Pytorch打卡第9天:10种优化器、学习率、动量
任务
- 掌握常用优化器SGD,了解10种优化器
知识点
基本知识
- pytorch的优化器: 管理并更新模型中可学习参数的值,使得模型输出更接近真实标签
- 导数:函数在指定坐标轴上的变化率
- 方向导数:指定方向上的变化率
- 梯度:一个向量,方向为方向导数 取得最大值的方向
基本属性
• defaults:优化器超参数
• state:参数的缓存,如momentum的缓存
• params_groups:管理的参数组
• _step_count:记录更新次数,学习率调整中使用
基本方法
import os
import torch
import torch.nn as nn
import torch.optim as optim
from tools.common_tools2 import set_seed
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
set_seed(1)
weight = torch.randn((2, 2), requires_grad=True)
weight.grad = torch.ones((2, 2))
optimizer = optim.SGD([weight], lr=0.1)
• zero_grad():清空所管理参数的梯度
pytorch特性:张量梯度不自动清零
# ----------------------------------- zero_grad
# flag = 0
flag = 1
if flag:
print("weight befor step:{}".format(weight.data))
optimizer.step()
print("weight after strp:{}".format(weight.data))
print("weight in optimizer:{}\nweight in weight:{}\n".format(id(optimizer.param_groups[0]['params'][0]), id(weight)))
print("weight.grad is {}\n".format(weight.grad))
optimizer.zero_grad()
print("after optimizer.zerograd(), weight.grad is\n {}".format(weight.grad))
输出:
weight befor step:tensor([[0.6614, 0.2669],
[0.0617, 0.6213]])
weight after strp:tensor([[ 0.5614, 0.1669],
[-0.0383, 0.5213]])
weight in optimizer:4384748480
weight in weight:4384748480
weight.grad is tensor([[1., 1.],
[1., 1.]])
after optimizer.zerograd(), weight.grad is
tensor([[0., 0.],
[0., 0.]])
• step():执行一步更新
# ----------------------------------- step
# flag = 0
flag = 1
if flag:
print("weight before step:{}".format(weight.data))
optimizer.step()
print("weight after step:{}".format(weight.data))
输出:
weight before step:tensor([[0.6614, 0.2669],
[0.0617, 0.6213]])
weight after step:tensor([[ 0.5614, 0.1669],
[-0.0383, 0.5213]])
• add_param_group():添加参数组
# ----------------------------------- add_param_group
# flag = 0
flag = 1
if flag:
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
w2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({"params": w2, 'lr': 0.0001})
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
输出:
optimizer.param_groups is
[{'params': [tensor([[0.6614, 0.2669],
[0.0617, 0.6213]], requires_grad=True)], 'lr': 0.1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
optimizer.param_groups is
[{'params': [tensor([[0.6614, 0.2669],
[0.0617, 0.6213]], requires_grad=True)], 'lr': 0.1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}, {'params': [tensor([[-0.4519, -0.1661, -1.5228],
[ 0.3817, -1.0276, -0.5631],
[-0.8923, -0.0583, -0.1955]], requires_grad=True)], 'lr': 0.0001, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
• state_dict():获取优化器当前状态信息字典
# ----------------------------------- state_dict
# flag = 0
flag = 1
if flag:
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
opt_state_dict = optimizer.state_dict()
print("state_dict before step:\n", opt_state_dict)
for i in range(10):
optimizer.step()
print("state_dict after step:\n", optimizer.state_dict())
torch.save(optimizer.state_dict(), os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
输出:
state_dict before step:
{'state': {}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4384027344]}]}
state_dict after step:
{'state': {4384027344: {'momentum_buffer': tensor([[6.5132, 6.5132],
[6.5132, 6.5132]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4384027344]}]}
• load_state_dict() :加载状态信息字典
# -----------------------------------load state_dict
flag = 0
flag = 1
if flag:
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
state_dict = torch.load(os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
print('state_dict before load state:\n', optimizer.state_dict())
optimizer.load_state_dict(state_dict)
print('state_dict after load state:\n', optimizer.state_dict())
输出:
state_dict before load state:
{'state': {}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4508197744]}]}
state_dict after load state:
{'state': {4508197744: {'momentum_buffer': tensor([[6.5132, 6.5132],
[6.5132, 6.5132]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4508197744]}]}
学习率
- 学习率(learning rate)控制更新的步伐
- 梯度下降: + = − ()
- + = − LR * ()
import torch
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
def func(x_t):
return torch.pow(2 * x_t, 2)
# init
x = torch.tensor([2.], requires_grad=True)
# ------------------------------ plot data
flag = 0
# flag = 1
if flag:
x_t = torch.linspace(-3, 3, 100)
y = func(x_t)
plt.plot(x_t.numpy(), y.numpy(), label='y=4*x^2')
plt.grid()
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()
# ------------------------------ gradient descent
flag = 0
# flag = 1
if flag:
iter_rec, loss_rec, x_rec = list(), list(), list()
lr = 0.01
max_iteration = 20
for i in range(max_iteration):
y = func(x)
y.backward()
print("Iter:{}, X:{:8}, X.grad:{:8}, loss:{:10}".format(
i, x.detach().numpy()[0], x.grad.detach().numpy()[0], y.item()))
x_rec.append(x.item())
x.data.sub_(lr * x.grad) # x -= x.grad 数学表达式意义: x = x - x.grad # 0.5 0.2 0.1 0.125
x.grad.zero_()
iter_rec.append(i)
loss_rec.append(y)
plt.subplot(121).plot(iter_rec, loss_rec, '-ro')
plt.xlabel("Iteration")
plt.ylabel("Loss value")
x_t = torch.linspace(-3, 3, 100)
y = func(x_t)
plt.subplot(122).plot(x_t.numpy(), y.numpy(), label="y = 4*x^2")
plt.grid()
y_rec = [func(torch.tensor(i)).item() for i in x_rec]
plt.subplot(122).plot(x_rec, y_rec, '-ro')
plt.legend()
plt.show()
# ------------------------------ multi learning rate
# flag = 0
flag = 1
if flag:
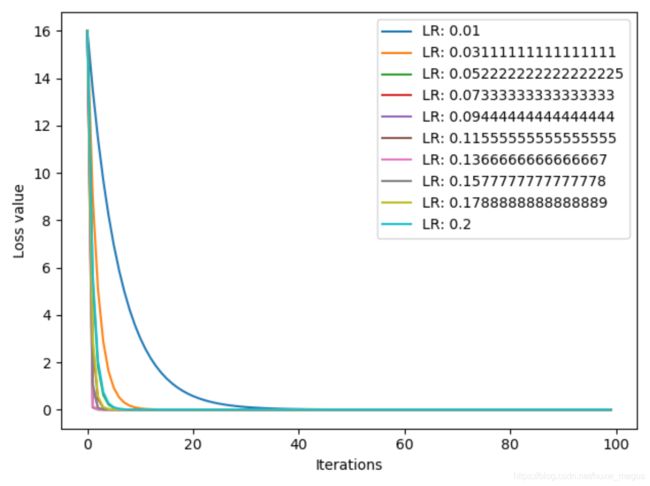
iteration = 100
num_lr = 10
lr_min, lr_max = 0.01, 0.2 # .5 .3 .2
lr_list = np.linspace(lr_min, lr_max, num=num_lr).tolist()
loss_rec = [[] for l in range(len(lr_list))]
iter_rec = list()
for i, lr in enumerate(lr_list):
x = torch.tensor([2.], requires_grad=True)
for iter in range(iteration):
y = func(x)
y.backward()
x.data.sub_(lr * x.grad) # x.data -= x.grad
x.grad.zero_()
loss_rec[i].append(y.item())
for i, loss_r in enumerate(loss_rec):
plt.plot(range(len(loss_r)), loss_r, label="LR: {}".format(lr_list[i]))
plt.legend()
plt.xlabel('Iterations')
plt.ylabel('Loss value')
plt.show()


动量 momentum
Momentum(动量,冲量)
指数加权平均: v =∗− + − ∗
# -*- coding:utf-8 -*-
"""
@brief : 梯度下降的动量 momentum
"""
import torch
import numpy as np
import torch.optim as optim
import matplotlib.pyplot as plt
torch.manual_seed(1)
def exp_w_func(beta, time_list):
return [(1 - beta) * np.power(beta, exp) for exp in time_list]
beta = 0.9
num_point = 100
time_list = np.arange(num_point).tolist()
# ------------------------------ exponential weight
flag = 0
# flag = 1
if flag:
weights = exp_w_func(beta, time_list)
plt.plot(time_list, weights, '-ro', label="Beta: {}\ny = B^t * (1-B)".format(beta))
plt.xlabel("time")
plt.ylabel("weight")
plt.legend()
plt.title("exponentially weighted average")
plt.show()
print(np.sum(weights))
# ------------------------------ multi weights
flag = 0
# flag = 1
if flag:
beta_list = [0.98, 0.95, 0.9, 0.8]
w_list = [exp_w_func(beta, time_list) for beta in beta_list]
for i, w in enumerate(w_list):
plt.plot(time_list, w, label="Beta: {}".format(beta_list[i]))
plt.xlabel("time")
plt.ylabel("weight")
plt.legend()
plt.show()
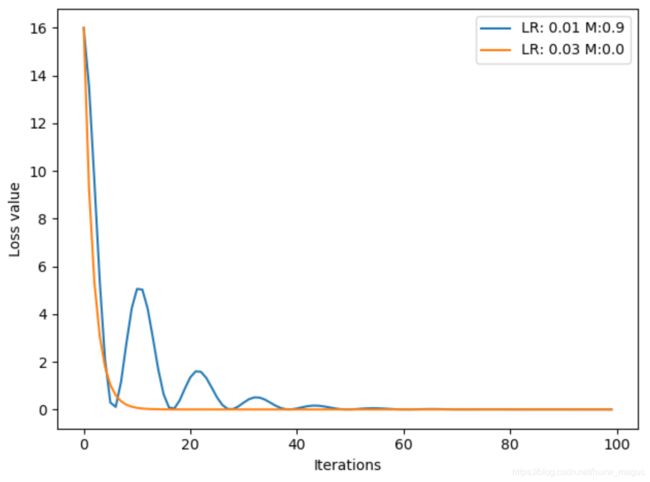
# ------------------------------ SGD momentum
# flag = 0
flag = 1
if flag:
def func(x):
return torch.pow(2*x, 2) # y = (2x)^2 = 4*x^2 dy/dx = 8x
iteration = 100
m = 0.9 # .9 .63
lr_list = [0.01, 0.03]
momentum_list = list()
loss_rec = [[] for l in range(len(lr_list))]
iter_rec = list()
for i, lr in enumerate(lr_list):
x = torch.tensor([2.], requires_grad=True)
momentum = 0. if lr == 0.03 else m
momentum_list.append(momentum)
optimizer = optim.SGD([x], lr=lr, momentum=momentum)
for iter in range(iteration):
y = func(x)
y.backward()
optimizer.step()
optimizer.zero_grad()
loss_rec[i].append(y.item())
for i, loss_r in enumerate(loss_rec):
plt.plot(range(len(loss_r)), loss_r, label="LR: {} M:{}".format(lr_list[i], momentum_list[i]))
plt.legend()
plt.xlabel('Iterations')
plt.ylabel('Loss value')
plt.show()


torch.optim.SGD
- 主要参数:
• params:管理的参数组
• lr:初始学习率
• momentum:动量系数,贝塔
• weight_decay:L2正则化系数
• nesterov:是否采用NAG
pytorch的十种优化器
- optim.SGD:随机梯度下降法
- optim.Adagrad:自适应学习率梯度下降法 3. optim.RMSprop: Adagrad的改进
- optim.Adadelta: Adagrad的改进
- optim.Adam:RMSprop结合Momentum 6. optim.Adamax:Adam增加学习率上限
- optim.SparseAdam:稀疏版的Adam
- optim.ASGD:随机平均梯度下降
- optim.Rprop:弹性反向传播
- optim.LBFGS:BFGS的改进