PyTorch入门实战教程笔记(十五):神经网络与全连接层2
PyTorch入门实战教程笔记(十五):神经网络与全连接层2
全连接层
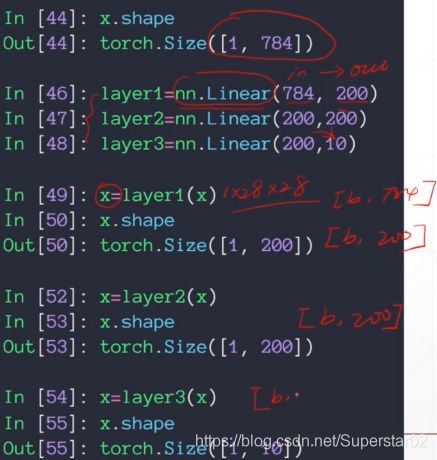
之前我们所写的全连接层,要自己定义w,b 设置梯度标志,需要自己了解操作和计算,需要知道它们的shape等,那么接下来,我们用pytorch自带的nn.Linear操作,来更快捷的进行以上操作。前面说到,使用torch.randn()定义w时,是先ch-out,再ch-in,即torch.randn(200,784,requires_grad = True), 而使用高层API,nn.Linear(784,200), 参数维度是ch-in,ch-out,符合我们常规直觉。详细代码效果如下:
除此之外,F.relu(x, inplace=True),relu函数是从输入x->输出out,他们的shape是保持一致的,可以用inplace操作,可以把多出来一部分内存的操作给省下来,相对应的tensor会减少内存消耗。
如果我们想封装一个网络结构的类,网路结构要继承自nn.Module模块。对于建立一个全连接层网络,第一步实施初始化函数,带上必要的参数,第二步实施forward(),不需要实现backword(), 其由nn.Module 自动提供的,向后求导的过程也不需要额外的写公式,可以使用pytorch的自动求导函数auto_grad()。要新建一个自己的层,确保继承nn.Module这个类,定义初始化,初始化参数带不带都行。然后通过Linear和ReLU,来构建全连接网络。
在构建网络时,要注意后一层的ch-in和前一层的ch-out保持一致。pytorch中的nn.Sequential()函数,其可以添加任何一个继承自nn.module这样一个类,如nn.Linear, nn.ReLU, 等等。甚至可以自己新建一个类,然后通过一行代码把这个类concate到一起,然后forward的时候,一句话就行,x.self.model(x)。这句话使用了model.forward函数,在实例化的时候,直接调用MLP=MLP(), 而这个MLP包含了__call__,里面包含了 .forward()。就可以自动完成前向传播和反向求导的过程啦。

下面对比一下 class-style API和function-style API, 前者使用如nn.Linear, nn.ReLU等,都是大写,必须要先实例化在调用,并且内部的参数,比如w/b参数,是内部的成员,是不能私自访问的,必须借用如.parameters()来访问。后者为F.relu,F.cross-entropy等,小写,可以自己管理这些 tensor,仅仅使用它GPU加速的一个功能。一般来说会优先使用前者,如果做一些具体的底层实例,使用后者。

接下来看一下train的部分,之前我们需要自己提供list:[w1, b1, w2, b2…],现在我们使用了nn.model(),它会自动的吧参数加载到net.parameters()中去,它都会一次返回。然后在for epoch …循环中,logits = net(data),然后在loss.backward即可。还有一个问题,前面说到,初始化对网络的训练也是很重要的,这里我们为什么没有初始化,首先因为我们的w/b已经归Linear管理了,没有暴露给我们,所以我们没法直接的初始化。其次我们用Linear接口时,他有一套自己的初始化方法,它的初始化方法基本上够用了,如果不够用,可以自己写一些代码初始化,后续在讲。

完整的代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 10),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
net = MLP()
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))