3D点云学习:SA-SSD④源码注释
1 SASSD算法神经网络结构
SASSD在神经网络结构上的创新点主要在两点:auxiliary network 以及 PS Warp损失计算方法。这两点在代码实现上也有一定的特点,同时代码结构和论文中的网络结构也存在一定的差异。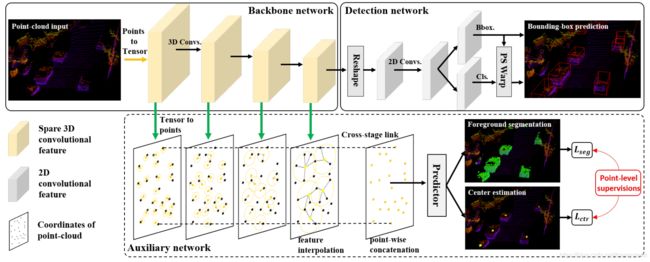
如上图所示,论文中网络主要包括三部分,Backbone network,Auxiliary network和Detection network,但在源码中,Backbone network和Auxiliary network由于其交互性较强,每一步都要互相影响,因此放到了一个部分,Detection network是另一个部分,同时损失计算也都是单独的部分。
以下前向训练图来自于 这篇博客.
2 源码注释
① mmdetection训练网络构建方法
框架作者再知乎的回答.
真个SASSD模型是基于mmdetection框架的,mmdetection框架的特点是在pytorch的基础上进行了模块化封装,从批数据处理,模型搭建,损失计算到参数最优化,都可以很方便的进行开发,用户需要做的就是写好自己的config文件和核心特征提取算法部分。SASSD的构建方法可以学习到一些mmdetection框架的使用方法。
在train.py中的训练网络构建如下:
model = build_detector(
cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)
# 分布式并行计算和单机并行计算
if distributed:
model = MMDistributedDataParallel(model).cuda()
else:
model = MMDataParallel(model, device_ids=range(cfg.gpus)).cuda()
# 将训练配置传入,其中 build_dataset()在mmdet/datasets/builder.py里实现
# get_dataset,用cfg中的参数信息,通过datasets文件夹,生成包含所有数据的一个数据集
# 再本次实例中,obj_from_dict,更有深层次的理解。根据字典型变量info去指定初始化一个parrent类对象。如果parrent类是一个虚类,
# 它会根据info的变量自动地匹配一个Matched的子类,去指定初始化这个子类的实例。
# 毫无疑问,肯定是生成datasets类子类中的KittiLiDAR类
train_dataset = get_dataset(cfg.data.train)
optimizer = build_optimizer(model, cfg.optimizer)
train_loader = build_dataloader(
train_dataset,
cfg.data.imgs_per_gpu,
cfg.data.workers_per_gpu,
dist=distributed)
start_epoch = it = 0
last_epoch = -1
lr_scheduler, lr_warmup_scheduler = build_scheduler(
optimizer, total_iters_each_epoch=len(train_loader), total_epochs=cfg.total_epochs,
last_epoch=last_epoch, optim_cfg=cfg.optimizer, lr_cfg=cfg.lr_config
)
# -----------------------start training---------------------------
logger.info('**********************Start training**********************')
train_model(
model,
optimizer,
train_loader,
lr_scheduler=lr_scheduler,
optim_cfg=cfg.optimizer,
start_epoch=start_epoch,
total_epochs=cfg.total_epochs,
start_iter=it,
rank=args.local_rank,
logger=logger,
ckpt_save_dir=cfg.work_dir,
lr_warmup_scheduler=lr_warmup_scheduler,
ckpt_save_interval=cfg.checkpoint_config.interval,
max_ckpt_save_num=args.max_ckpt_save_num,
log_interval=cfg.log_config.interval
)
logger.info('**********************End training**********************')可以看到其中调用了很多的build_XXX,build了很多模块。build_XXX的一般原理就是使用cfg文件中的超参(一般是一个dict)包括名称和参数,以及obj_from_dict函数,生成自己需要的模块。名称就代表调用的类的名称,比如type='SingleStageDetector',这样通过调用build_detector生成的detector就是class SingleStageDetector()。
在train_model中,主要部分和其他模型差不多:
model.train() # 调整到训练模式(pytorch的自带功能)
optimizer.zero_grad() # 梯度归零
outputs = batch_processor(model, data_batch) # 计算损失
outputs['loss'].backward() # 反向传播
clip_grad_norm_(model.parameters(), **optim_cfg.grad_clip) # 规范梯度大小
optimizer.step() # 优化② SingleStageDetector的前向训练部分
def forward_train(self, img, img_meta, **kwargs):
# [N,]
batch_size = len(img_meta) # B
ret = self.merge_second_batch(kwargs)
# Neck的粗糙结构如下所示:
# 输入点云 => Backbone Network => reshape 操作 => BEV Network => (x, conv6)
# ||
# || Tensor2Point (体素变点云)
# ||
# 辅助网络层 => MLP层 => point_misc
#
# 稀疏卷积 和 Reshape 和 Tensor2Point 的细节我在上一篇博客已经讨论了。
#
# 输入分析:
# vx 可以理解为 pointclpoud_range 内的点云,包含 xyz 和雷达强度项,是 (N,4).
# ret['coordinates'] 是 pointclpoud_range 内的点云体素化的结果,点对应的体素坐标
# batch_size 是批处理的大小
# 吐槽: ret['coordinates'] 才是真体素,如果我的理解有误,请大家多多指正
#
# 输出分析 :
# x, conv6 都是 BEV特征图,但是两个不同,两者中间还有一个卷积层
# point_misc = (points_mean, point_cls, point_reg) 它是个元组
# points_mean 是 bxyz 类型数据,xyz 是点云位置,b 是体素化后 z 轴分量, 它是(N,4)张量,为什么会有 b 这个分量,我也不太清楚,但是代码是这样写的
# point_cls 是点云分类结果,它是(N,1)张量,用于前景分割(可不是3d目标分类呀)
# point_reg 是点云回归结果,回归每一个3d类的中心位置,它是(N,3)张量
#
# 因为 SA-SSD 采用的是一个粗糙体素化处理方式,所以 vx 和 points_mean 的长度都是 N
vx = self.backbone(ret['voxels'], ret['num_points'])
(x, conv6), point_misc = self.neck(vx, ret['coordinates'], batch_size)
# 这里的x经过了三维卷积,大小变为了原来1/8,又经过reshape,减少了D维度,又经过二维卷积,最后(2, 256, 176, 200)
# point_misc包括了(points_mean, point_cls, point_reg),原始点云数据,语义分割结果,中心点结果
losses = dict()
aux_loss = self.neck.aux_loss(*point_misc, gt_bboxes=ret['gt_bboxes'])
losses.update(aux_loss)
# RPN forward and loss
if self.with_rpn:
rpn_outs = self.rpn_head(x) #这里代表三个输出box_preds, cls_preds, dir_cls_preds[B, 200, 176, 14],[B, 200, 176, 2],[B, 200, 176, 4]
rpn_loss_inputs = rpn_outs + (ret['gt_bboxes'], ret['gt_labels'], ret['anchors'], ret['anchors_mask'], self.train_cfg.rpn)
rpn_losses = self.rpn_head.loss(*rpn_loss_inputs)
losses.update(rpn_losses)
guided_anchors = self.rpn_head.get_guided_anchors(*rpn_outs, ret['anchors'], ret['anchors_mask'], ret['gt_bboxes'], thr=0.1)
else:
raise NotImplementedError
# bbox head forward and loss
if self.extra_head:
bbox_score = self.extra_head(conv6, guided_anchors)
refine_loss_inputs = (bbox_score, ret['gt_bboxes'], ret['gt_labels'], guided_anchors, self.train_cfg.extra)
refine_losses = self.extra_head.loss(*refine_loss_inputs)
losses.update(refine_losses)
return losses这里大部分注释参考了这篇博客.

图片来源这篇博客.
在上图中Backbone几乎没有任何作用,输入什么就输出什么;Neck部分包含了论文给的图中的Backbone network和Auxiliary network两部分;rpn_head是论文中的Detection部分;rpn_head.get_guided_anchors是对提取出来的bbox进行筛选;extra_head对应的就是PSWarp部分。下面一块一块的学习。
③ SpMiddleFHD.forward
SpMiddleFHD也就是Neck部分,也就是论文中的Backbone network和Auxiliary network两部分。注释如下
def forward(self, voxel_features, coors, batch_size, is_test=False):
# voxel_features是(b_s x N) x 4 体素
# coors已经经过了pad和cat,是一个batch的coors
points_mean = torch.zeros_like(voxel_features)
points_mean[:, 0] = coors[:, 0]
points_mean[:, 1:] = voxel_features[:, :3]
# points_mean代表点云的真实距离值(包含了每个点属于哪个batch)!!!!!!!!!!!!!!!!!!!!!!!
coors = coors.int()
x = spconv.SparseConvTensor(voxel_features, coors, self.sparse_shape, batch_size) # !!!!!!!!!真正的变成了体素
# 对voxel_features按照coors进行索引,coors在之前的处理中加入例如batch这个位置,变成了四维
# 输出是一个【batch_size,channels, sparse_shape】的数据(2, 4, 40, 1600, 1408)
# 就是让数据按照coors里的坐标进行了排列,成为了标准的体素空间
x, point_misc = self.backbone(x, points_mean, is_test)
# x是backbone的输出,体素维度缩小8倍后的64维特征,point_misc包括几部分(mean cls reg)是auxiliary的输出,即预测出来的Seg和Center
x = x.dense()
N, C, D, H, W = x.shape #(2, 64, 5, 200, 176)
x = x.view(N, C * D, H, W) #(2, 320, 200 ,176)
# 这里的D, H, W全部缩小了8倍,D=5
# reshape D是立起来的那个维度,直接把D维度上的特征都视为BEV图上一个点的不同特征,拼接,变成二维的特征
# fcn就是BEVnet,包含几个二维卷积
x = self.fcn(x) # (2, 256, 200, 176)
if is_test:
return x
return x, point_misc
# x是detector的输出(2, 256, 200, 176),point_misc是auxiliary的输出spconv中包含了点云体素化的方法,就是spconv.SparseConvTensor,注意函数的输入coors中要包含每个点所属的batch中的第几帧数据,也就是pad操作。
其中还包括了三维稀疏特征到2D平面特征的转化,就是reshape造作,将第三个维度和channel维度合并。
④ SSDRotateHead.forward
这个head是得到最终预测的3D bbox和class,由于两者是分开得到的,中间经历了一个不同的卷积层,因此可能存在一定的位置误差。
def forward(self, x):
# x从SpMiddleFHD中来,是[B(2), C(256), H(200), W(176)]的张量
box_preds = self.conv_box(x) # 输出 [B, 14, 200, 176] 的张量
cls_preds = self.conv_cls(x) # 输出 [B, 2, 200, 176] 的张量
# [N, C, y(H), x(W)]
# 对张量做转置,contiguous 是让置换后的张量内存分布连续的操作
box_preds = box_preds.permute(0, 2, 3, 1).contiguous() # [B, 200, 176, 14]
cls_preds = cls_preds.permute(0, 2, 3, 1).contiguous() # [B, 200, 176, 2]
if self._use_direction_classifier:
dir_cls_preds = self.conv_dir_cls(x) # 输出 [B, 4, 200, 176] 的张量
# 为什么是 4 呢?
# 是因为 conv_dir_cls 的通道数定义为 num_anchor_per_loc * 2 = 2*2
# 输出 [B, 200, 176, 4] 的张量,因为每个loc有两个角度的anchor,都包括前向后向两个状态
dir_cls_preds = dir_cls_preds.permute(0, 2, 3, 1).contiguous() # [B, 200, 176, 4]
return box_preds, cls_preds, dir_cls_preds # [B, 200, 176, 14],[B, 200, 176, 2],[B, 200, 176, 4]⑤ PSWarpHead.get_guided_anchors
PSWarpHead.forward的输入还有一个guided_anchors,要把这部分的意义搞懂,才能知道PSWarpHead到底是计算的那些bbox的分类。上源码。
# anchors_mask 是 (1408*1600*2,1) 的 bool 型向量
# anchors 是 (1600*1408*2,7) 的张量
# box_preds, cls_preds, dir_cls_preds 是 [B, 200, 176, 14],[B, 200, 176, 2],[B, 200, 176, 4]
# 每个变量的 C 值都不一样,分别是 7, num_class, 2
# N 是 batch size
def get_guided_anchors(self, box_preds, cls_preds, dir_cls_preds, anchors, anchors_mask, gt_bboxes, thr=.1):
batch_size = box_preds.shape[0]
# batch_box_preds 是 [N(2), H x W x 2(1600 x 1408 x 2),7] 的张量
batch_box_preds = box_preds.view(batch_size, -1, self._box_code_size)
# batch_anchors_mask 是 [N(2), H x W x 2(1600*1408*2)] 的张量
batch_anchors_mask = anchors_mask.view(batch_size, -1)
# [N(2), H x W x 2(1600*1408*2)]
batch_cls_preds = cls_preds.view(batch_size, -1)
batch_box_preds = second_box_decode(batch_box_preds, anchors)
if self._use_direction_classifier:
# [N(2), H x W x 2(1600*1408*2), 2]
batch_dir_preds = dir_cls_preds.view(batch_size, -1, 2)
new_boxes = []
if gt_bboxes is None:
gt_bboxes = [None] * batch_size
# 一个batch一个batch的处理
# 首先,把跟网络初次预测的 3d框 跟 Anchor_mask 下的 Anchor比较
# 把重叠度高的 Anchor 保留下来(mask中为0的框直接去掉,因为为0代表着框里没有点);
# 其次,这些 Anchor 对应的网络预测的 3d框 所对应的cls_preds 用 sigmoid 处理一遍,
# 把高于阈值 thr 的 Anchor 框保留下来
# 再者,如果是训练阶段,给每一个框一个 3d框 的label真值
for box_preds, cls_preds, dir_preds, a_mask, gt_boxes in zip(
batch_box_preds, batch_cls_preds, batch_dir_preds, batch_anchors_mask, gt_bboxes
):
# 根据mask(代表这个anchor里边有没有点云点存在),拿出有效box_preds,cls_preds,dir_preds
box_preds = box_preds[a_mask]
cls_preds = cls_preds[a_mask]
dir_preds = dir_preds[a_mask]
if self._use_direction_classifier:
# [N(2), H x W x 2(1600*1408*2), 2],这里拿出[H x W x 2(1600*1408*2), 2](一个batch),拿出最后一个维度的最大值来,代表这个框预测出来的最有可能的分类结果(朝向分类结果)
dir_labels = torch.max(dir_preds, dim=-1)[1] # [H x W x 2(1600*1408*2)]
if self._use_sigmoid_cls:
# 进行一下sigmoid,0-1之间,代表某个框是某个分类的可能性大小,每个框对每个分类都有可能性
total_scores = torch.sigmoid(cls_preds)
else:
total_scores = F.softmax(cls_preds, dim=-1)[..., 1:]
# 去掉维度大小为1的维度
top_scores = torch.squeeze(total_scores, -1)
# 把预测可能性高于阈值 thr 的 Anchor 框保留下来
selected = top_scores > thr
box_preds = box_preds[selected]
if self._use_direction_classifier:
# 根据dir和box_preds,得到框的真实角度
dir_labels = dir_labels[selected]
opp_labels = (box_preds[..., -1] > 0) ^ dir_labels.byte()
box_preds[opp_labels, -1] += np.pi
# add ground-truth
if gt_boxes is not None:
box_preds = torch.cat([gt_boxes, box_preds],0)
# 保存每一个合格的 Anchor
new_boxes.append(box_preds)
return new_boxes # 注意这里面放的是点云坐标系下的真实距离坐标最终剩下的box_preds中,经过了层层的筛选,大概意思就是本来是每个体素点上都有2个框,好几万个,经过这么一筛选,得到了有可能是目标种类物体的框,就几十个。这些甚至几乎可以放到图中进行可视化了(还差一步NMS)。
⑤ PSWarpHead.forward
PSWarpHead的前向计算部分就是得到了每个框的得分(可能性)。
def forward(self, x, guided_anchors, is_test=False):
x = self.convs(x)# 张量尺寸为 [B, 28, 200, 176],称之为 confidence map
bbox_scores = list()
# i代表第几个batch
for i, ga in enumerate(guided_anchors):
if len(ga) == 0:
# 如果这个批次没有 guided anchor,就输出一个零值张量,尺寸跟 x 一样
bbox_scores.append(torch.empty(0).type_as(x))
continue
# 得到guided_anchor的x和y区域
# xs, ys 分别是矩形区域内的栅格采样点在 x 和 y 轴坐标,是 [4*7, N] 张量
# N代表这个batch的guided_anchor里共有这么多的框
(xs, ys) = self.gen_grid_fn(ga[:, [0, 1, 3, 4, 6]])
# (xs, ys)[28, N]是指,在每个框里面取出来28个点的坐标(BEV)
# 提取这个batch下的特征图,im 是 [C(28), 200, 176] 的张量
im = x[i]
# 在每个 anchor 内的栅格采样点中插值出特征图中的特征向量,是 [C(28), 200, 176]
out = bilinear_interpolate_torch_gridsample(im, xs, ys) # 28 x 1 x N x 1
# 以第一个维度做平均,score 是一个标量,返回每个 anchor 中所有采样点对应特征之平均值,28个特征求平均
# 这样理解:在进行双线性插值时,两个输入分别是[28, 1, 200, 176]和[28, N, 1, 2](详情见bilinear_interpolate_torch_gridsample)
# 第一个输入就可以看作200 x 176个特征点,每个特征点在周围采样28点中的第一点的特征1 x 1 x200 x 176,特征channel是1
# 每个点都要采样28个点,一共就是[28, 1, 200, 176],特征channel是1
# 在进行双线性插值时,先归一化,最终我要得到的是N x 1的维度,28个采样点视为28种插值方法依次对中心点进行插值,就得到28个N x 1的特征,就是28 x 1 x N x 1,特征channel是1
# 再对这28种插值特征求平均,得到的就是需要的N x 1的特征,维度[N, 1]
score = torch.mean(out, 0).view(-1)
# [B, N] 再loss中,bbox_scores与labels求损失,其实bbox_scores这里就是指插值得到的这个框的分类
bbox_scores.append(score)
# B x 200 x 176
# 如果是模型学习阶段,就只输出 bbox_scores
if is_test:
return bbox_scores, guided_anchors
else:
return torch.cat(bbox_scores, 0)PSWarp的方法就是在每个guided_anchors中均匀采样28个点,用28个点插值出每个guided_anchor的得分,28 x N,再平均一下就是每个guided_anchors的最终分类得分。用来插值的特征是conv6,是SpMiddleFHD,也就是Backbone network部分的一个输出。
这里其实只贴出了一小部分的源码,还有大量的调用函数需要阅读才能完全弄懂这个模型,还有三个loss的计算方法没写,有时间再写。整个mmdetection框架包含的内容更多,一个一个看的话太慢,建议还是跟着算法走,了解常用的方法。
SASSD的了解应该到此为止了,中间的启发有很多,尤其是辅助网络,可以适用于很多的模型,PSWarp部分有一定的作用,但感觉作用不是很大。再者就是spconv库的灵活运用,非常适合3D稀疏卷积。
之前注释过源码的SequeezeSeg,Rangenet++,Salsanet等算法是针对语义分割任务的,而且均是基于深度图方法,voxel_base的方法与深度图方法相比较,能更大程度保存点云数据的3D信息,似乎更适用于点云处理,但也不是太过绝对的,当然还有point_based的方法保存的信息更多,处理起来也更难。
最后还是非常感谢这位作者.