RCFile
RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对(Key/Value Pairs)数据文件。
关键词:Record、Columnar、Key、Value。
RCFile的优势在哪里?适用于什么场景?为了让大家有一个感性的认识,我们来看一个例子。
假设我们有这样一张9行3列的Hive数据表table,以普通的TextFile进行存储,

现在我们需要统计这张数据表的第二列(col2)值为“row5_col2”的出现次数,我们通常会这样写SQL:
select count(*) from table where col2 = 'row5_col2'
这条Hive SQL转换为相应的MapReduce程序执行时,虽然我们仅仅只需要查询该表的第2列数据即可得出结果,但因为我们使用的是TextFile存储格式,不得不读取整张数据表的数据参与计算。虽然我们可以使用一些压缩机制优化存储,减少读取的数据量,但效果通常不显著,而且毕竟读取了很多无用的数据(col1、col3)。
再来看一下RCFile会如何存储这张数据表的数据?宏观上大致可以分为以下三步:
(1)水平划分;

经过水平划分之后的各个数据块称之为Row Split或Record。
(2)垂直划分;

每一个Row Split或Record再按照“列”进行垂直划分。
(3)列式存储;
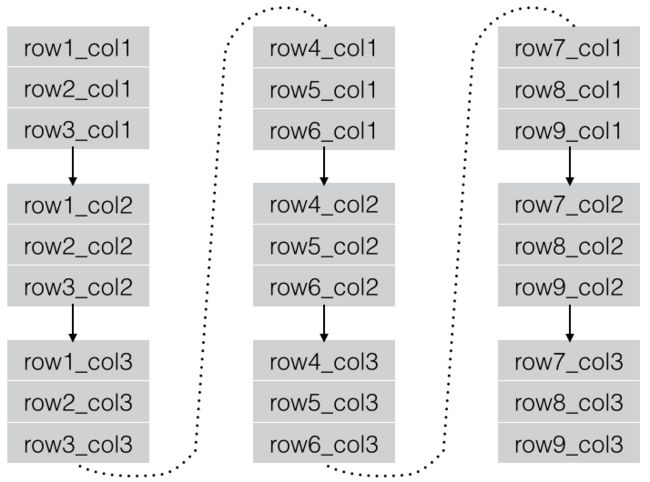
RCFile以Record为单位进行存储。
Record存储数据时,首先存储该Record内第一列的全部数据、然后存储该Record内第二列的全部数据、…、依次将各列数据存储完毕,然后继续下一个Record的存储。
Record实际由Key、Value两部分组成,其中Key保存着Record的元数据,如列数、每列数据的长度、每列数据中各个列值的长度等;Value保存着Record各列的数据。实际上Record Key相当于Record的索引,利用它可以轻松的实现Record内部读取/过滤某些列的操作。
而且RCFile将“行式”存储变为“列式”存储,相似的数据以更高的可能性被聚集在一起,压缩效果更好。
要想详细掌握一个数据文件的存储格式,就必须知道数据是通过怎样的方式被写入的,读取仅仅是写入的反面而已。RCFile分别针对写入和读取提供了相应的Writer类和Reader类,本文仅仅讨论Writer类的实现。
源码分析
通常而言,RCFile文件的整个写入过程大致可以分为三步:

(1)构建RCFile.Writer实例——Writer(...)
(2)通过RCFile.Writer实例写入数据——append
(3)关闭RCFile.Writer实例——close
我们也按照这三步来分析相应的源码。
1. Writer
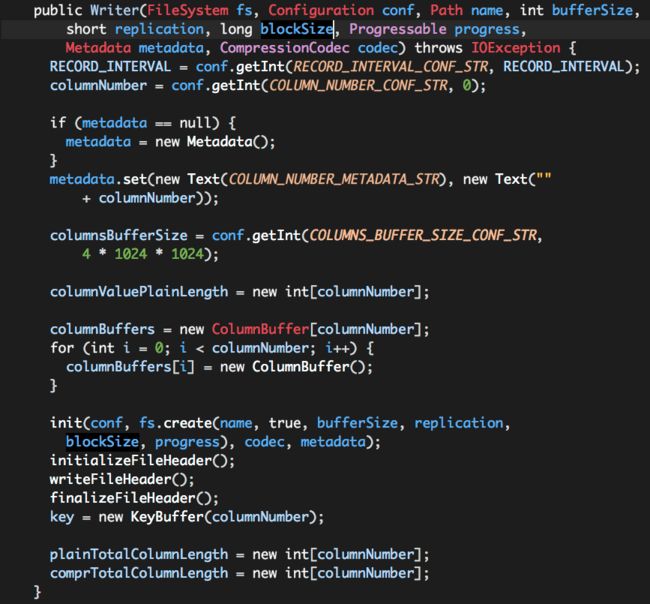
Writer在构建函数中大体做了以下三件事情:
(1)初始化一些变量值;
a. RECORD_INTERVAL:表示多少“行”数据形成一个Row Split(Record)和columnsBufferSize配合使用;
b. columnNumber:表示当前RCFile文件存储着多少“列”的数据;
c. Metadata

Metadata实例仅仅保存一个属性“hive.io.rcfile.column.number”,值为columnNumber,该实例会被序列化到RCFile文件头部;
d. columnsBufferSize:缓存数目(行数)上限阀值,超过这个数值就会将缓存的数据(行)形成一个Row Split(Record);
(2)构建一些数据结构;
a. columnValuePlainLength:保存着一个Row Split(Record)内部各列原始数据的大小;
b. columnBuffers:保存着一个Row Split(Record)内部各列原始数据;
c. key:保存着一个Row Split(Record)的元数据;
d. plainTotalColumnLength:保存着一个RCFile文件内各列原始数据的大小;
e. comprTotalColumnLength:保存着一个RCFile文件内各列原始数据被压缩后的大小;
(3)初始化文件输出流,并写入文件头部信息;
a. 初始化RCFile文件输出流(FSDataOutputStream);


useNewMagic默认值为true,本文也以此默认值进行讨论。
b. initializeFileHeader;
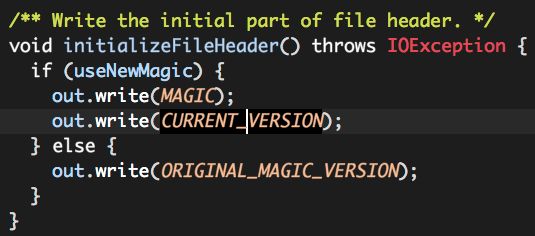
i. 写出MAGIC;
ii. 写出当前RCFile版本号(不同版本的RCFile具有不同的格式);
c. writeFileHeader;
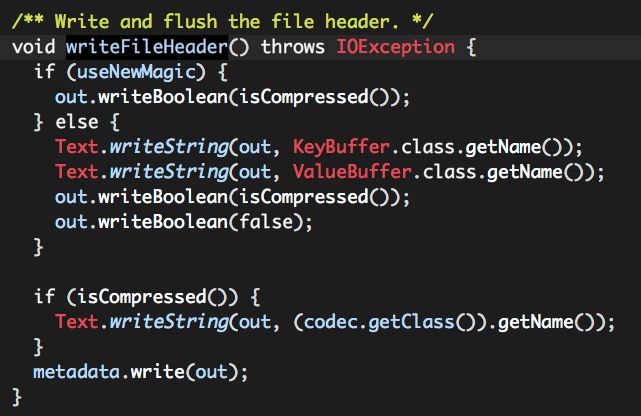
i. 写出是否使用压缩,本文按使用压缩讨论;
ii. 写出压缩编/解码器(CompressionCodec)类名;
iii. 序列化Metadata实例;
c. finalizeFileHeader;
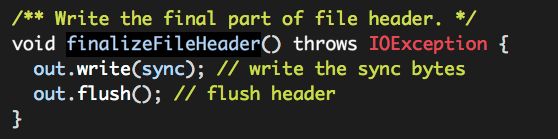
写出一个“同步标志位”,表示RCFile文件头部信息到此结束。
我们可以得出RCFile Header的结构如下:
| version | 3 bytes of magic header “RCF”, followed by 1 byte of actual version number |
| compression | A boolean which specifies if compression is turned on for keys/values in this file |
| compression codec | CompressionCodec class which is used for compression of keys and/or values |
| metadata | Metadata for this file |
| sync | A sync marker to denote end of the header |
2. append

RCFile.Writer写入数据时要求以BytesRefArrayWritable实例的形式进行“追加”,亦即一个BytesRefArrayWritable实例表示一“行”数据。
“追加”“行”数据的过程如下:
(1)从一“行”数据(即BytesRefArrayWritable实例val)中解析出各“列”数据缓存到对应的ColumnBuffer(即columnBuffers[i])中;如果这“行”数据包含的“列”小于columnNumber,则缺失的列会被填充为“空值”(即BytesRefWritable.ZeroBytesRefWritable);
我们可以看出,RCFile在“追加”数据的时候还是以“行”的方式进行,“行转列”是在内部进行转换的。转换之后的列数据(列数为columnNumber)被缓存到各自的“Buffer”中,也就是说每一列都有自己独立的缓存区(ColumnBuffer),这是为后来的“列式存储”作准备的。
这里重点介绍一下这个ColumnBuffer,它的作用就是用来缓存“列数据”的,
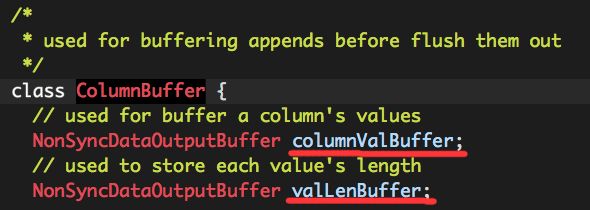
内部包含两个实例变量,如它们的变量名称所言,它们实际也是用来缓存数据的,columnValBuffer用来缓存“列值”的数据,valLenBuffer用来缓存“列值”各自的长度,这两个内部的缓存区都是NonSyncDataOutputBuffer实例。



从这三部分代码可以看出,NonSyncDataOutputBuffer内部的缓存区实际是使用内存中的一个字节数组(buf)构建的,而且继承自DataOutputStream,方便我们使用“流”的形式操作数据。
而且valLenBuffer在缓存“列值”的长度的时候,为了有效的节约存储空间,使用了一个技巧,
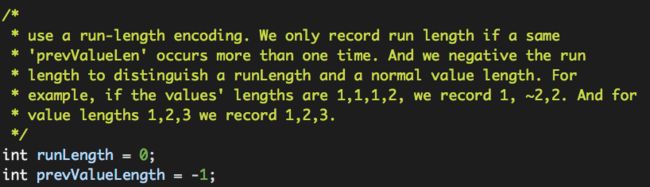
也就是说,如果需要保存的“列值”长度为“1,1,1,2”,需要存储四个整数,而且前面三个整数的值是一样的,那么我们将其变为“1,~2,2”,“~2”即表示我们需要将它前面的整数“1”重复两次。如果数据的重复度较高,这种方式会节省大量的存储空间。
(2)一“行”数据转换为多“列”数据,并被缓存到各自对应的缓存区之后,需要进行两个判断:
缓存的“列”数据(这里指columnBuffers中的全部列数据)大小是否超过上限阀值columnsBufferSize?
缓存的“行”记录数目是否超过上限阀值RECORD_INTERVAL?
如果上述两者条件满足其一,我们认为已经缓存足够多的数据,可以将缓存区的这些数据形成一个Row Split或Record,进行“溢写”。
这两个上限阀值(columnsBufferSize、RECORD_INTERVAL)也提示我们在实际应用中需要根据实际情况对这两个值进行调整。
“溢写”是通过flushRecords进行的,可以说是整个RCFile写入过程中最为“复杂”的操作。
前面提到过,RCFile Record(Row Split)实际是由Key、Value组成的,现在这些“列”数据已经被缓存到columnBuffers中,那么Key的数据在哪里呢?
这个Key实际上就是这个Row Split(Record)的元数据,也可以理解为Row Split(Record)的索引,它是由KeyBuffer表示的,
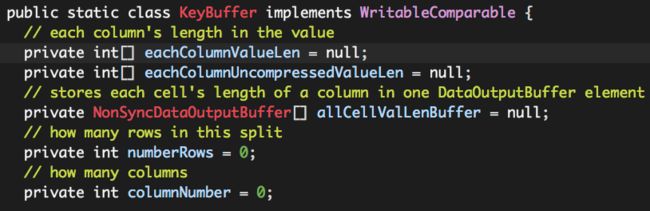
columnNumber:列数;
numberRows:RCFile Record(Row Split)内部存储着多少“行”数据,同一个RCFile文件,不同的Record内保存的行数可能不同;
RCFile Record Value实际就是前面提到的columnBuffers中的那些列值(可能经过压缩处理),这些columnBuffers的元数据由以下三个变量表示:
eachColumnValueLen:eachColumnValueLen[i]表示columnBuffers[i]中缓存的列数据(原始数据)的总大小;
eachColumnUncompressedValueLen:eachColumnUncompressedValueLen[i]表示columnBuffers[i]中的缓存的列数据被压缩之后的总大小;如果没有经过压缩处理,该值与columnBuffers[i]相同;
allCellValLenBuffer:allCellValLenBuffer[i]表示columnBuffers[i]中那些列数据各自的长度(注意前方提到的这些长度的保存技巧);
KeyBuffer被序列化之后,它的结构如下:
| numberRows | Number_of_rows_in_this_record(vint) |
| columnValueLen | Column_1_ondisk_compressed_length(vint) |
| columnUncompressedValueLen | Column_1_ondisk_uncompressed_length(vint) |
| Column_1_row_1_value_plain_length | |
| Column_1_row_2_value_plain_length | |
| ... | |
| columnValueLen | Column_2_ondisk_compressed_length(vint) |
| columnUncompressedValueLen | Column_2_ondisk_uncompressed_length(vint) |
| Column_2_row_1_value_plain_length | |
| Column_2_row_2_value_plain_length | |
| ... |
为什么说这样的元数据可以当作索引来使用呢?
注意到上面的多个columnValueLen(columnUncompressedValueLen),它保存着Record Value内多个列(簇)各自的总长度,而每个columnValueLen(columnUncompressedValueLen)后面保存着该列(簇)内多个列值各自的长度。如果我们仅仅需要读取第n列的数据,我们可以根据columnValueLen(columnUncompressedValueLen)直接跳过Record Value前面(n - 1)列的数据。
KeyBuffer的数据是在“溢写”的过程中被构建的。下面我们来详细分析flushRecords的具体逻辑。
key是KeyBuffer的实例,相当于在元数据中记录这个Row Split(Record)的“行数”;
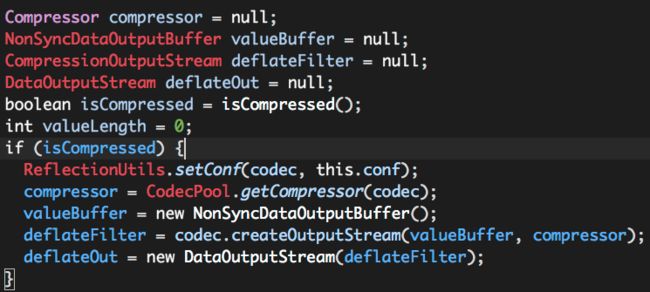
这段代码在使用压缩的场景下才有意义,它构建了一个缓存区valueBuffer,并且使用“装饰器”模式构建了一个压缩输出流,用于后期将columnBuffers中的数据写入缓存区valueBuffer,valueBuffer中的数据是压缩过的(后续会看到这个过程)。
接下来就是逐个处理columnBuffers中的数据,简要来说,对于某个columnBuffers[i]而言需要做两件事情:
(1)如果使用压缩,需要将columnBuffers[i]的数据通过压缩输出流deflateOut写入valueBuffer中;
(2)维护相关的几个变量值;
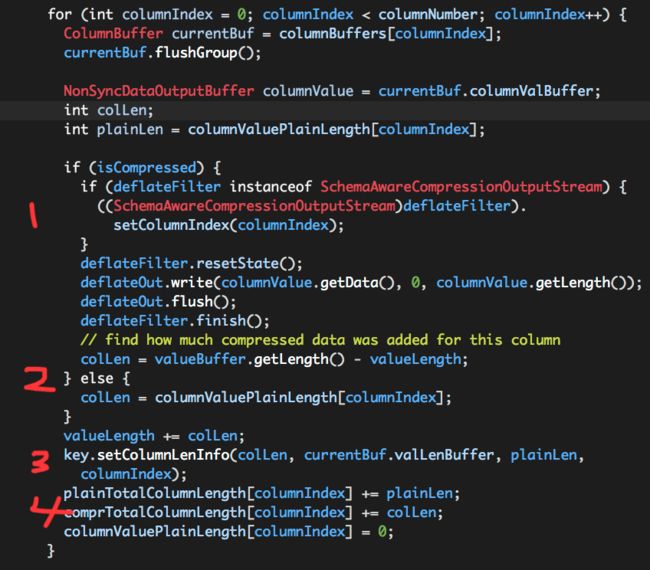
这段代码看似较长,对于某个columnBuffers[i]而言,实际做的事情可以概括为四步:
(1)如果使用压缩,将columnBuffers[i]中的全部数据写入deflateOut(实际是valueBuffer);
(2)记录columnBuffers[i]经过压缩之后的长度colLen;如果没有使用使用压缩,则该值与原始数据长度相同;
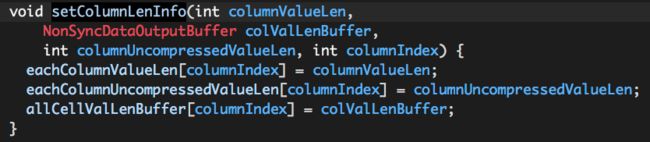
(3)记录columnBuffers[i]相关元数据:columnBuffers[i]压缩/未压缩数据的长度、columnBuffers[i]中各个列值的长度;
(4)维护plainTotalColumnLength、comprTotalColumnLength;
代码至此,一个Record(Row Split)的所有元数据已构建完毕;如果启用压缩,columnBuffers中的数据已全部被压缩写入valueBuffer;接下来就是Record Key、Value的“持久化”。
(1)Write the key out

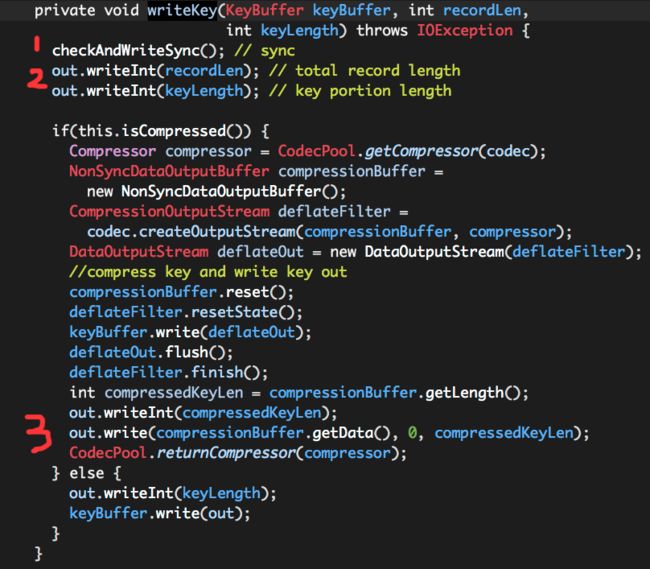
i. checkAndWriteSync

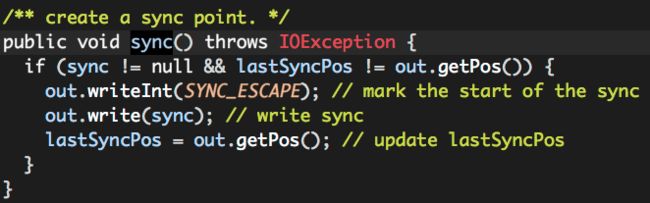
这里需要先说一下为什么需要这个“sync”?
比如我们有一个“大”的文本文件,需要使用Hadoop MapReduce进行分析。Hadoop MapReduce在提交Job之前会将这个大的文本文件根据“切片”大小(假设为128M)进行“切片”,每一个MapTask处理这个文件的一个“切片”(这里不考虑处理多个切片的情况),也就是这个文件的一部分数据。文本文件是按行进行存储的,那么MapTask从某个“切片”的起始处读取文件数据时,如何定位一行记录的起始位置呢?毕竟“切片”是按照字节大小直接切分的,很有可能正好将某行记录“切断”。这时就需要有这样的一个“sync”,相当于一个标志位的作用,让我们可以识别一行记录的起始位置,对于文本文件而言,这个“sync”就是换行符。所以,MapTask从某个“切片”的起始处读取数据时,首先会“过滤”数据,直到遇到一个换行符,然后才开始读取数据;如果读取某行数据结束之后,发现“文件游标”超过该“切片”的范围,则读取结束。
RCFile同样也需要这样的一个“sync”,对于文本文件而言,是每行文本一个“sync”;RCFile是以Record为单位进行存储的,但是并没有每个Record使用一个“sync”,而是两个“sync”之间有一个间隔限制SYNC_INTERVAL,

SYNC_INTERVAL = 100 * (4 + 16)
每次开始输出下一个Record的数据之前,都会计算当前文件的输出位置相对于上个“sync”的偏移量,如果超过SYNC_INTERVAL就输出一个“sync”。
那么这个“sync”是什么呢?
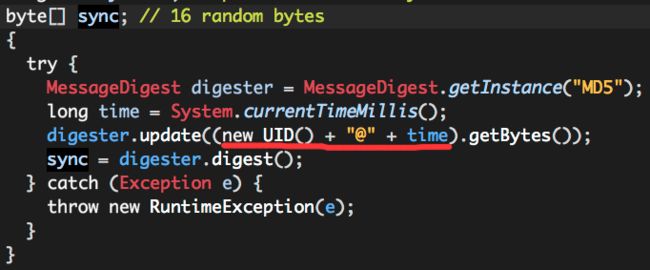
也就是说,RCFile的“sync”就是一个长度为16字节的随机字节串,这里不讨论UID的生成过程。
ii. write total record length、key portion length

iii. write keyLength、keyBuffer
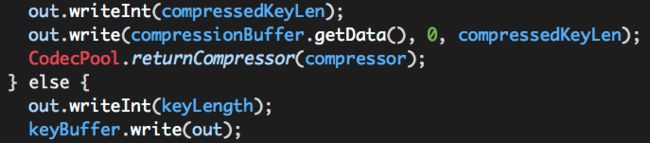
注意这里的keyLength与ii中的keyLength不同:ii中的keyLength相当于记录的是keyBuffer原始数据的长度;而iii中的keyLength相当于记录的是keyBuffer原始数据被压缩之后的长度,如果没有压缩,该值与ii中的keyLength相同。
在这块代码之前,还涉及到一个对keyBuffer的压缩过程(如果启用压缩),它与ColumnBuffer的压缩过程是类似的,不再赘述。
从上面的代码可以看出,在Record Key(KeyBuffer)之前,还存在这样的一个结构,相当于Record Header:
| recordLen | Record length in bytes |
| keyLength | Key length in bytes |
| compressedKeyLen | Compressed Key length in bytes |
(2)Write the value out
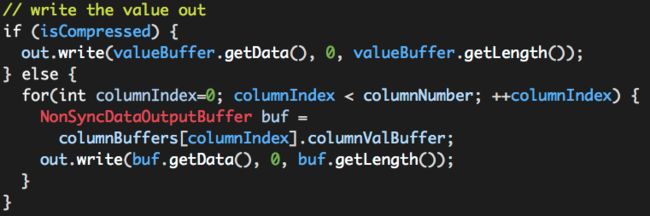
如果启用压缩,直接写出valueBuffer中的压缩数据即可;如果未启用压缩,需要将columnBuffers中的数据逐个写出。
RCFile Record Value的结构实际上就是各个“列簇”的列值,如下:
| column_1_row_1_value |
| column_1_row_2_value |
| ... |
| column_2_row_1_value |
| column_2_row_1_value |
| ... |
代码至此,我们就完成了一个Row Split(Record)的输出。
最后就是清空相关记录,为下一个Row Split(Record)的缓存输出作准备,

3. close
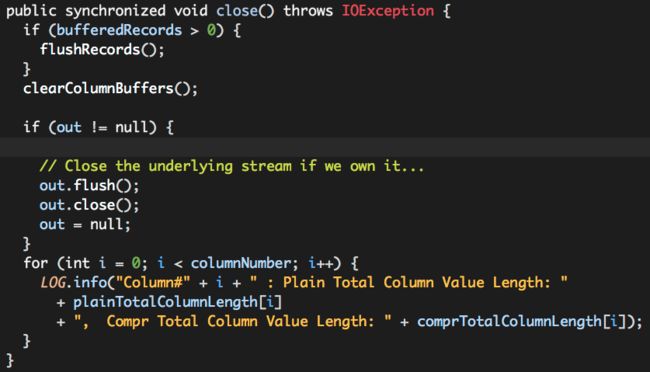
RCFile文件的“关闭”操作大致可分为两步:
(1)如果缓存区中仍有数据,调用flushRecords将数据“溢写”出去;
(2)关闭文件输出流。
代码示例
1. Write
(1)构建Writer实例;
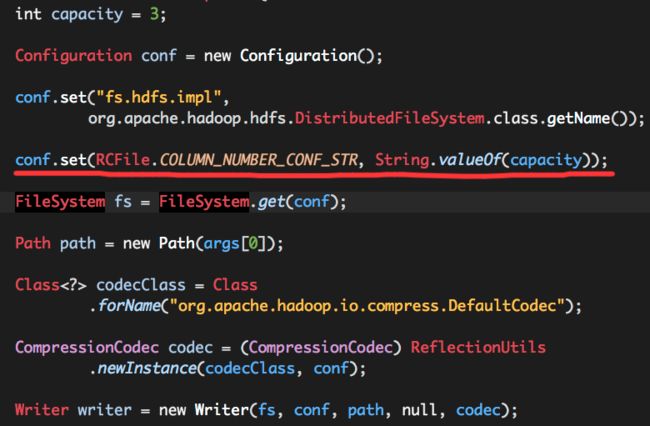
注意,一定要在Hadoop Configuration中通过属性hive.io.rcfile.column.number.conf设置RCFile的“列数”。
(2)构建多行数据;
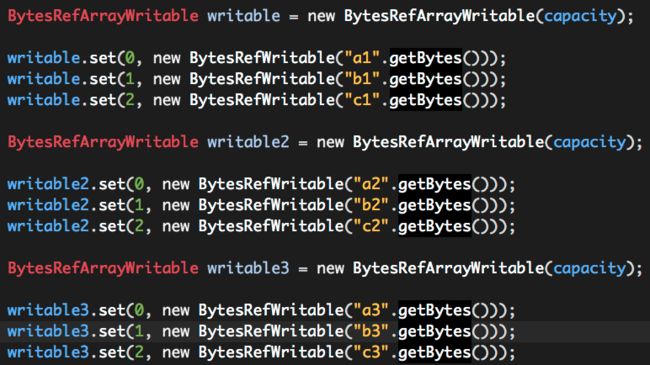
每行数据使用一个BytesRefArrayWritable实例表示。
(3)Writer append;
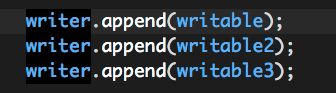
(4)Writer close;
2. Read

读取时需要注意,RCFileRecordReader的构造函数要求指定一个“切片”,如果我们需要读取整个文件的数据,就需要将整个文件打造成为一个“切片”(如上);RCFileRecordReader实例构建好之后,就可以通过next()不断迭代key、value,其中key为行数,value为行记录。
代码输出
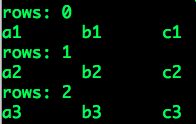
如果我们仅仅需要读取第1列和第3列的数据,应该怎么做呢?

通过这样的设置,我们可以得到如下的输出结果:

可以注意到,虽然读取的还是3列数据,但第2列的数据已经被返回“空值”。