
理论很复杂,但是我们看着右图就能实现,无需看理论,理论只是让我们知道为什么会有右图这种网络结构。按照标准流程来书写代码:
- 读数据
- 初始化相关参数
- 定义数据接收接口以便测试使用
- 初始化权重和偏置
- 定义基本模块:编码器、采样器、解码器
- 构建模型
- 定义预测函数、损失函数、优化器
- 训练
整个代码很简单,我就只贴部分重点的:
初始化权重偏置
#初始化权重、偏置
def glorot_init(shape):
return tf.random_normal(shape=shape,stddev=1./tf.sqrt(shape[0]/2.0))
#权重
weights={
'encoder_h1':tf.Variable(glorot_init([num_input,hidden_dim])),
'z_mean':tf.Variable(glorot_init([hidden_dim,latent_dim])),
'z_std':tf.Variable(glorot_init([hidden_dim,latent_dim])),
'decoder_h1':tf.Variable(glorot_init([latent_dim,hidden_dim])),
'decoder_out':tf.Variable(glorot_init([hidden_dim,num_input]))
}
#偏置
biases={
'encoder_b1':tf.Variable(glorot_init([hidden_dim])),
'z_mean':tf.Variable(glorot_init([latent_dim])),
'z_std':tf.Variable(glorot_init([latent_dim])),
'decoder_b1':tf.Variable(glorot_init([hidden_dim])),
'decoder_out':tf.Variable(glorot_init([num_input]))
}
注意这里使用了另一种初始化方法,说是Xavier初始化方法,因为直接使用上一篇博客的方法
tf.Variable(tf.random_normal([num_input,num_hidden1])),
训练时候一直给我弹出loss:nan,我也是醉了,以后还是用之前学theano时候采用的fan_in-fan_out方法初始化权重算了。
定义基本模块
注意需要定义编码器、采样器、解码器
#定义编码器
def encoder(x):
encoder=tf.matmul(x,weights['encoder_h1'])+biases['encoder_b1']
encoder=tf.nn.tanh(encoder)
z_mean=tf.matmul(encoder,weights['z_mean'])+biases['z_mean']
z_std=tf.matmul(encoder,weights['z_std'])+biases['z_std']
return z_mean,z_std
#定义采样器
def sampler(z_mean,z_std):
eps=tf.random_normal(tf.shape(z_std),dtype=tf.float32,mean=0,stddev=1.0,name='epsilon')
z=z_mean+tf.exp(z_std/2)*eps
return z
#定义解码器
def decoder(x):
decoder=tf.matmul(x,weights['decoder_h1'])+biases['decoder_b1']
decoder=tf.nn.tanh(decoder)
decoder=tf.matmul(decoder,weights['decoder_out'])+biases['decoder_out']
decoder=tf.nn.sigmoid(decoder)
return decoder
构建模型
#构建模型
[z_mean,z_std]=encoder(X)#计算均值方差
sample_latent=sampler(z_mean,z_std)#采样隐空间
decoder_op=decoder(sample_latent)#重构输出
预测函数和损失
#预测函数
y_pred=decoder_op
y_true=X
tf.add_to_collection('recon',y_pred)
#定义损失函数和优化器
def vae_loss(x_reconstructed,x_true,z_mean,zstd):
#重构损失
encode_decode_loss=x_true*tf.log(1e-10+x_reconstructed)\
+(1-x_true)*tf.log(1e-10+1-x_reconstructed)
encode_decode_loss=-tf.reduce_sum(encode_decode_loss,1)
#KL损失
kl_div_loss=1+z_std-tf.square(z_mean)-tf.exp(z_std)
kl_div_loss=-0.5*tf.reduce_sum(kl_div_loss,1)
return tf.reduce_mean(encode_decode_loss+kl_div_loss)
loss_op=vae_loss(decoder_op,y_true,z_mean,z_std)
optimizer=tf.train.RMSPropOptimizer(learning_rate=learning_rate)
train_op=optimizer.minimize(loss_op)
注意这里损失的第一项类似于交叉熵损失: y × log ( y ^ ) + ( 1 − y ) × ( 1 − log y ^ ) y\times \log(\hat{y})+(1-y)\times(1-\log \hat y) y×log(y^)+(1−y)×(1−logy^)
关于交叉熵损失和均方差损失的区别,可以看我前面的博客:损失函数梯度对比-均方差和交叉熵
训练和保存模型
#参数初始化
init=tf.global_variables_initializer()
input_image,input_label=read_images('./mnist/train_labels.txt',batch_size)
#训练和保存模型
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
coord=tf.train.Coordinator()
tf.train.start_queue_runners(sess=sess,coord=coord)
for step in range(1,num_steps):
batch_x,batch_y=sess.run([input_image,tf.one_hot(input_label,1,0)])
sess.run(train_op,feed_dict={X:batch_x})
if step%disp_step==0 or step==1:
loss=sess.run(loss_op,feed_dict={X:batch_x})
print('step '+str(step)+' ,loss '+'{:.4f}'.format(loss))
coord.request_stop()
coord.join()
print('optimization finished')
saver.save(sess,'./VAE_mnist_model/VAE_mnist')
常规的保存方法,没什么说的,训练日志:
step 1 ,loss 616.3002
step 1000 ,loss 169.6044
step 2000 ,loss 163.5006
step 3000 ,loss 166.1648
step 4000 ,loss 161.2366
step 5000 ,loss 155.1714
step 6000 ,loss 153.2840
step 7000 ,loss 161.5571
step 8000 ,loss 152.0021
step 9000 ,loss 159.5550
step 10000 ,loss 154.6315
step 11000 ,loss 153.8298
step 12000 ,loss 141.5825
step 13000 ,loss 149.7792
step 14000 ,loss 150.9575
step 15000 ,loss 151.2249
step 16000 ,loss 159.3878
step 17000 ,loss 148.7136
step 18000 ,loss 148.5801
step 19000 ,loss 150.6678
step 20000 ,loss 146.3471
step 21000 ,loss 156.4142
step 22000 ,loss 148.7607
step 23000 ,loss 145.4101
step 24000 ,loss 153.3523
step 25000 ,loss 157.8997
step 26000 ,loss 136.9668
step 27000 ,loss 155.7835
step 28000 ,loss 137.7291
step 29000 ,loss 153.1723
optimization finished
【很尴尬的事情】偷偷说一句,上面保存错东东了,别打我,但是也不必重新训练,看接下来的蛇皮操作。
#代码实现-模型加载及测试
老样子,先载入模型
sess=tf.Session()
new_saver=tf.train.import_meta_graph('./VAE_mnist_model/VAE_mnist.meta')
new_saver.restore(sess,'./VAE_mnist_model/VAE_mnist')
获取计算图:
graph=tf.get_default_graph()
看看保存了啥
print (graph.get_all_collection_keys())
#['queue_runners', 'recon', 'summaries', 'train_op', 'trainable_variables', 'variables']
准备调用recon函数重构数据。
等等,“重构”?搞错了,这里应该是依据噪声来生成数据的,不是输入一个数据然后重构它,这是AE的做法,我们在VAE中应该称之为生成了,然而不幸的是,我们保存的recon函数接收的是图片输入,无法指定decoder部分所需的分布参数,也就是均值方差,怎么办?手动选择性载入模型,这篇博客有介绍怎么在测试阶段定义网络权重和载入训练好的权重,但是我好像没成功,懒得试了,按照我自己的想法来做。
眼尖的童鞋会发现,我们之前一直只关注recon函数了,忽视了其它keys,很快发现最后两个trainable_variables和variables貌似与我们想要的模型参数有关,我们来输出一下这两个东东里面都保存了啥:
第一个trainable_variables
for i in tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES):
print(i)
输出
<tf.Variable 'Variable:0' shape=(784, 512) dtype=float32_ref>
<tf.Variable 'Variable_1:0' shape=(512, 2) dtype=float32_ref>
<tf.Variable 'Variable_2:0' shape=(512, 2) dtype=float32_ref>
<tf.Variable 'Variable_3:0' shape=(2, 512) dtype=float32_ref>
<tf.Variable 'Variable_4:0' shape=(512, 784) dtype=float32_ref>
<tf.Variable 'Variable_5:0' shape=(512,) dtype=float32_ref>
<tf.Variable 'Variable_6:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'Variable_7:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'Variable_8:0' shape=(512,) dtype=float32_ref>
<tf.Variable 'Variable_9:0' shape=(784,) dtype=float32_ref>
第二个:GLOBAL_VARIABLES
for i in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES):
print(i)
<tf.Variable 'Variable:0' shape=(784, 512) dtype=float32_ref>
<tf.Variable 'Variable_1:0' shape=(512, 2) dtype=float32_ref>
<tf.Variable 'Variable_2:0' shape=(512, 2) dtype=float32_ref>
<tf.Variable 'Variable_3:0' shape=(2, 512) dtype=float32_ref>
<tf.Variable 'Variable_4:0' shape=(512, 784) dtype=float32_ref>
<tf.Variable 'Variable_5:0' shape=(512,) dtype=float32_ref>
<tf.Variable 'Variable_6:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'Variable_7:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'Variable_8:0' shape=(512,) dtype=float32_ref>
<tf.Variable 'Variable_9:0' shape=(784,) dtype=float32_ref>
<tf.Variable 'Variable/RMSProp:0' shape=(784, 512) dtype=float32_ref>
<tf.Variable 'Variable/RMSProp_1:0' shape=(784, 512) dtype=float32_ref>
<tf.Variable 'Variable_1/RMSProp:0' shape=(512, 2) dtype=float32_ref>
<tf.Variable 'Variable_1/RMSProp_1:0' shape=(512, 2) dtype=float32_ref>
<tf.Variable 'Variable_2/RMSProp:0' shape=(512, 2) dtype=float32_ref>
<tf.Variable 'Variable_2/RMSProp_1:0' shape=(512, 2) dtype=float32_ref>
<tf.Variable 'Variable_3/RMSProp:0' shape=(2, 512) dtype=float32_ref>
<tf.Variable 'Variable_3/RMSProp_1:0' shape=(2, 512) dtype=float32_ref>
<tf.Variable 'Variable_4/RMSProp:0' shape=(512, 784) dtype=float32_ref>
<tf.Variable 'Variable_4/RMSProp_1:0' shape=(512, 784) dtype=float32_ref>
<tf.Variable 'Variable_5/RMSProp:0' shape=(512,) dtype=float32_ref>
<tf.Variable 'Variable_5/RMSProp_1:0' shape=(512,) dtype=float32_ref>
<tf.Variable 'Variable_6/RMSProp:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'Variable_6/RMSProp_1:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'Variable_7/RMSProp:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'Variable_7/RMSProp_1:0' shape=(2,) dtype=float32_ref>
<tf.Variable 'Variable_8/RMSProp:0' shape=(512,) dtype=float32_ref>
<tf.Variable 'Variable_8/RMSProp_1:0' shape=(512,) dtype=float32_ref>
<tf.Variable 'Variable_9/RMSProp:0' shape=(784,) dtype=float32_ref>
<tf.Variable 'Variable_9/RMSProp_1:0' shape=(784,) dtype=float32_ref>
很容易发现我们只需要从可训练的参数集中获取权重,还记得之前说过的么,我们啥都往sess.run中丢试试,看看能不能取出来值:
a=sess.run(graph.get_collection('trainable_variables'))
for i in a:
print(i.shape)
(784, 512)
(512, 2)
(512, 2)
(2, 512)
(512, 784)
(512,)
(2,)
(2,)
(512,)
(784,)
可以看出参数可以从a中通过索引取出来了。
接下来简单,重新定义一下模型的decoder计算:
latent_dim=2
noise_input=tf.placeholder(tf.float32,shape=[None,latent_dim])
decoder=tf.matmul(noise_input,a[3])+a[8]
decoder=tf.nn.tanh(decoder)
decoder=tf.matmul(decoder,a[4])+a[9]
decoder=tf.nn.sigmoid(decoder)
然后就可以尝试丢进去一个均值和方差去预测了:
generate=sess.run(decoder,feed_dict={noise_input:[[3,3]]})
可视化
generate=generate*255.0
gen_img=generate.reshape(28,28)
plt.imshow(gen_img)
plt.show()
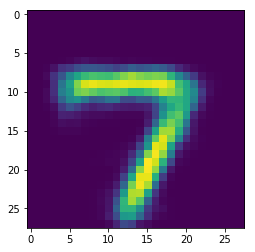
效果还不错,再测试几个,丢 [ 0 , 0 ] [0,0] [0,0]试试:

丢 [ 0 , 5 ] [0,5] [0,5]试试:

好了,不玩了,随机性太大了,我都不知道啥噪声能输出啥数字,只有输出的时候才知道。
后记
好玩是好玩,但是我不知道哪个数字对应哪种噪声输入,还是有点郁闷,下一篇我们就去看看有名的搞基网GAN
本文训练代码:链接:https://pan.baidu.com/s/19QSNfT7fgWrU68CV7lXSZA 密码:6c7l
本文测试代码:链接:https://pan.baidu.com/s/1CAxPGnmCTg-OT8TqnXQdVw 密码:tmep