pointpillars点云算法TensorRT环境加速系列二
简述
上一篇博文撰写了关于pointpillars算法的pytorch模型如何转换为onnx模型中间件,具体参考此链接:pointpillars点云算法TensorRT环境加速系列一以此来方便TensorRT进行加载解析优化模型。接下来,我们在完成第一步模型成功从pytorch模型转换成为onnx之后,需要验证onnx模型转换之后的精度与原始的pytorch模型精度差多少。
Attention: 环境与代码与第一篇一致
或者你可以参考我的github上ReadMe,里面有具体的步骤关于如何测试onnx模型的精度对比,传送门点击此链接。
Compare pfe.onnx with pytorch-model pfe-layer outputs
首先,我们对第一个onnx模型pfe.onnx与原始pytorch模型对于pfe层的网络输出结果进行对比,需要将输入对应一致进行检查:
以下为onnx模型预测pfe.onnx模型输出的主要代码部分: 简单说下:输入分别为pillar_x、pillar_y、pillar_z、pillar_i、num_points_per_pillar、x_sub_shaped、y_sub_shaped、mask总共8个张量作为输入,同时需要主要每个张量的device设置,我这边通过打印原始的输出device进行手动添加以此来对应上。
def onnx_model_predict(config_path=None, model_dir=None):
import onnxruntime
from second.pytorch.models.pointpillars import PillarFeatureNet, PointPillarsScatter
# check the pfe onnx model IR input paramters as follows
pillar_x = torch.ones([1, 1, 12000, 100], dtype=torch.float32, device="cuda:0")
pillar_y = torch.ones([1, 1, 12000, 100], dtype=torch.float32, device="cuda:0")
pillar_z = torch.ones([1, 1, 12000, 100], dtype=torch.float32, device="cuda:0")
pillar_i = torch.ones([1, 1, 12000, 100], dtype=torch.float32, device="cuda:0")
num_points_per_pillar = torch.ones([1, 12000], dtype=torch.float32, device="cuda:0")
x_sub_shaped = torch.ones([1, 1, 12000, 100], dtype=torch.float32, device="cuda:0")
y_sub_shaped = torch.ones([1, 1, 12000, 100], dtype=torch.float32, device="cuda:0")
mask = torch.ones([1, 1, 12000, 100], dtype=torch.float32, device="cuda:0")
pfe_session = onnxruntime.InferenceSession("pfe.onnx")
# Compute ONNX Runtime output prediction
pfe_inputs = {pfe_session.get_inputs()[0].name: (pillar_x.data.cpu().numpy()),
pfe_session.get_inputs()[1].name: (pillar_y.data.cpu().numpy()),
pfe_session.get_inputs()[2].name: (pillar_z.data.cpu().numpy()),
pfe_session.get_inputs()[3].name: (pillar_i.data.cpu().numpy()),
pfe_session.get_inputs()[4].name: (num_points_per_pillar.data.cpu().numpy()),
pfe_session.get_inputs()[5].name: (x_sub_shaped.data.cpu().numpy()),
pfe_session.get_inputs()[6].name: (y_sub_shaped.data.cpu().numpy()),
pfe_session.get_inputs()[7].name: (mask.data.cpu().numpy())}
pfe_outs = pfe_session.run(None, pfe_inputs)
print('-------------------------- PFE ONNX Outputs ----------------------------')
print(pfe_outs) # also you could save it to file for comparing
print('-------------------------- PFE ONNX Ending ----------------------------')
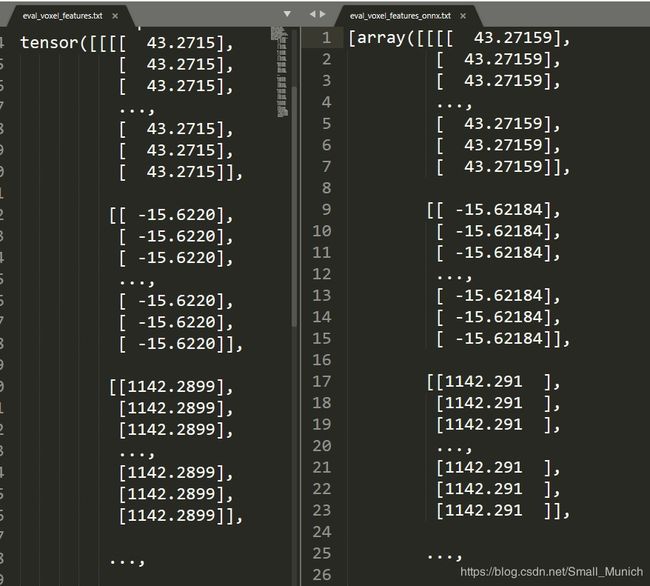
看过主要的预测pfe.onnx代码之后,我们来对比一下结果:左边为原始pytorch模型关于pfe-layer的张量输出结果,右边为pfe.onnx模型的输出结果,可以看到输出误差在小数点后三位级别。
Compare rpn.onnx with pytorch-model rpn-layer outputs
接下来,我们来主要对比一下rpn.onnx模型的输出与pytorch模型进过rpn网络的输出进行对比。由于rpn网络之前并不是直接接入pfe网络的输出,中间进过pillarscatter网络,所以针对验证输入输出不可以单独抛开pfe网络层。当然,你也可以直接读取pfe层的输出,通过pillarscatter网络后,接入rpn网络来查看输出进行对比。
以下为预测rpn.onnx主要部分代码,包括rpn网络输入连接pillarscatter网络的输出,这样也连接上pfe网络的输出,具体代码如下:
def onnx_model_predict(config_path=None, model_dir=None):
import onnxruntime
from second.pytorch.models.pointpillars import PillarFeatureNet, PointPillarsScatter
# check the rpn onnx model IR input paramters as follows
pillar_x = torch.ones([1, 1, 9918, 100], dtype=torch.float32, device="cuda:0")
pillar_y = torch.ones([1, 1, 9918, 100], dtype=torch.float32, device="cuda:0")
pillar_z = torch.ones([1, 1, 9918, 100], dtype=torch.float32, device="cuda:0")
pillar_i = torch.ones([1, 1, 9918, 100], dtype=torch.float32, device="cuda:0")
num_points_per_pillar = torch.ones([1, 9918], dtype=torch.float32, device="cuda:0")
x_sub_shaped = torch.ones([1, 1, 9918, 100], dtype=torch.float32, device="cuda:0")
y_sub_shaped = torch.ones([1, 1, 9918, 100], dtype=torch.float32, device="cuda:0")
mask = torch.ones([1, 1, 9918, 100], dtype=torch.float32, device="cuda:0")
pfe_session = onnxruntime.InferenceSession("pfe.onnx")
# Compute ONNX Runtime output prediction
pfe_inputs = {pfe_session.get_inputs()[0].name: (pillar_x.data.cpu().numpy()),
pfe_session.get_inputs()[1].name: (pillar_y.data.cpu().numpy()),
pfe_session.get_inputs()[2].name: (pillar_z.data.cpu().numpy()),
pfe_session.get_inputs()[3].name: (pillar_i.data.cpu().numpy()),
pfe_session.get_inputs()[4].name: (num_points_per_pillar.data.cpu().numpy()),
pfe_session.get_inputs()[5].name: (x_sub_shaped.data.cpu().numpy()),
pfe_session.get_inputs()[6].name: (y_sub_shaped.data.cpu().numpy()),
pfe_session.get_inputs()[7].name: (mask.data.cpu().numpy())}
pfe_outs = pfe_session.run(None, pfe_inputs)
# print('-------------------------- PFE ONNX Outputs ----------------------------')
# print(pfe_outs) # also you could save it to file for comparing
# print('-------------------------- PFE ONNX Ending ----------------------------')
##########################Middle-Features-Extractor#########################
# numpy --> tensor
pfe_outs = np.array(pfe_outs)
voxel_features_tensor = torch.from_numpy(pfe_outs)
voxel_features = voxel_features_tensor.squeeze()
# voxel_features = np.array(pfe_outs).squeeze()
voxel_features = voxel_features.permute(1, 0)
if isinstance(config_path, str):
config = pipeline_pb2.TrainEvalPipelineConfig()
with open(config_path, "r") as f:
proto_str = f.read()
text_format.Merge(proto_str, config)
else:
config = config_path
model_cfg = config.model.second
vfe_num_filters = list(model_cfg.voxel_feature_extractor.num_filters)
voxel_generator = voxel_builder.build(model_cfg.voxel_generator)
grid_size = voxel_generator.grid_size
output_shape = [1] + grid_size[::-1].tolist() + [vfe_num_filters[-1]]
num_input_features = vfe_num_filters[-1]
batch_size = 2
mid_feature_extractor = PointPillarsScatter(output_shape,
num_input_features,
batch_size)
device = torch.device("cuda:0")
coors_numpy = np.loadtxt('./onnx_predict_outputs/coors.txt', dtype=np.int32)
coors = torch.from_numpy(coors_numpy)
coors = coors.to(device).cuda() # CPU Tensor --> GPU Tensor
voxel_features = voxel_features.to(device).cuda()
rpn_input_features = mid_feature_extractor(voxel_features, coors)
#################################RPN-Feature-Extractor########################################
# rpn_input_features = torch.ones([1, 64, 496, 432], dtype=torch.float32, device='cuda:0')
rpn_session = onnxruntime.InferenceSession("rpn.onnx")
# compute RPN ONNX Runtime output prediction
rpn_inputs = {rpn_session.get_inputs()[0].name: (rpn_input_features.data.cpu().numpy())}
rpn_outs = rpn_session.run(None, rpn_inputs)
print('---------------------- RPN ONNX Outputs ----------------------')
print(rpn_outs)
print('---------------------- RPN ONNX Ending ----------------------')
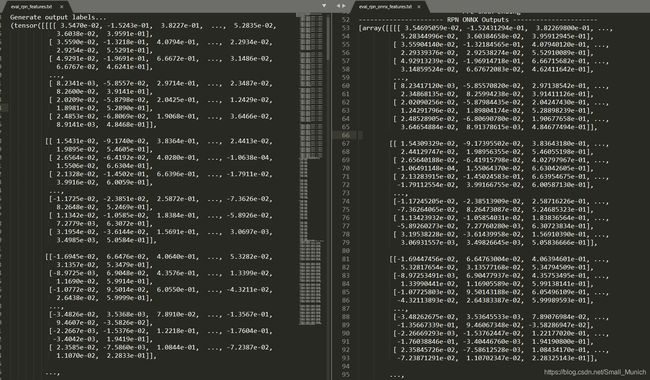
当然,rpn-layer层对比rpn.onnx操作对比输出的精度差,如下可以查看,误差系数在小数点3位之后:
小结
到此,验证pointpillars算法pytorch模型转换成为pfe.onnx与rpn.onnx精度对比基本完成。具体的代码将会在我的github上面进行更新,目前结果来看模型转换成功,下一篇将会将其使用TensorRT进行加速来对比一下经过TensorRT优化加速之后,效率提升了多少,敬请期待。
参考文献
https://github.com/SmallMunich/nutonomy_pointpillars
https://blog.csdn.net/Small_Munich/article/details/101559424
https://arxiv.org/abs/1812.05784