OpenPano:如何编写一个全景拼接器
本文全文翻译自http://ppwwyyxx.com/2016/How-to-Write-a-Panorama-Stitcher/。这是一个关于作者如何编写OpenPano算法的一个总结,OpenPano是一个开源的全景拼接软件。相关代码在github上。
SIFT Feature
Lowe 的SIFT[1]算法实现放在feature/目录下。这个算法的流程和一些结果在这一章里做简单的介绍。
Scale Space & DOG Space
首先,一个尺度空间(Scale Space)由 S×O 个灰度尺度图组成。最初的图片被调整成 O 种不同大小(即层级,octaves),每一层加上 S 个不同的 σ 高斯模糊。由于不同大小尺寸的图片上检测特征点,这些特征点将具备尺度不变性。
高斯模糊通过两个一维卷积实现,而不是一个二维卷积。这将显著地加速该计算过程。
在每个层级(octave),计算每两个相邻的高斯模糊后图片的差值,可以构建一个差分高斯空间(DOG)。DOG空间由 (S−1)×O 个灰度图组成。

Extrema Detection
在DOG空间中,通过比较相邻的三个方向26个像素来检测所有的极大或极小值: x,y,σ 。
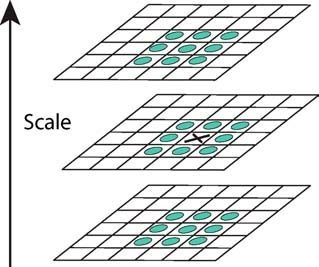

然后使用抛物线插补(parabolic interpolation)去搜索极值精确的 (x,y,σ) 。为了得到更优良的特征点,低对比度(设定DOG图像中的阈值像素值)和边缘点(设定主曲率阈值)不被接受。结果如下:

Orientation Assignment
首先,在尺度空间计算每个点的梯度和方向。在之前的流程中检测到的每个关键点,根据他们的梯度幅度值作为权重,将它的相邻点的方向将累积起来并建立一个方向直方图,权重由它们的梯度的幅度决定,
Descriptor Representation
Lowe建议[1]选择关键点附近的16点来为每个店建立一个方向直方图并且合成为一个SIFT特征。每个直方图使用8个从0到360度的不同的格子。一次结果特征是一个128位浮点向量。因为每个关键点的主方向是已知的,利用相对于主方向的相对方向,这个特征是旋转不变的。
利用论文[2]的建议,利用一个简单修改的SIFT——RootSIFT,鲁棒性更强。
Feauture Matching
这个128维描述子的欧氏距离是两幅图之间特征匹配的距离标尺。如果一个点和他最近邻和次近邻的点之间的距离是相似的会被认定是不可信的而被拒绝。一次匹配的结果如下:

特征匹配被认为是最耗时的一步。所以我使用FLANN library去特征向量中查询两个最临近特征。Intel SSE intrinsics被用来加速去计算两个特征向量的欧氏距离。
Transformation Estimation
Estimate from Match
众所周知,对于任意两幅相机在固定点拍摄的图片,匹配对的齐次坐标都能够由一个单应变换矩阵联系起来,因此对于一对对应的点 p=(x,y,1),q=(u,v,1) ,我们能够得到
单应矩阵是一个不考虑尺度影响的 3×3 矩阵。它有下面的两种可能的方程:
当拍摄两幅图片时,相机仅存在平行于成像平面的旋转和平移变换时(没有视角申缩),那么它们能够通过一个仿射变换矩阵联系起来:
给定一组匹配点,以上的任何一个方程都能够通过直接线性变换(Direct Linear Transform)估计出来。这些估计方法的实现放在
lib/imgproc.cc中。具体参照 [3]
然而这些方法对于噪声的鲁棒性并不强。实际上,由于错误匹配对的存在,RANSAC(Random Sample Consensus)算法[4]经常被用来在变矩阵的求解中剔除噪声。在RANSAC的每一步迭代中,几组匹配点对被随机地选择用来生成一个最佳的变换矩阵,并且和该矩阵一致的点对被看做是内点。在一定量的迭代后,拥有最多内点对的变换被看做最后的结果。该算法实现放在stitch/transform_estimate.cc中。
Match Validation
在每次矩阵估计后,我对每个矩阵进行了优劣检查(health check),以避免因为错误的匹配对而产生畸变的变换估计。这个过程包括两种检查:(具体参见stitch/homography.hh中)
- 单应变换 (H3,1,H3,2) 中的尺度参数不能太大。他们的绝对值应不能超过0.002。
- 跳动不能够出现在图像拼接过程中。如果
x或y坐标发生了跳动那么这个单应变换是不能够被接受的。
再无限制地拼接中,有必要判断两幅图是否匹配。上面流程中估计得到的大量内点能够作为一个评判尺度。然而,对于高分辨率图片,即使执行了足够多次的RANSAC迭代,也有可能实际上得到了一个有着大量内点的错误匹配。为了解决这个问题,考虑到错误匹配在空间上通常是更加随机分布的,通过设置匹配之间的几何限制条件能够帮助找出错误匹配对出来。因此,在RANSAC完成后会返回一组内点,按照论文[5]中的建议,可以通过一些重叠检测来进一步验证匹配情况。
特别的,知道了一个候选的变换矩阵,通过计算变换对应角点的凸包,我能够找出两幅图之间的重叠区域。在重叠区域被找到后就可以应用两个滤波器了。
- 两幅图的重叠区域不能够区别太大。
- 在重叠区域内,应该有足够大比例的匹配点对是内点。我使用了内点率来描述该匹配的置信度。
由于错误的匹配可能是随机和无规律的,这种方法能够帮助滤除带有错误几何信息的误匹配对。
Cylindrical Panorama
Necessity of Projection
给出一个单向的旋转变换照片输入,按照大多数全景拼接软件的做法,采用平面单应变换会导致垂直畸变,如下图:

这是因为全景实际上是通过柱面或者球面镜投拍摄得到,而并不再试平面镜头。在这种配置下,照片中草地上的面色圆圈其实一条直线。一个很好地解释了这种投影生成原因的demo见此页面。
处理这种问题的方式是在变换估计之前或者之后,通过柱面或者球面投影去畸变图片。这和本系统中的两种模式相对应。在这一节中我们将引入基于pre-warping的流水线方式,它被应用在柱面模式中。尽管需要很多的假设和一些技巧去是它良好的工作,这种流水线方式通常很好。它的实现放在stitch/cylstitcher.cc目录中。
Warp
我们在拼接的一开始,先将图片投影到柱面,方程如下:
f 是相机焦距, xc , yc 是图像的中心。详见stitch/warp.cc。一些畸变后的示例图片如下图。注意这要求提前知道相机的焦距,否则不会产生一个好的弯曲结果。



在将所有的图片投影到了相同的柱面上后,可以通过估计图片对之间的仿射变换来简单的拼接图片。并且通过选定一张特定的图片作为主图进行叠加。注意到操场上的白色线变得更直了。

straightening
由于相机的倾斜角度是未知的,上面描述的柱面投影是假设相机是水平的。这个假设会导致扭曲,输出的全景图可能会是弯曲的:

选择中间的图片作为基准有助于解决该问题。我发现了另一种有效地方法,这种方法通过搜索畸变方程中的 yc 来降低弯曲效应。
由于这种结果是因为相机的倾斜造成的, yc 可能因 height2 而不同。该算法通过对分 yc ,找到能使得结果图中出现的最佳直线的值。经过这个过程后,结果如下:

单独改变 yc 是不够的,因为我们还是将图片畸变到了一个垂直的柱面上。如果所有的相机拥有共同的倾斜角度,那么真实的投影面应该是一个圆锥面。这种错误能够上述图片边界的左边和右边观察到。为了解释这个错误,我最后使用了视角变换的方式去对准左边和右边的边界。

Camera Estimation Mode
Intuition
使用柱面投影去扭曲图像到圆柱表面时,假设已知相机焦距并且要求所有相机有同样的倾角向量。我们想要摆脱这些约束。
然而,如果只是简单地估计成对的单应变换,去直接拼接它们,在变换后投影大柱面上,将会得到类似于下图的结果:

注意到图片实际上拼接的很好:匹配点对都很好地重叠了。但是整体的几何结构被破坏了。
这是因为 H 和真实的几何限制是不一致的,所以估计得到的 H 不可能是 K1R1RT2K−12 中的一种。换句话说,我们估计得到的 H 是一个忽略尺度因子的 3×3 矩阵,但不是所有的 R3×3 空间的矩阵都是合法的变换矩阵,尽管他们可能和这些点匹配。或者说,一个变换具有此种服从该方程是必要的,但不是充分的。
而且,注意刀 H 不是最小化参数:假设所有相邻的图片对和第一(或最后)的图片对被用来估计 n 个单应变换矩阵 H 。那么我们需要估计 8n 个参数。然而,每个相机有3个外部参数(旋转参数)和一个内部参数(相机焦距)。总共的自由度是 4n 。如果所有的相机都有相同的焦距那么自由度(DOF)将会更小。
相机参数的这种不一致的过度参数化将会导致上述这种过拟合的结果出现,因而打乱了图片潜在的内部几何结构。
人们通常用 H 来开始,因为该估计就是简单的线性代数问题。但是为了得到相机所有正确的 K,R 估计,基于梯度的非线性迭代优化方法是很有效的。在匹配视觉领域被称之为捆绑调整(bundle-adjustment),通过一个简单的初始化估计紧接着又LM算法更新迭代。
Initial Estimation
[6]首先给出了一种粗略估计所有相机焦距的方法。在给出了一张图片所有的焦距和旋转矩阵后,相对应图片的旋转矩阵可以通过我们已经得出的单应变换求得:
因此,该估计算法原理类似于最大生成树算法:在建立一种匹配图后,我首先选择一张有着好的连接性质的图作为基准。然后,在每一步中,选择一张还未被处理的最佳匹配图片(考虑匹配置信度)那么它的旋转矩阵 R 能够被粗略地估计出来。基于以上的粗略估计,所添加的相机都通过捆绑调整被全局矫正,具体方法将在下一节中讲解。该流程的实现存放在
stitch/camera_estimate.cc文件中。
注意到,由于单应变换 H12 是参数化不一致的,通过上面的方程计算得到的结果 R 可能不是一个合适的旋转矩阵。因此我实际上采用了范数最小的旋转矩阵。比较规范的说就是,给出 H12,Ki,R2 ,我们计算:
如果不执行捆绑调整,由于初始估计的 K 和 R 都存在误差,拼接的结果将无法对其,看起来如下图:

为了进一步的改善 K 和 R 中的参数是的匹配点对能够较好的对齐,有必要进行一致化参数优化。
Bundle Adjustment
我们通过如下方式规定 K 和 R 中的参数:
这里, R=e[u]× 是旋转矩阵的角度坐标参数化形式。令 θ 是系统中所有参数组成的一个向量。我们的目标是最小化所有匹配点对的重投影误差:
pij 表示图片 j 中的点 Xj 到图片 i 的2D投影,并且需要满足 K 和 R 的限制条件: p ij≡KiRiRTjK−1jX^j 上述求和过程包含了所有之前添加到捆绑调节器的所有图片的匹配点对。注意到当拼接一组无序的图片时,一张图片坑和许多图片匹配。这些匹配集能够帮助捆绑调节器来改善拼接质量。
一些迭代方法例如牛顿法,梯度下降法,levenberg-Marquardt算法,都能够被用来解决这个优化问题。假定矩阵 J=∂r∂θ ,这里 r 是所有代表平均平方误差的残差组成的向量: r=(Xi−pij,...) ,上面提到的三种优化方法求解方程如下:
- 梯度下降法: ∇θ=λJTr
- 牛顿法: ∇θ=(JTJ)−1JTr
- LM算法: ∇θ=(JTJ+λD)−1JTr,且D是对角矩阵
所有的迭代算法都涉及到计算矩阵 J .它可以通过数值方法求得,又可以通过符号方式表示出来。
- 数值:对于每一个 θi ,振幅为 ±ϵ ,分别计算 r1,r2 。然后计算 J[:,i]=r1−r22ϵ
- 符号:根据微分运算的链式法则计算 ∂r∂θ 。比如,相关的方程如下:
∂rk∂pij=−1,若rk=Xi−pij.否则为0
∂pij∂p^ij=∂[xzyz]∂[x y z]=⎡⎣⎢⎢1z001z−xz2−yz2⎤⎦⎥⎥
∂p^ij∂fi=∂Ki∂uiRiRTjK−1jXj
∂p^ij∂ui=Ki∂Ri∂uiRTjK−1jXj
∂p^ij∂uj=KiRi(∂Rj∂ui)TRTjK−1jXj
∂K∂f=⎡⎣⎢100010000⎤⎦⎥
∂R∂ux=ux[u]x+[u×(I−R)ex]×||u||2R
最后一个方程来自于[7]。并且,我发现Lowe的论文[5]给出的方程是错误的:
由于 eA 不是按元素取指数而是按矩阵指数,所以这个等式是不成立的。
两种方法的实现都存放在stitch/incremental_bundle_adjuster.cc。由于符号方式仅仅计算稀疏矩阵 J 中的非零元素,所以它的计算速速更快,并且也允许我们在计算 J 的过程中同时计算 JTJ ,而不需要大量的矩阵乘法运算。
在一组 n 张图片集李,当图片被添加进去后,优化算法需要运行 n−1 次。当在最后5次迭代后误差不再下降后优化过程停止。
在优化后,上面的前景图看起来将会更好:

Straightening
校直也是有必要的。按照论文[5]中建议的方式,由于相机倾角不明确,捆绑调整后的结果可能仍然存在波动现象。若假定所有相机的 X 向量位于同一平面(这是可能的),我们估计出一个正交于该平面 Y 向量
来解决倾角和修复这种波动效应。
对比上面两张图,注意到草地上的直线被纠正了(它实际上是足球场上中心的一个圆)。


Blending
在完成所有的变换之后最终图片结果的大小就确定了。然后结果图片中的每个像素点的值通过逆变换和相邻区域像素点的双线性插值(可以消除锯齿现象)确定。
对于重叠区域,每个重叠像素到图像中心的距离被用来计算像素值的权值和。为了得到更好的全景图,我仅仅使用了 x 轴方向的距离去计算权重。结果几乎是无缝连接的(见上图)。
Cropping
当设置好了CROP选项后,程序将从原始结果上找到一张最大的合法矩形。
我们使用的算法复杂度为 O(n×m) ,其中 n,m 是原始结果的长宽。算法工作如下:
对于每一行 i ,
对于每一个 j∈[0,n) 都能够被摊分为 O(1) 的时间复杂度,第一个 i 行的最大可能区域,会是 (r[j]−l[j]+1)×h[j] 。



参考文献
[1]: Distinctive Image Features From Scale-invariant Keypoints, IJCV04
[2]: Three Things Everyone Should Know to Improve Object Retrieval, CVPR2012
[3]: Multiple View Geometry in Computer Vision, Second Edition
[4]: Random Sample Consensus: a Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography, Comm of ACM, 1981
[5]: Automatic Panoramic Image Stitching Using Invariant Features, IJCV07
[6]: Construction of Panoramic Image Mosaics with Global and Local Alignment, IJCV00
[7]: A Compact Formula for the Derivative of a 3-D Rotation in Exponential Coordinates, arxiv preprint