论文:Feature Pyramid Networks for Object Detection 阅读笔记
一、简介
引用:
http://hellodfan.com/2017/10/14/%E7%89%A9%E4%BD%93%E6%A3%80%E6%B5%8B%E8%AE%BA%E6%96%87-SSD%E5%92%8CFPN/
二、流程
在RPN+FAST R-CNN里边 嵌入FPN的流程图
1、第一种不知是不是存在,与第二种的差别,就是最后的rol不是在不同的层级的feature map上取,而是只在一个层级上取,
2、网上的理解大多是这种
FPN加持的RPN
在Faster RCNN中,RPN用来提供ROI的proposal。backbone网络输出的single feature map上接了3×3大小的卷积核来实现sliding window的功能,后面接两个1×1的卷积分别用来做objectness的分类和bounding box基于anchor box的回归。我们把最后的classifier和regressor部分叫做head。
使用FPN时,我们在金字塔每层的输出feature map上都接上这样的head结构(3×3的卷积 + two sibling 1×1的卷积)。同时,我们不再使用多尺度的anchor box,而是在每个level上分别使用不同大小的anchor box。具体说,对应于特征金字塔的5个level的特征,P2 - P6,anchor box的大小分别是![]() 。不过每层的anchor box仍然要照顾到不同的长宽比例,我们使用了3个不同的比例:1:2,1:1,2:1(和原来一样)。这样,我们一共有5×3=15个anchor box。
。不过每层的anchor box仍然要照顾到不同的长宽比例,我们使用了3个不同的比例:1:2,1:1,2:1(和原来一样)。这样,我们一共有5×3=15个anchor box。
训练过程中,我们需要给anchor boxes赋上对应的正负标签。对于那些与ground truth有最大IoU或者与任意一个ground truth的IoU超过0.7的anchor boxes,是positive label;那些与所有ground truth的IoU都小于0.3的是negtive label。
有一个疑问是head的参数是否要在不同的level上共享。我们试验了共享与不共享两个方法,accuracy是相近的。这也说明不同level之间语义信息是相似的,只是resolution不同。
FPN加持的Fast RCNN
Fast RCNN的原始方法是只在single scale的feature map上做的,要想使用FPN,首先应该解决的问题是前端提供的ROI proposal应该对应到pyramid的哪一个label。由于我们的网络基本都是在ImageNet训练的网络上做transfer learning得到的,我们就以base model在ImageNet上训练时候的输入224×224作为参考,依据当前ROI和它的大小比例,确定该把这个ROI对应到哪个level。如下所示:
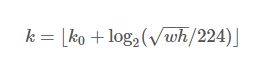
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数。
然后,因为作者把conv5也作为了金字塔结构的一部分,那么从前全连接层的那个作用怎么办呢?这里采取的方法是增加两个1024维的轻量级全连接层,然后再跟上分类器和边框回归。作者认为这样还能使速度更快一些。
这个图稍微有些问题,每个层级融合之后的feature map应该是都连接卷积层 进行分类和回归,作为后面的建议给fast rcnn
三、细节
1. 不同深度的 feature map 为什么可以经过 upsample 后直接相加?
A:作者解释说这个原因在于我们做了 end-to-end 的 training,因为不同层的参数不是固定的,不同层同时给监督做 end-to-end training,所以相加训练出来的东西能够更有效地融合浅层和深层的信息。
2. 为什么 FPN 相比去掉深层特征 upsample(bottom-up pyramid) 对于小物体检测提升明显?(RPN 步骤 AR 从 30.5 到 44.9,Fast RCNN 步骤 AP 从 24.9 到 33.9)
A:作者在 poster 里给出了这个问题的答案

对于小物体,一方面我们需要高分辨率的 feature map 更多关注小区域信息,另一方面,如图中的挎包一样,需要更全局的信息更准确判断挎包的存在及位置。
3. 如果不考虑时间情况下,image pyramid 是否可能会比 feature pyramid 的性能更高?
A:作者觉得经过精细调整训练是可能的,但是 image pyramid 主要的问题在于时间和空间占用太大,而 feature pyramid 可以在几乎不增加额外计算量情况下解决多尺度检测问题。
4、 高层feature上采样,采用最邻近上采样法(用这个方法是图简便),spatial resolution放大2倍。处理后的feature map记为mapup
这样上层的小的feature map就会被放大到和下面的feature map一样大,就能逐个元素想加了。
5、具体怎么使用FPN
作者一方面将FPN放在RPN网络中用于生成proposal, 另一方面将FPN用于Fast R-CNN的检测部分。
6、 此外,由于金字塔上的所有feature共享classifier和regressor,要求它们的channel dimension必须一致。本文固定使用256256。而且这些外的conv layer没有使用非
四、代码实现
这里给出一个基于PyTorch的FPN的第三方实现kuangliu/pytorch-fpn