python函数の拾遗
def | return | *args | **kwargs | lambda …
1、函数の定义与调用
# 定义
def 函数名(形参):
函数体
if xxx:
return 返回值
else:
return 返回值
# 调用
返回值 = 函数名(实参)
- 函数可以传递字符串作为参数,可以传递其他类型么?
数字 小数整数
列表 元祖 字典 集合 - 返回值可以是任意的数据类型么?
是的
1.1 求和函数
[1,4,5,6,112,445,656] 调用函数,计算任意一个数字列表的和
# 列表求和
li = [1, 2, 3, 4, 1.2, 3.4, 9.12]
def sum_li(li):
sum_num = 0
for i in li:
sum_num += i
return sum_num
res = sum_li(li)
print(res)
升级 如果传过来的数据类型是一个字典 {‘key’:[1,2,3],‘k2’:[1234,4566]}
# 字典值求和
def sum_li(li):
sum_num = 0
for i in li:
sum_num += i
return sum_num
def sum_dict(dic):
sum_num = 0
for k in dic:
sum_l = sum_li(dic[k])
sum_num += sum_l
return sum_num
dic = {'k1': [1, 2, 3, 4], 'k2': [5, 6, 7, 8]}
res = sum_dict(dic)
print(res)
1.2 实现 login 函数
login函数
# 完成3次登录,如果登录成功,返回True,如果登录失败,返回False
# 结合文件操作完成
# 用户信息存储
with open('user_info', mode='w', encoding='utf-8') as f:
f.write('admin|admin\n')
f.write('andy|andy\n')
def login():
login_times = 3
while login_times > 0:
login_times -= 1
user = input('请输入用户名:')
pwd = input('请输入密码:')
with open('user_info', mode='r', encoding='utf-8') as f:
for line in f:
name, password = line.strip().split('|')
if user == name and pwd == password:
return True
if login_times > 0:
print(f'用户名或密码错误,你还有{login_times}次机会')
else:
print('登录失败!')
user_login = login()
if user_login:
print('登录成功!')
2、函数的返回值
函数的返回值:默认是None,可以是任意数据类型。
- 一个函数中可以写多个return, 但最终执行的只有一个
- return关键字标识着函数的结束
- 一个函数可以没有return关键字,默认返回None
- 一个return关键字可以返回一个返回值,也可以返回多个返回值,最终返回的是一个元组
- 可以使用解包的方式来接收返回值
2.1 return关键作用
2.1.1 返回值
return 返回值有几种情况:分别是没有返回值、返回一个值、返回多个值
- 没有返回值
#函数定义
def mylen():
"""计算s1的长度"""
s1 = "hello world"
length = 0
for i in s1:
length = length+1
print(length)
#函数调用
str_len = mylen()
#因为没有返回值,此时的str_len为None
print('str_len : %s'%str_len)
# 11
# str_len : None
只写return,后面不写其他内容,也会返回None
2.1.2 结束一个函数
- 一旦遇到 return ,结束整个函数
def ret_demo():
print(111)
return
print(222)
ret = ret_demo()
print(ret)
# 111
# None
2.2 当函数内不写返回值或者只写一个return关键字的时候
- 表示返回 None ,也就是相当于返回了 False
2.3 当有返回值需要返回的时候
- 返回一个值
#函数定义
def mylen():
"""计算s1的长度"""
s1 = "hello world"
length = 0
for i in s1:
length = length+1
return length
#函数调用
str_len = mylen()
print('str_len : %s'%str_len)
# str_len : 11
return和返回值之间要有空格,可以返回任意数据类型的值
- 返回多个值
可以返回任意多个、任意数据类型的值
def ret_demo1():
'''返回多个值'''
return 1,2,3,4
def ret_demo2():
'''返回多个任意类型的值'''
return 1,['a','b'],3,4
ret1 = ret_demo1()
print(ret1)
# (1, 2, 3, 4) # 元组
ret2 = ret_demo2()
print(ret2)
# (1, ['a', 'b'], 3, 4)
返回的多个值会被组织成元组被返回,也可以用多个值来接收
def ret_demo2():
return 1,['a','b'],3,4
# 返回多个值,用一个变量接收
ret2 = ret_demo2()
print(ret2)
# (1, ['a', 'b'], 3, 4)
# 返回多个值,用多个变量接收
a,b,c,d = ret_demo2()
print(a,b,c,d)
# 1 ['a', 'b'] 3 4
# 用多个值接收返回值:返回几个值,就用几个变量接收
a,b,c,d = ret_demo2()
print(a,b,c,d)
# 1 ['a', 'b'] 3 4
补充:为啥 多个 元素就被返回 成元组了呢??
>>> 1,2 # python中把用逗号分割的多个值就认为是一个元组。
(1, 2)
>>> 1,2,3,4
(1, 2, 3, 4)
>>> (1,2,3,4)
(1, 2, 3, 4)
#序列解压一
>>> a,b,c,d = (1,2,3,4)
>>> a
1
>>> b
2
>>> c
3
>>> d
4
#序列解压二
>>> a,_,_,d=(1,2,3,4)
>>> a
1
>>> d
4
>>> a,*_=(1,2,3,4)
>>> *_,d=(1,2,3,4)
>>> a
1
>>> d
4
#也适用于字符串、列表、字典、集合
>>> a,b = {'name':'eva','age':18}
>>> a
'name'
>>> b
'age'
3、函数的参数
3.1 实参与形参
参数的分类:形参和实参
- 实参
调用函数时传递的这个 “hello world” 被称为实际参数,因为这个是实际的要交给函数的内容,简称实参。 - 形参
定义函数时的 s,只是一个变量的名字,被称为形式参数,因为在定义函数的时候它只是一个形式,表示这里有一个参数,简称形参。
#函数定义
def mylen(s): # 形式参数,形参
"""计算s的长度"""
length = 0
for i in s:
length = length+1
return length
#函数调用
str_len = mylen("hello world") # 实际参数,实参
print('str_len : %s'%str_len)
# str_len : 11
3.2 传递多个参数
参数可以传递多个,多个参数之间用逗号分割
def mymax(x,y):
the_max = x if x > y else y
return the_max
ma = mymax(10,20)
print(ma)
# 20
3.3 位置参数
3.3.1 站在实参角度
实参,可以是任意数据类型,实参和形参的个数是一一对应的
- 按照 位置 传值
按照位置传参数 :按照形参定义的顺序一一对应接收参数
def mymax(x,y): # 10 --> x ; 20 --> y
#此时x=10,y=20
the_max = x if x > y else y
return the_max
ma = mymax(10,20) # 10 --> x ; 20 --> y
print(ma)
# 20
- 按照 关键字 传值
按照关键字传参数 :参数的顺序不重要,指定形参的名字传递对应的参数值
def mymax(x,y):
#此时x = 20,y = 10
print(x,y)
the_max = x if x > y else y
return the_max
ma = mymax(y = 10,x = 20)
print(ma)
- 位置、关键字形式 混传
按照位置传参必须在按照关键字传参之前,并且按关键字传参仍然可以忽略顺序
def div(a,b,c):
print(a) # 4
print(b) # 4
print(c) # 2
ret = div(4,c = 2,b = 4)
print(ret)
总结:
问题一: 位置参数必须在关键字参数的前面
问题二: 对于一个形参只能赋值一次
3.3.2 站在形参角度
位置参数必须传值
def mymax(x,y):
#此时x = 10,y = 20
print(x,y)
the_max = x if x > y else y
return the_max
#调用mymax不传递参数
ma = mymax()
print(ma)
#结果
TypeError: mymax() missing 2 required positional arguments: 'x' and 'y'
3.4 默认参数
3.4.1 为啥有 默认参数的原因竟然是 ??
将变化比较小的值设置成默认参数
3.4.2 默认参数的定义
def stu_info(name, country = "CN"):
"""打印学生信息函数,由于班中大部分学生国籍都是中国,
所以设置默认参数 country 的默认值为'CN'
"""
print(name,country)
# 这里,默认参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值
stu_info('admin')
# admin CN
stu_info('andy','EN')
# andy EN
3.4.3 参数陷阱:当默认参数是一个可变数据类型 !!
【Interview questions】
这块就看 你对 函数 执行顺序 是否 真正了解 ??
执行顺序:从上往下 顺序执行,当程序 走到 def 函数定义时先划分def涉及到的内存空间,然后继续往下运行,直到函数被调用时,才会给函数其内部划分出内存空间。

l = []
def func(a,l=l):
l.append(a)
print(l)
func(1) # [1]
func(2) # [1, 2]
func(3) # [1, 2, 3]
def func(a,l=[]):
l.append(a)
print(l)
func(1) # [1]
func(2,[]) # [2]
func(3) # [1,3]
3.5 动态参数
动态参数也称为非固定参数,若你的函数在定义时不确定用户想传入多少个参数,就可以使用动态参数
- *args
*args 会把多传入的参数变成一个 元组 形式
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式
print(name,age,args)
stu_register("andy",22)
# 输出
# andy 22 () # 后面这个()就是args,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python")
# 输出
# Jack 32 ('CN', 'Python')
- **kwargs
**kwargs 会把多传入的 关键字参数 变成一个 字典 形式
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式
print(name,age,args,kwargs)
stu_register("andy",22)
# 输出
# andy 22 () {} # 后面这个{} 就是kwargs,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python",sex="Male",province="ShangHai")
# 输出
# Jack 32 ('CN', 'Python') {'province': 'ShangHai', 'sex': 'Male'}
def print_info(*args, **kwargs):
print('info'.center(30, '-'))
print(f'Name:{kwargs["name"]}')
print(f'Age:{kwargs["age"]}')
hobby = kwargs["hobby"] if 'hobby' in kwargs.keys() else 'piano'
print(f'Hobby:{hobby}')
print_info(name='andy', age=18)
print_info(name='jack', age=23, hobby='学习')
总结:**kwargs 永远放在所有参数的最后.
3.6 总结
参数的分类:形参和实参
3.6.1 传递(调用、实参)
- 按照位置传 func(参数1,参数2) func(*list)
# 参数是没有固定的名字的,顺序是必须固定的 # print(1,2,3,4,5) # print(*list) - 按照关键字传 func(key=参数1,key2=参数2) func(**dict)
# 顺序是不固定的,参数的名字是固定的 # open(url = '',mode = '',encoding='') # open(**{'url':'','mode':'r','encoding':''}) - 按照位置传参+关键字传参
# 必须位置参数在前,关键字参数在后 # 同一个关键字不能被传两个值 - 打散参数传法
# *list *tuple 将列表中的值一个一个取出来,按照位置传递参数 # **dict 将字典中的key、value值一个一个取出来变成key=value的形式,按照关键字传递参数
3.6.2 接收(定义、形参)
- 位置参数:必须传的
- *args :动态的参数 不是必须传的
# 所有除了位置参数接收的其他按照位置传递来的参数 # args就是一个元组 - 默认参数 :不是必须传的
# 如果用户传了,就用用户传的 # 如果用户没传,就用默认的 # 陷阱 # def func(l = [],d = {}): # 大部分情况下都不成立 # pass - **kwargs: 不是必须传的
# 所有除了位置参数、默认参数之外其他按照关键字传递而来的参数 # kwargs就是一个字典
4、命名空间与作用域
4.1 程序 和 函数的加载问题
4.1.1 程序的加载顺序,加载进来的都是全局变量
- 1、先加载内置的名字
- 2、继续加载文件级别(在函数外部定义的)
4.1.2 函数的加载
- 函数内部的变量进入内存需要通过调用
- 函数内部的数据会随着函数的结束而被销毁
- 函数内部的数据是不可以在外部被使用的
4.2 函数名是个啥玩意??
函数名的本质 就是一个内存地址,在我们的程序中 所有的值、变量都有一个所在的内存地址
# 本质就是一个内存地址
# 内存地址+()就是执行这个函数
# 函数名可以赋值、可以作为其他容器类型的元素
- 打印函数名的内存地址空间
def func1():
print(123)
def func2():
print(234)
print(func1) # 函数名的本质 就是一个内存地址
# - 函数名被赋值后的调用、打印内存地址
def func1():
print(123)
a = func1
a() # 123
print(a) # - 通过遍历函数名遍历执行函数举例
def func1():
print(123)
def func2():
print(234)
# 1、列表方式调用执行
l = [func1,func2]
l[0]() # 输出 123
l[1]() # 输出 234
# 2、循环调用执行
for i in l:
i()
# 输出 123
# 输出 234
4.3 函数的命名空间及作用域
1、命名空间:内置的命名空间、全局的命名空间、局部命名空间
- 内置的命名空间和全局的命名空间 都属于全局作用域
- 自定义的所有名字都是属于全局或者局部命名空间的,不可以和内置的命名空间中的变量同名
- 在局部可以引用全局命名空间中的变量 反之不行
- 在全局可以引用内置命名空间的变量 反之不行
2、作用域
- 这些在命名空间里的名字都能在哪个区域发生作用
- 内置命名空间+全局命名空间 = 全局作用域
- 在全局作用域中的变量可以被全局、各种局部使用
- 在局部作用域中中的变量,只能在局部、局部中的局部被使用
3、两个关键字(在内部打破了外部的生态、尽量的少用)
- global 想在局部修改全局
- nonlocal 想在局部修改外层局部内的变量
4、刚才提到函数及程序的加载顺序:
- 最先加载的就是内置的函数、变量
- 再从上到下将函数名、变量名加载到内存中
- 在函数调用的过程中,才分配一块空间,在函数内部使用
# 所有的函数名的本质都是内存地址
# 所有的变量到底是什么时候被加载到内存里来的?
print(123) # 最先加载的就是内置的函数、变量
# 再从上到下将函数名、变量名加载到内存中
a = 1
b = 2
print(a,b)
def func(): # 在函数调用的过程中,才分配一块空间,在函数内部使用
print(a) # 在函数的内部可以引用函数外部的变量
print(b)
func()
a = 1
a = 2
print(a)
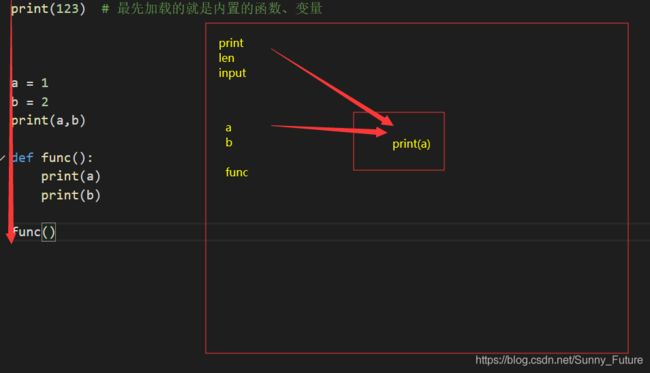
# 程序的加载顺序,加载进来的都是全局变量
# 1.先加载内置的名字
# 2.继续加载文件级别(在函数外部定义的)
# 函数的加载
# 函数内部的变量进入内存需要通过调用
# 函数内部的数据会随着函数的结束而被销毁
# 函数内部的数据是不可以在外部被使用的
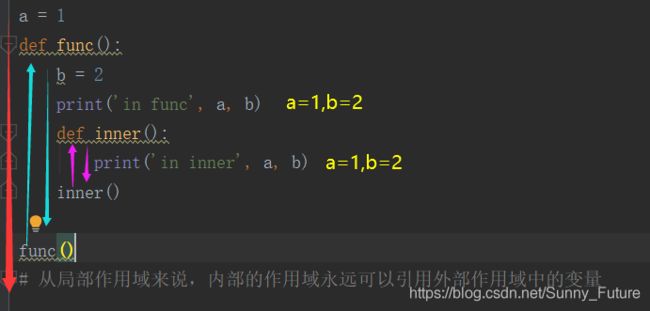
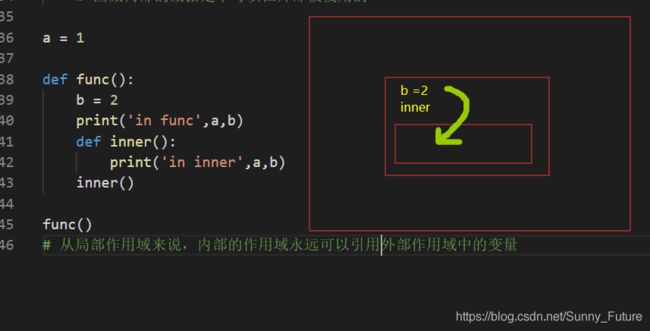
举例:程序从上往下执行的执行顺序
a = 1
def func():
b = 2
print('in func', a, b)
def inner():
print('in inner', a, b)
inner()
func()
# 输出
# in func 1 2
# in inner 1 2
# 从局部作用域来说,内部的作用域永远可以引用外部作用域中的变量
红线代表第一次程序加载(加载全局变量,函数的定义,函数的执行,注意函数定义可变参数的陷阱),青色代表是调用 func 函数内加载,紫色代表 函数 func 内部调用 inner 函数加载顺序
举例:局部变量 与 全局变量的 关联 情况
a = True
def func():
a = False
return a
ret = func()
print(ret) # False ,因为只是修改函数内部的 a ,并未修改全局变量 a
print(a) # True ,全局变量 a 从未被修改过

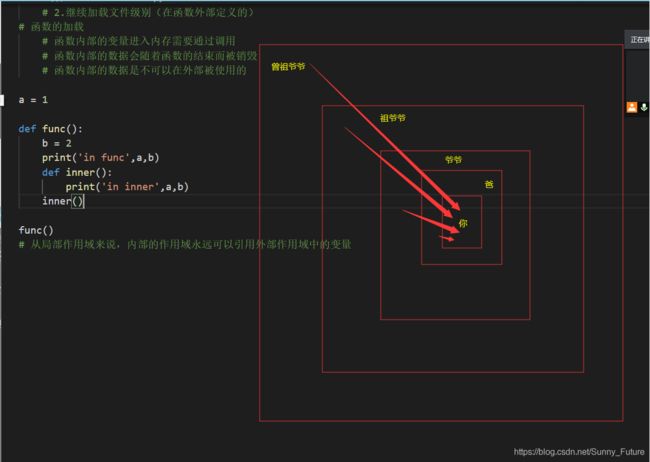
变量关系 大概 如下,内层的变量总是可以使用外层的变量,反之不行。就好比,你可以使用你、你爸、你爷爷、你祖爷爷…的资源,反之不行
4.4 在内部作用域修改外部作用域的变量
- 内部变量 引用 外部变量
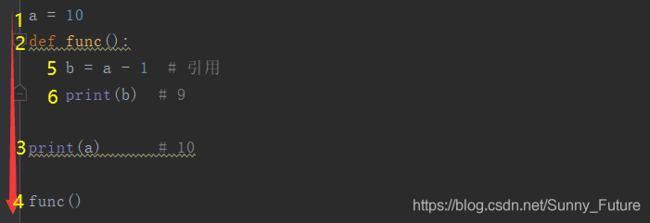
a = 10
def func():
b = a - 1 # 引用
print(b) # 9
print(a) # 10
func()
执行顺序如下,1,2,3,4,5,6,引用全局变量 a
- 局部变量 修改 全局变量
通过 global 来声明局部使用的变量是全局的变量,并且可以执行修改操作
a = 10
def func():
global a # 在一个局部内声明要改变外部的变量
a = a - 1 # 引用
print(a) # 9
func()
print('-->', a) # --> 9
- 引用并修改 当前层的最近一层的 指定变量
通过 nonlocal 声明 引用并可以修改当前层的包含指定变量的最近一层的变量
引用并修改当前局部外的最近一层有b的局部的b变量
a = 10
def func():
b = 9
def inner():
nonlocal b # 引用并修改当前局部外的最近一层有b的局部的b变量
b = b - 1
inner()
print('in func', b)
func() # in func 8

a = 10
def func():
b = 9
def inner():
b = 8
def inn():
nonlocal b
b -=1
inn()
print('in inner', b) # 7?8
inner()
print('in func', b) # 9
func()
# in inner 7
# in func 9
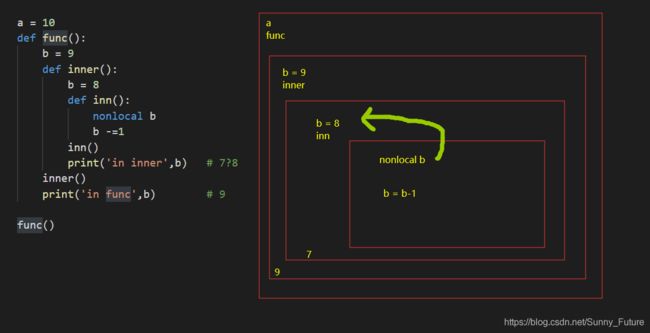
当前层的上一层未找到 b,则 继续往上找,直到找到或者未找到报错为止
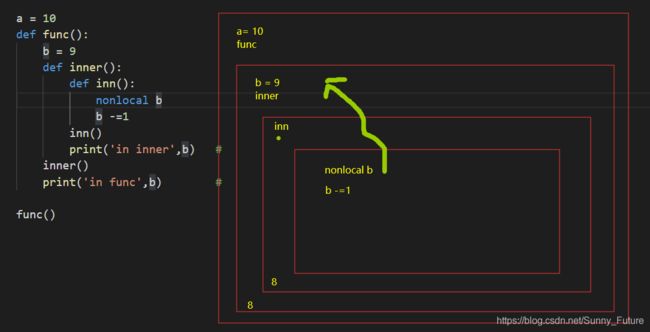
a = 10
def func():
b = 9
def inner():
def inn():
nonlocal b
b -= 1
inn()
print('in inner', b) #
inner()
print('in func', b) #
func()
# in inner 8
# in func 8
总结
- 如果是全局变量 在哪里都可以用
- 如果是局部变量 只能在当前局部的内部使用
- 全局作用域(内置的命名空间(print len input),文件的命名空间(只要不是函数内部定义的))
# 局部可以引用全局作用域的变量 - 局部作用域 (函数内部的,函数与函数之间的命名空间是不共享的)
# 如果是嵌套函数 # 内部的函数可以引用外部函数中定义的变量 - 无论是在函数内部引用全局还是外部函数的变量,都不可以直接修改
# 可以通过global和nonlocal关键字声明之后修改 # 少用、会有隐患
5、匿名函数
5.1 匿名函数的定义及调用
匿名函数 也叫 lambda 表达式
定义:变量 = lambda 参数:返回值
执行:变量(参数)
普通函数是有名的,而 匿名函数就是不需要显式的指定函数名,即匿名函数是一个表达式,并没有函数名,故又称 lambda 表达式
def wahaha():
pass
print(wahaha.__name__) # 函数名为: wahaha
# 定义:变量 = lambda 参数:返回值
# 执行:变量(参数)
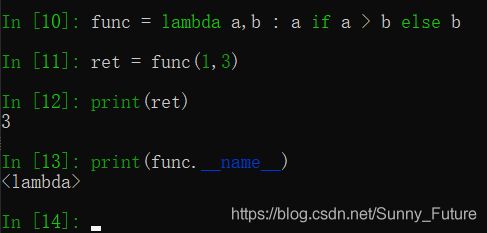
In [10]: func = lambda a,b : a if a > b else b
In [11]: ret = func(1,3)
In [12]: print(ret)
3
In [13]: print(func.__name__)
<lambda>
再举例: 匿名函数就是不需要显式的指定函数名
def cal(a, b):
return a * b
print(cal(2, 3))
cal = lambda a, b: a * b
print(cal(2, 3))
5.2 匿名函数高阶用法
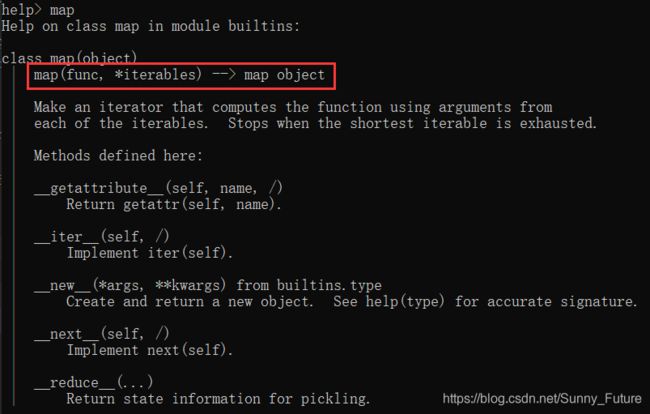
1、先熟悉下 map() 函数
map(函数, 可迭代的数据类型)
2、匿名函数 + map函数 骚操作
ret = map(lambda a: a ** 2, [1, 2, 3, 4])
for i in ret:
print(i)
输出
1
4
9
16
5.3 总结
# lambda表达式
# 变量名 = lambda 参数1,参数2 : 返回值or有返回值的表达式
# 返回值 = 变量名(实参1,实参2)