unity优化冷启动时间/加载时间总结
本文一部分博主并未实践过,只是做一个总结,如有错误,请指正
目录
一.概念了解
二.优化目的
1.保证游戏流畅度的基础上DrawCall越小越好
2.Statistics统计面板参数
3.打包编译
三.优化方法
1.编译配置方面优化
①.使用IL2CPP进行打包
②.强烈建议使用IL2CPP后端,如果使用IL2CPP,则可以忽略第6条。
③.摄像机的clipping planes用到足够就好,越小回越少drawcall
④.检查场景中的光源
2.代码优化
①.Tolua绑定和Lua资源加载。
②.代码文件可以编译成.dll文件
③.注意设置Web请求的超时时长
④.一些compoment的update可以等loading结束后才执行,减少加载时每帧的开销
⑤.Transform不能放在for循环,getcompoment也是。
⑥.setactive改造为设置进来时判断是否与之前的值一样。因为本身setactive每次真是调用都回有gc
⑦.string不能直接加
⑧.parent用setparent替换。
⑨.协程用得多,这块尽量用update或lateupdate替换,因为协程本身在unity会创建实体来管理,会产生少量得gc
⑩.减少new waitforsecond的使用并且把他存在一个变量中
⑪.特效的order的问题,同一个材质的应该放在同一个order下,不同的材质一定要放在不同的order下。
⑫.去掉了加载模型后的卸载行为
⑬.Aup另一个线程去做gpu数据
⑭.减少不必要使用的插件
⑮.一些重复加载的资源,可以保存下来
⑯.字典的key不能用枚举
3.资源优化
①.尽量少的使用Resources方式管理资源,建议使用AssetBundle的方式管理
②.纹理资源选择合适的压缩格式进行压缩
③.模型优化
(1).网格资源
(2).LOD层级细节技术
(3).OcclusionCulling遮挡剔除技术
(4).Lightmapping光照贴图技术
(5).Mesh合并
(6) 去掉多余的mesh
(8).骨骼动画开启optimizeGameObjects选项,减少骨骼运算。
(9).关闭 Read/Write Enabled 设置
(10).使用Mesh压缩
④.音乐加载优化
⑤.资源重复利用
⑥.Shader编译时间过长。
⑦.调整层级,把相同的altas放在一个顺序的层级里
⑦.资源审查
⑧.资源后处理
4.UI优化
①.有一些ui上挂了刚体,但其实ui是没必要用刚体的,增加额外的组件会增加额外的开销。(ngui会加上rigidbody)
②.移除ui图片的read/write,mipmap
5.设计优化
①.启动场景不放模型,只放UI
②.项目中添加一个Loading场景,这个场景会是游戏启动的第一个场景。
6.内存优化
①.设定了若干包围盒,勾画出一块块小区域。一旦玩家离开包围盒太远,程序就把包围盒里面的物件卸载出内存。包围盒略微扩大,允许包围盒重叠,并可以用多个包围盒来定义一个区域。同一个场景物件只可以属于一个区域,即使它的位置在多个区域内。(区域可以重叠)
②.放置Mono内存泄漏
参考:
一.概念了解
app冷启动: 当应用启动时,后台没有该应用的进程,这时系统会重新创建一个新的进程分配给该应用, 这个启动方式就叫做冷启动(后台不存在该应用进程)。
app热启动: 当应用已经被打开, 但是被按下返回键、Home键等按键时回到桌面或者是其他程序的时候,再重新打开该app时, 这个方式叫做热启动(后台已经存在该应用进程)。
二.优化目的
1.保证游戏流畅度的基础上DrawCall越小越好
DrawCall即为由CPU下达命令,调用OpenGL或DirectX接口进行解析并由GPU进行渲染显示的过程称为一次DrawCall。
在Unity中查看DrawCall参数,Window / Profiler 或者Ctrl+7 快捷键打开 Profiler性能分析器面板。
2.Statistics统计面板参数
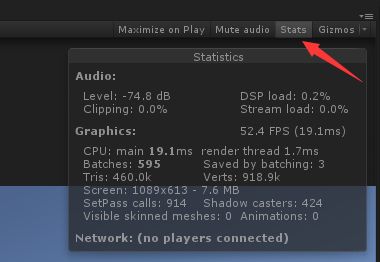
FPS(帧数):越大越好
CPU(处理器计算速度):越低越好
render thread(渲染线程,GPU渲染所需要的时间):越低越好
Batches(渲染批次):与DrawCall关联,是Unity自动分类的渲染批次
Tris(三角面数):相机视野范围内的三角面数量
Verts(顶点数):相机视野范围内的顶点数量
SetPass calls:Unity中的Shader中包含很多Pass块,每当GPU即将去运行一个Pass块之前,就会产生一个“SetPass call”,在描述性能开销上更有说服力
3.打包编译
- 放到Plugins目录下的贴图不会打包进去
- 放到Plugins目录下的dll会自动打包,代码也会打包
- 放在Resources目录下的资源会自动打包
- 放在StreamingAssets目录下的贴图和视屏资源会自动打包,且log日志里面没有统计到
- 放在Standard Assets目录下的贴图不会自动打包
- Assets下的所有代码都会打包
三.优化方法
相比于Android或者iOS原生App,Unity3D引擎开发的游戏在冷启动时间上确实比较长。三星SM-N9008手机上的测试结果是一个不算大的项目,如果使用Mono后端编译,则需要10秒左右的冷启动时间,而如果使用IL2CPP后端编译,则冷启动时间为7秒左右。
1.编译配置方面优化
①.使用IL2CPP进行打包
IL2CPP相比于Mono确实能够加快冷启动时间,这是可以预期的。因为在Mono编译的情况下,每个.cs文件都是一个TextAsset文件,而所有的.cs文件都需要在冷启动时候全部加载到内存中,这些碎片化的文件加载操作都会占用冷启动时间。关于冷启动需要加载哪些文件的分析,可以参考Unity3D游戏在启动时都默认加载哪些资源。而IL2CPP会把所有的C#代码编译成C 代码,然后再进行编译、链接等操作,这样就减少了C#、DLL所带来的开销。
②.强烈建议使用IL2CPP后端,如果使用IL2CPP,则可以忽略第6条。
③.摄像机的clipping planes用到足够就好,越小回越少drawcall
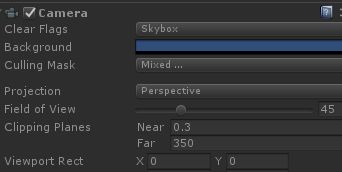
④.检查场景中的光源
场景里使用灯光,会影响了某些物体的阴影,让drawcall变多,基本上放置一个environment light以及一个directional light就行了
2.代码优化
①.Tolua绑定和Lua资源加载。
这种是每次游戏启动都会有的,ToLua接口绑定需要一定的时间,我们在确保前期不会使用Lua的情况下采用多线程的方式进行绑定和加载,保证主线程不会卡住。
②.代码文件可以编译成.dll文件
减少大量TextAsset文件导致的碎片化加载时间。
③.注意设置Web请求的超时时长
在游戏启动的时候做了一些hook的事情,会有Web请求,后来我们遇到一个情况是在很多机器上会黑屏等待30s甚至60s这样的时长,后来发现是因为这个Web请求没有设置超时时间,于是使用了机器默认的超时时间,在不同设备上不同,比如红米2A上会有接近1分钟的超时限制。这个很坑,只是因为那个非必须的Web服务没有正确开启,导致排查了很长时间。
Native层增加界面,减少黑屏等待,提升玩家体验。这个并不能真正解决问题,只是一种缓解手段,等到优化做到位了,其实也就不需要了。
④.一些compoment的update可以等loading结束后才执行,减少加载时每帧的开销
⑤.Transform不能放在for循环,getcompoment也是。
⑥.setactive改造为设置进来时判断是否与之前的值一样。因为本身setactive每次真是调用都回有gc
⑦.string不能直接加
⑧.parent用setparent替换。
⑨.协程用得多,这块尽量用update或lateupdate替换,因为协程本身在unity会创建实体来管理,会产生少量得gc
⑩.减少new waitforsecond的使用并且把他存在一个变量中
⑪.特效的order的问题,同一个材质的应该放在同一个order下,不同的材质一定要放在不同的order下。
⑫.去掉了加载模型后的卸载行为
⑬.Aup另一个线程去做gpu数据
⑭.减少不必要使用的插件
像我为了使用easytouch中的swift手势直接导入了一整个插件,因此有些小功能还是自己写的好,而且还能优化安装包大小,一举两得
⑮.一些重复加载的资源,可以保存下来
⑯.字典的key不能用枚举
3.资源优化
①.尽量少的使用Resources方式管理资源,建议使用AssetBundle的方式管理
此项还未测试,因为公司初版不适用AB包方式
Resources目录下面的所有资源会在ResourceManager中记录下来,而ResourceManager就是一个文件,通常是一个YAML格式的文本文件。而这个文件是会在冷启动时加载的。所以Resources目录下面的有越多的资源,那么这个ResourceManager就会越大,加载时间也会越长。
使用Resources方式管理资源还有一个坏处,就是所有的资源都是统一管理的,这样的资源的管理粒度没办法控制。建议使用AssetBundle的方式管理,这样可以使用多个AssetBundle来管理资源。把在Loading场景中需要的最小资源集放在一个AssetBundle中,这样在冷启动时启动Loading场景时,只需要加载一个AssetBundle即可。选择合适的粒度管理AssetBundle,可以在合适的时候加载某一个AssetBundle,不使用时就可以卸载某一个AssetBundle。
在Loading场景中,添加一个进度条,然后同步加载进入主场景所需要的AssetBundle,这样用户就不会感到等待时间太烦躁了。同步加载要比异步加载时间更短。
减少冗余资源和重复资源方面:
A.Resources目录下的资源不管是否被引用,都会打包进安装包,不使用的资源不要放在Resources目录下
B.不同目录下的相同资源文件,如果都被引用,那么都会打包进资源包,造成冗余,保证同一个资源文件在项目中只存放在一个目录位置
②.纹理资源选择合适的压缩格式进行压缩
纹理资源在游戏中一般是最大的资源,选择合适的压缩格式进行压缩,既可以减少内存占用,又能够加快资源的加载速度。压缩格式的选择要从显示效果和压缩率上进行权衡。一般在Android上使用ETC格式,在iOS上使用PVRTC格式,在某些情况下,可能还可以考虑使用Alpha通道分离技术进行压缩处理。
(1).严格控制RGBA32和ARGB32纹理的使用,在保证视觉效果的前提下,尽可能采用“够用就好”的原则,降低纹理资源的分辨率,以及使用硬件支持的纹理格式。
(2).在硬件格式(ETC、PVRTC)无法满足视觉效果时,RGBA16格式是一种较为理想的折中选择,既可以增加视觉效果,又可以保持较低的加载耗时。
(3).严格检查纹理资源的Mipmap功能,特别注意UI纹理的Mipmap是否开启。在UWA测评过的项目中,有不少项目的UI纹理均开启了Mipmap功能,不仅造成了内存占用上的浪费,同时也增加了不小的加载时间。
(4).ETC2对于支持OpenGL ES3.0的Android移动设备来说,是一个很好的处理半透明的纹理格式。但是,如果你的游戏需要在大量OpenGL ES2.0的设备上进行运行,那么我们不建议使用ETC2格式纹理。因为不仅会造成大量的内存占用(ETC2转成RGBA32),同时也增加一定的加载时间。下图为测试2中所用的测试纹理在三星S3和S4设备上加载性能表现。可以看出,在OpenGL ES2.0设备上,ETC2格式纹理的加载要明显高于ETC1格式,且略高于RGBA16格式纹理。因此,建议研发团队在项目中谨慎使用ETC2格式纹理。
(5).都去掉alpha通道,作为背景展示的图片,基本都没有透明要求,有特殊要求的则放到atlas里面
a. Loading图这类需要比较精细的,则把图片设置为Automatic TrueColor,设置真彩色,保证不失真
b. 地图、缩略图、UI背景图等等要求不精细的,则可以设置为自动压缩格式(有压缩情况,都需要图片宽高尺寸是2的幂,可以在Advance里面设置toNearest)
(6).关闭 Read/Write Enabled 设置
这个 Read/Write Enabled 的设置会造成贴图在内存里变成两份,一份在 GPU 上一份在 CPU 可以寻址的内存上。这是因为大多数平台,把数据从 GPU 内存读回 CPU 很慢。从 GPU 内存读取一张贴图到暂存区给 CPU 程序用(例如:Texture.GetPixel)会导致效能很差。这个设定在 Unity 里预设是关闭的,但要避免误勾这个选项。
注意:ios下会自动把图片宽高拉伸为2的幂次方尺寸,这样会导致图片显示失真,解决办法是制作图片的时候就保证是2的幂大小。如果图片显示的区域确实不能做出2的幂大小,可以用补黑边的方式把图片做出2的幂大小,设置图片的时候,就需要调整图片的UV
要点:android下,带alpha通道的图片,自动压缩是以ETC2 8bit的方式压缩的,不带alpha通道,是压缩成ETC 4bit的格式(ETC2 支持alpha通道),ios下是压缩成PVRTC 4格式。手机硬件对各种格式图片的加载效率不一样,RGBA32是最慢的。所以需要对图片进行处理,改压缩方式,ETC和pvr是加载最快的。
③.模型优化
(1).网格资源
- 在保证视觉效果的前提下,尽可能采用“够用就好”的原则,即降低网格资源的顶点数量和面片数量;
- 研发团队对于顶点属性的使用需谨慎处理。通过以上分析可以看出,顶点属性越多,则内存占用越高,加载时间越长;
- 如果在项目运行过程中对网格资源数据不进行读写操作(比如Morphing动画等),那么建议将Read/Write功能关闭,既可以提升加载效率,又可以大幅度降低内存占用。
(2).LOD层级细节技术
此技术需要美工的配合,提供给程序多个不同三角面数的模型
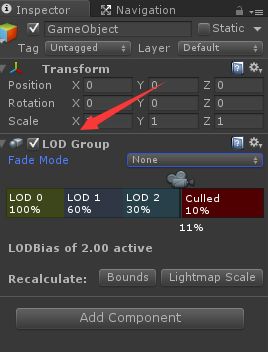
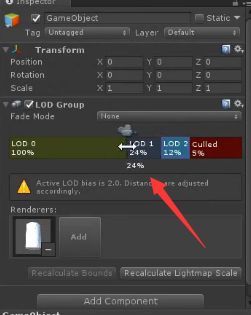
在场景中新建一个空的游戏物体,并添加LOD Group组件,如下图所示:
并将美工提供的三种不同精度的模型按照精度的大小依次拖入到LOD0、LOD1、LOD2中
此时,场景中渲染显示的模型会根据相机与模型的距离进行切换显示,具体的切换显示距离可拖动组件中的条形框大小进行自定义,这样便达到了近处渲染精模,远处渲染粗模甚至不渲染来减少GPU消耗的目的
(3).OcclusionCulling遮挡剔除技术
当场景中有大量模型需要渲染时,应用遮挡剔除可实现减少DrawCall提升性能的效果
首先选中所有需要进行遮挡剔除的模型,并设置其occluder(遮挡体)和occludee(被遮挡体),有的物体可以是遮挡体同时也是被遮挡体。
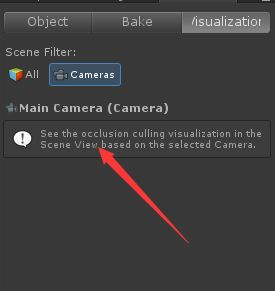
接下来Window / Occlusion Culling 打开遮挡剔除面板如下图:
选中遮挡剔除选项,烘焙
烘焙完成后,设置好显示视野的相机

(4).Lightmapping光照贴图技术
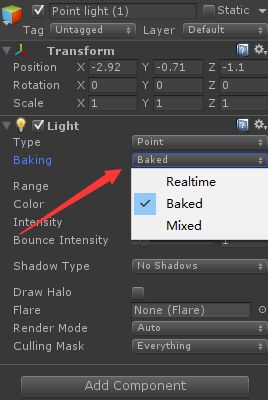
首先将需要进行光照贴图的游戏物体设置为Lightmap Static
其次将用于光照贴图的所有光源设置为Baked模式
最后Window / Lighting 打开灯光面板,进行烘焙,面板如下
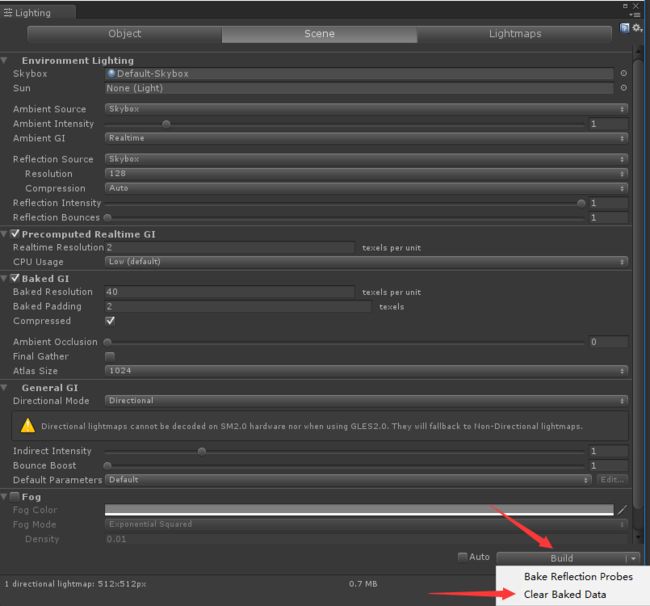
其中Build后会在当前场景所在的文件夹中生成一个光照贴图文件,我们也可以点击Clear Baked Data 按钮进行光照贴图的清理操作
之后无论场景中的光源是否激活,均显示光照效果,效果图如下:
·

(5).Mesh合并
当场景中模型非常多,不妨试一下模型合并技术,可以在3dMax或其他建模软件上进行操作,也可在Unity中进行操作,这里我仅介绍Unity中的模型合并方法。
前提:合并的物体必须是相同的材质,否则合并之后赋值多个材质并不能起到优化作用
首先,将下述代码放在Assets / Editor 文件夹下
其次,在场景中需要合并的模型放在一个空物体下
然后,点击选中空物体并点击上方的菜单栏按钮MeshCombine / CombineChildren进行合并所有子物体Mesh
最后,自行更改模型中的材质,位置等参数即可
using UnityEngine;
using System.Collections;
using UnityEditor;
public class CombineMesh : MonoBehaviour {
//菜单按钮静态触发
[MenuItem( "MeshCombine/CombineChildren")]
static void CreatMeshCombine()
{
//获取到当前点击的游戏物体
Transform tSelect = (Selection.activeGameObject).transform;
//如果当前点击的游戏物体无子物体,则无操作
if (tSelect.childCount < 1)
{
return;
}
//确保当前点击的游戏物体身上有MeshFilter组件
if (!tSelect.GetComponent())
{
tSelect.gameObject.AddComponent();
}
//确保当前点击的游戏物体身上有MeshRenderer组件
if (!tSelect.GetComponent())
{
tSelect.gameObject.AddComponent();
}
//获取到所有子物体的MeshFilter组件
MeshFilter[] tFilters = tSelect.GetComponentsInChildren();
//根据所有MeshFilter组件的个数申请一个用于Mesh联合的类存储信息
CombineInstance[] tCombiners = new CombineInstance[tFilters.Length];
//遍历所有子物体的网格信息进行存储
for (int i = 0; i < tFilters .Length ; i++)
{
//记录网格
tCombiners[i].mesh = tFilters[i].sharedMesh;
//记录位置
tCombiners[i].transform = tFilters[i].transform.localToWorldMatrix;
}
//新申请一个网格用于显示组合后的游戏物体
Mesh tFinalMesh = new Mesh();
//重命名Mesh
tFinalMesh.name = "tCombineMesh";
//调用Unity内置方法组合新Mesh网格
tFinalMesh.CombineMeshes(tCombiners);
//赋值组合后的Mesh网格给选中的物体
tSelect.GetComponent().sharedMesh = tFinalMesh;
//赋值新的材质
tSelect.GetComponent().material = new Material(Shader.Find("VertexLit"));
}
} 效果图如下:
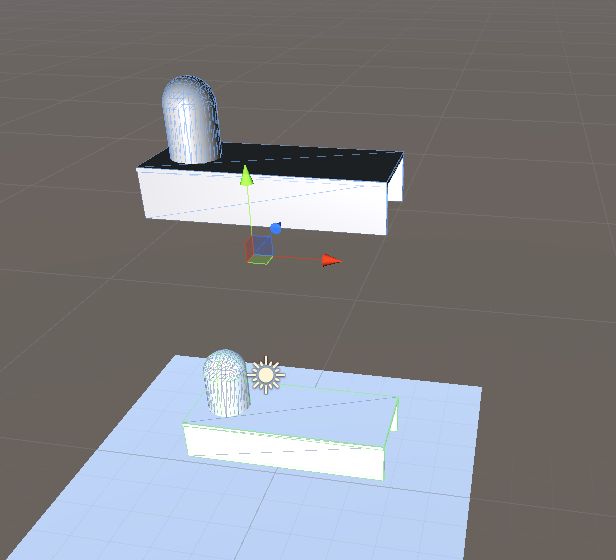
(6) 去掉多余的mesh
(8).骨骼动画开启optimizeGameObjects选项,减少骨骼运算。
ModelImporter.optimizeGameObjects 能够优化骨骼动画,将无用的骨骼合并,实际测试发现,设置此选项后的蒙皮骨骼动画模型,不受动态缩放影响,只能保持导入的大小,大规模同屏角色肯定是效率有明显的影响,但是对于动态改变模型大小的需求该方法不太适用。
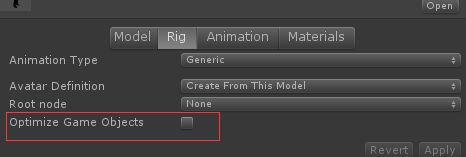
打勾后所有的骨架对应的 Transform 结构都会被移除,如果模型骨架结构中有特定的部位需要露出方便控制(例如模型的手部要用来握住武器),则可以把它列在“ExtraTransforms”白名单中。
(9).关闭 Read/Write Enabled 设置
当项目执行时想用程序来修改 Mesh,或者如果 Mesh 要用作 MeshCollider 的话,这里需要打勾。反之如果模型没用在MeshCollider,也没用程序来修改 Mesh 的话,关闭这里可以省下一半的内存。
(10).使用Mesh压缩
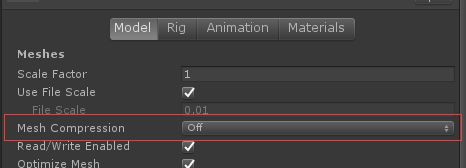
开启 Mesh compression 选项会缩短用来表示模型数据不同信道的浮点数字元长度,这会移除一定的精确度并可能造成可见的变化,使用这个之前最好先让美术检查过这种损失在允许范围内。
各个压缩等级使用的位长度在 ModelImporterMeshCompression 脚本里有介绍。
请记得,可以针对不同信道使用不同等级的压缩,所以项目可以只针对切线向量(Tangent)和法向量(Normal)压缩但不压缩 UV 和顶点位置。
④.音乐加载优化
(1).Mac / PC 适用于 Ogg Vorbis格式音频,而Mp3适用于移动端,不过音质会下降
长时间音乐(背景音乐)压缩格式:mp3
短时间音乐(攻击等等)一般不压缩存储格式为:wav
(2).加载模式
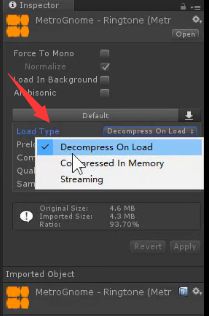
Decompress On Load:适用于小文件
Compressed in Memory:使用于大文件
Streaming:以流的形式便加载边播放(对CPU消耗较大一般不采用)
如果是交互的音效应该不能压缩,不然因为unity要解压,需要耗时所以点击时不能做到实时。关键再选择PCM
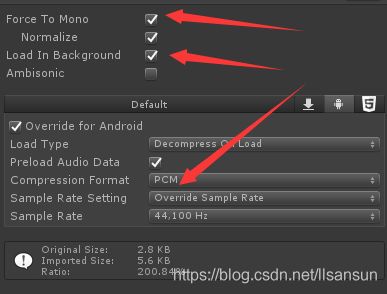
(3) .降低音频的取样
调低取样能进一步降低内存消耗和最终项目的大小,可以和音效设计师协调找出最小最能接受的音源质量。参考SetCompressionBitrate。
(4).强制音效用单声道
只有少数的手机装置真的有立体声喇叭,而将音效强制设定为单声道能让内存的消耗减半。就算游戏会输出部份的立体声,有些单声道像是 UI 音效还是可以开启这个选项。
(5).采用平台支持的压缩设定
采用硬件支持的音源压缩格式。所有的iOS设备都有 MP3 硬件解压缩能力,而大多数的 Android 设备都有支持 Vorbis。
此外,可以直接将未压缩的声音文件导入 Unity 里,因为 Unity 会在打包项目时会重新压缩。所以不需要先压缩再导入Unity,这只会降低音效质量。
⑤.资源重复利用
unity scrollview 优化 高效重复利用 避免大量初始化时间过长
类似该文章中可以进行加载显示部分,然后再根据操作进行循环利用(可以使用资源池实现)
⑥.Shader编译时间过长。
如果只有游戏安装之后第一次启动时间过长,一个很大的可能是shader编译,之后游戏启动因为有了Cache所以会快很多。这种情况的话建议查看下Always Include的Shader内容和变体,使用shadervariantcollection等方案替代。
(1)、Shader资源的物理体积与内存占用虽然很小,但其加载耗时开销的CPU占用很高,这主要是因为Shader的解析CPU开销很高,成为了Shader资源加载的性能瓶颈;
(2)、Mobile/Particles Additive在解析方面的耗时远小于Mobile/Diffuse、Mobile/Bumped Diffsue甚至Mobile/VertexLit;
(3)、除Mobile/Particles Additive外,其他三个主流Shader在加载时均会造成明显的降帧,甚至卡顿。因此,研发团队应尽可能避免在非切换场景时刻进行Shader的加载操作;
(4)、尽量减少复杂的数学运算,尽量减少Discard操作
(5)、随着硬件设备性能的提升,其解析效率差异越来越不明显。
对于Shader资源的管理建议如下:
(1)、在保证渲染效果和项目需求的情况下,尽可能降低Shader的Keyword数量,以提升Shader的加载效率;
(2)、对于简单Shader,可尝试去除Fallback操作,该方法非常适合于目前正在大量使用的Mobile/Diffuse、Mobile/Bumped Diffuse等Built-in Shader;
(3)、尽可能对Shader进行单独、依赖关系打包并对其进行预加载,以降低后续不必要的加载开销。
⑦.调整层级,把相同的altas放在一个顺序的层级里
调整前 :
调整后 :
如果遇上调整层级还是具有相同材质的静态物体并没放到一个drawcall,还是一个个绘制
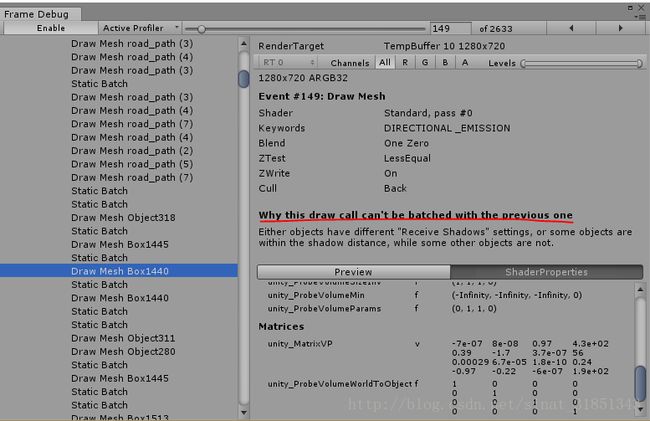
看了下这几个绘制的物体receive shadow都是勾选的,所以问题应该出在了within the shadow distance这里。就是这些物体受到了不同的阴影影响。比如2块石头,一块石头在树下,受到了树影子的影响,被放到一个drawcall里,另一块石头就是没有受到任何遮挡,所以直接被放在一个drawcall。它们就不能在一个drawcall里了。
因此要判断是否需要阴影进行取出阴影:
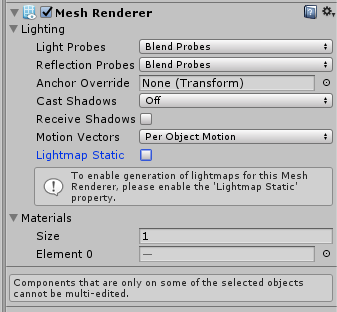
cast shadows 设为off,取消勾选receive shadows。如果不需要让它影响lightmap,取消勾选lightmap static
⑦.资源审查
对于较大规模的项目,最好准备一道自动的防线防范人为失误。例如写一段简单的检查程序确保没有任何人能在项目加入一张没压缩的 4K 贴图。
或许你会觉得不可能,但这问题我们真的很常见。没有压缩的 4K 贴图会占用大约 60mb 的内存空间,在低端的手机设备(例如 iPhone 4s)上,整个项目用掉超过 180mb~200mb 就会很危险。有时候你的游戏在好的手机上跑没问题,在差的手机上跑会宕机,不一定是硬件的问题。如果犯这种错误,这张贴图会无端占用应用程序四分之一到三分之一的可用内存,造成很难追踪的内存不足错误。
⑧.资源后处理
Unity 编辑器里的 AssetPostprocessor 类别可以用在 Unity 项目上实行某些基本限制。这个类别在资源导入时会收到一个回调。使用方法即继承 AssetPostprocessor 并实作一个或多个 OnPreprocess 方法,重要的包含:
OnPreprocessTexture
OnPreprocessModel
OnPreprocessAnimation
OnPreprocessAudio
public class ReadOnlyModelPostprocessor : AssetPostprocessor {
public void OnPreprocessModel() {
ModelImporter modelImporter = (ModelImporter)assetImporter;
if(modelImporter.isReadable) {
modelImporter.isReadable = false;
modelImporter.SaveAndReimport();
}
}
} 这是一个简单的 AssetPostprocessor 限制规则范例
每当导入模型到项目或模型的导入设定(Import settings)被修改时会呼叫这个类别,这里程序只是检查可否读写模型的设置 isReadable 属性,如果是 true 就会改为 false,存盘后重新导入资源。
请注意,呼叫 SaveAndReimport 会导致这段程序会被再次呼叫!但由于设置已经被改为 false,所以不会无穷递归下去。
4.UI优化
①.有一些ui上挂了刚体,但其实ui是没必要用刚体的,增加额外的组件会增加额外的开销。(ngui会加上rigidbody)
②.移除ui图片的read/write,mipmap
5.设计优化
①.启动场景不放模型,只放UI
公司初版APP模型很大,也是放在本地,但是我在第一个场景初始化的时候加载了模型,更改之后快了10s左右
②.项目中添加一个Loading场景,这个场景会是游戏启动的第一个场景。
在Loading场景中尽量少的依赖,尽量少的纹理依赖、AssetBundle依赖、代码依赖,总之,这个Loading场景一定要尽量少的依赖,这个场景一定要尽量简单,这样才能保证尽快的加载速度。
6.内存优化
在当下的手机及平板硬件设备条件下,操作系统留给应用的可用内存并不多,大约只有 500M 左右。
和 PC 环境不同,手机上是交换分区的机制来对应一些临时突发性内存需求的。而手机必须保证一些系统服务(某些高优先级后台业务)的运行,所以在接电话、收取推送等等意外任务发生时,有可能多占用一些内存,导致操作系统杀掉前台任务让出资源。根据实际测试,游戏想跑在当前主流高端手机上必须把自己的内存占用峰值控制在 400M 内存以下,350 M 会是一个合理的值
①.设定了若干包围盒,勾画出一块块小区域。一旦玩家离开包围盒太远,程序就把包围盒里面的物件卸载出内存。包围盒略微扩大,允许包围盒重叠,并可以用多个包围盒来定义一个区域。同一个场景物件只可以属于一个区域,即使它的位置在多个区域内。(区域可以重叠)
所有物件都标记分类出外观物件和细节物件。比如一个城市的城墙就是外观物件,而城内的所有东西都是细节物件;一片树林的大颗植物是外观物件,地面的花花草草是细节物件。一般情况下,大部分物件都默认是细节物件,只有少数需要远观的才标记成外观。这点,其实原本就做了视距分层,只不过是为了在渲染时做显示剔除用的,并没有用于控制内存。而这次,需要对外观物件和细节物件单独打包分类,便于分开卸载。
当玩家处于一个区域内部时,必须保证这个区域的外观物件和细节物件都加载到内存。如果之前并不在内存,也需要开启异步加载的流程。当一个玩家距离另一个区域比较近时,只需要确保该区域的外观物件在内存即可,可以卸载任何不在区域的细节物件。
②.放置Mono内存泄漏
(1)出现原因
1. “忘记”清除对该无用对象的引用
并非只有显示调用new才会分配内存,很多隐式的分配是不容易被发现的,例如产生一个List来存储数据,缓存了服务器下发的一份配置,产生一个字符串等等,这些操作都会产生内存的分配。你分配几十K,他分配几十K,一会儿内存就没了。
其次,有一点需要说明的是,在Unity环境下,Mono堆内存的占用,是只会增加不会减少的。具体来说,可以将Mono堆,理解为一个内存池,每次Mono内存的申请,都会在池内进行分配;释放的时候,也是归还给池,而不会归还给操作系统。如果某次分配,发现池内内存不够了,则会对池进行扩建——向操作系统申请更多的内存扩大池以满足该次的内存分配。需要注意的是,每次对池的扩建,都是一次较大的内存分配,每次扩建,都会将池扩大6-10M左右(此处无官方数据,是观察所得)。
2.资源中的泄漏 – Native内存泄漏(资源加载之后占有了内存,但是在资源不用之后,没有将资源卸载导致内存的无谓占用。 )
Unity的内存回收是需要主动触发的(Resources.UnloadUnusedAssets()),GC也提供了同样的接口GC.Collect() 用来主动触发垃圾回收,Resources.UnloadUnusedAssets()内部本身就会调用GC.Collect(),Unity还提供了另外一个更加暴力的方式——Resources.UnloadAsset()来卸载资源,但是这个接口无论资源是不是“垃圾”,都会直接删除,是一个很危险的接口,建议确定资源不使用的情况下,再调用该接口。为了避免游戏卡顿,建议在加载环节来处理垃圾回收的操作。
再来看一下为什么会有资源的泄漏。首先和代码侧的泄漏一样,由于“存在该释放却没有释放的错误引用”,导致回收机制认为目标对象不是“垃圾”,以至于不能被回收,这也是最常见的一种情况。
针对资源,还有一种典型的泄漏情况。由于资源卸载是主动触发的,那么清除对资源引用的时机就显得尤为重要。现在游戏的逻辑趋于复杂化,同时如果有新成员加入项目组,也未必能够清楚地了解所有资源管理的细节,如果“在触发了资源卸载之后,才清除对资源引用”,同样也会出现内存泄漏了。
还有一种资源上的泄漏,是因为Unity的一些接口在调用时会产生一份拷贝(例如Renderer.Material参考https://docs.unity3d.com/ScriptReference/Renderer-material.html),如果在使用上不注意的话,运行时会产生较多的资源拷贝,造成内存的无端浪费。
具体请看 : Unity中的内存泄漏
参考:
App冷启动、热启动介绍以及优化启动的实现方式,解决启动白屏问题
在Unity3D游戏如何加快冷启动时间
Unity启动耗时优化
iOS 优化程序冷启动时间
关于Unity加载优化,你可能遇到这些问题
unity3d 加载优化建议 总结 from 侑虎科技
unity scrollview 优化 高效重复利用 避免大量初始化时间过长
关于Unity性能优化的一些方法
unity加载优化小结
批处理优化(官方链接)
Unity3D性能优化最佳实践(四)资源审查
unity-Profiler调试Android的正确姿势(mumu模拟器)
unity 打包编译记录
Unity3D 的大场景内存优化
Unity中的内存泄漏
资源加载性能测试代码