caffe 的layer的参数说明
最近在学习caffe做实验 今天就记录一下layer的参数及这些常用的参数的解释吧
主要还是参考官方网站
http://caffe.berkeleyvision.org/tutorial/layers.html
下面就介绍一下常用的layer的配置
以caffe中根目录下的models 中caffenet
其中主要有三个文件
deploy.prototxt solver.prototxt train_val.prototxt
deploy.prototxt 主要是caffenet的架构
name: "CaffeNet"
input: "data"
input_shape {
dim: 10 # 一批的数量(bach of image )
dim: 3 #通道数量(channels 彩色图是3通道RGB)
dim: 227 #图像的高度(height)
dim: 227 #图像的宽度(weight)
}
layer {
name: "conv1" #层的名称
type: "Convolution" # 层的类型
bottom: "data" #层的输入(主要是对应上面的data)
top: "conv1" #层的输出(对应的是本层卷积的结果)
convolution_param { #卷积的参数
num_output: 96 #过滤器的个数 可以看做的是卷积和的个数吧
kernel_size: 11 #卷积核的大小
stride: 4 #图像中的间隔多少进行卷积(我认为是一次窗口滑动的步长)
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX #使用最大池化
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
convolution_param {
num_output: 256
pad: 2 #边界处补2个行和2个列
kernel_size: 5
group: 2 #卷积分组(补,最下面的解释)
}
}
layer {
name: "relu2"
type: "ReLU" #激活函数
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN" #Local Response Normalization (LRN) (侧抑制)
bottom: "pool2"
top: "norm2"
lrn_param { #主要是LRN的三个主要的参数
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
convolution_param {
num_output: 256
pad: 1 #对图像进行补充像素的设置(在图像的高和宽进行补充)
kernel_size: 3
group: 2
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
inner_product_param {
num_output: 4096 #过滤器的个数(在此可以看做是输出的个数)
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5 #使用的drop进行网络的参数的隐藏时的参数
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
inner_product_param {
num_output: 4096 #过滤器的个数(在此可以看做是输出的个数)
}
}
layer {
name: "relu7"
type: "ReLU" #relu的激活函数
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout" #dropout 将一部分的的权重置零不参与运算
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct" #内积(全连接层)
bottom: "fc7"
top: "fc8"
inner_product_param {
num_output: 1000 #过滤器的个数
}
}
layer {
name: "prob"
type: "Softmax" #softmax分类层
bottom: "fc8"
top: "prob"
}以上是此网络中出现的参数,在具体使用时 ,如遇到不清楚的参数含义可以到官网中查询。
在使用中solver.prototxt文件主要是存储网络的参数的
从官方给出主要是一些函数的优化中的参数
全局参数的配置的文件
(在后面添加对其的补充)
net: "models/bvlc_reference_caffenet/train_val.prototxt"
#设置网络的结构读取prototxt文件
test_iter: 1000 #设置迭代的次数
test_interval: 1000 #
base_lr: 0.01 #开始的学习率
lr_policy: "step" #学习率的drop是以gamma在每一次迭代中
gamma: 0.1
stepsize: 100000 #每stepsize的迭代删除学习率
display: 20
max_iter: 450000 #train 最大迭代max_iter
momentum: 0.9 #
weight_decay: 0.0005 #
snapshot: 10000 #没迭代snapshot次,保存一次快照
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
#快照文件存储的位置
snapshot_diff: false #最终保存快照文件,默认的是不保存
solver_mode: GPU #使用的模式是GPU train_val.prototxt 文件是训练时候的框架配置
训练网络的配置的文件
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data" #输出数据
top: "label" #输出标签
include {
phase: TRAIN #训练阶段
}
transform_param {
mirror: true #映射是否开启
crop_size: 227 #图的尺寸
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
#均值文件
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: true
# }
data_param {
source: "examples/imagenet/ilsvrc12_train_lmdb"
#训练集的文件
batch_size: 256 #每一批的大小
backend: LMDB #数据格式lmdb
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST #测试阶段
}
transform_param {
mirror: false #映射是否开启
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: false
# }
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 50
backend: LMDB
}
}这个文件主要是用来训练和测试的
以上是三个配置文件的主要参数其中有一些参数的意义本人也不是很清楚,在分享出来,慢慢补全吧。
记录一下caffemodel
这个文件是用来存放已经训练好的整个网络的参数,可以加载进来直接使用,一般是用来做finetuning的。
补充:针对卷积进行分组的设置group属性,卷积分组可以减少网络的参数,至于是否还有其他的作用就不清楚了。
分组其实就是将输入的数据和卷积核进行分组,不在使得先局部连接在全部连接,而是到达一种局部连接。
如下图所示:
设置输入input:2;kernel:4;group:2;
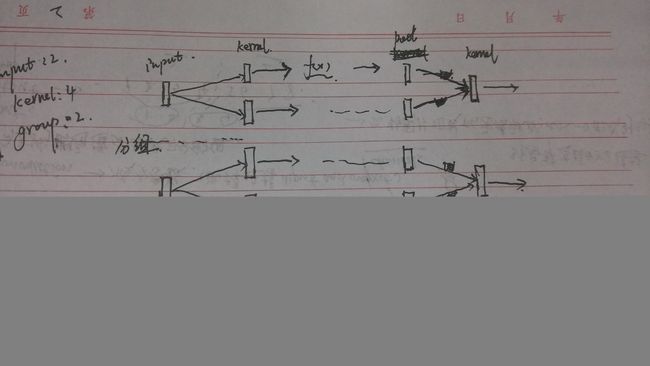
从图中可以看到其实每个input是需要和每一个kernel都进行连接的,但是由于分组的原因其只是与部分的kernel进行连接的。
后面又画出input:4,;kernel:2;group:2
的情况是计算之后的叠加输出,其实跟之前看的多通道的处理是一至的,只是多出了一个分组的划分。
以下是经过查询对slover的补充:
lr_policy
// The learning rate decay policy. The currently implemented learning rate
// policies are as follows:
// - fixed: always return base_lr.
// - step: return base_lr * gamma ^ (floor(iter / step))
// - exp: return base_lr * gamma ^ iter
// - inv: return base_lr * (1 + gamma * iter) ^ (- power)
// - multistep: similar to step but it allows non uniform steps defined by
// stepvalue
// - poly: the effective learning rate follows a polynomial decay, to be
// zero by the max_iter. return base_lr (1 - iter/max_iter) ^ (power)
// - sigmoid: the effective learning rate follows a sigmod decay
// return base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
//
// where base_lr, max_iter, gamma, step, stepvalue and power are defined
// in the solver parameter protocol buffer, and iter is the current iteration.
补充:针对
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
# learning rate and decay multipliers for the filters #注意是对两个的修改(对filter)
param { lr_mult: 1 decay_mult: 1 }
# learning rate and decay multipliers for the biases #对卷积之后的b的衰减的速率
param { lr_mult: 2 decay_mult: 0 }
convolution_param {
num_output: 96 # learn 96 filters
kernel_size: 11 # each filter is 11x11
stride: 4 # step 4 pixels between each filter application
weight_filler {
type: "gaussian" # initialize the filters from a Gaussian
std: 0.01 # distribution with stdev 0.01 (default mean: 0)
}
bias_filler {
type: "constant" # initialize the biases to zero (0)
value: 0
}
}
}其中含有两个的param
# learning rate and decay multipliers for the filters #注意是对filter的修改(对filter)
param { lr_mult: 1 decay_mult: 1 }
# learning rate and decay multipliers for the biases #对卷积之后的biases的更新参数
param { lr_mult: 2 decay_mult: 0 }
注意出现两个时的意义。