学习FPN和retinanet的网络结构
多尺度上目标识别是计算机视觉领域的一个基本挑战,解决这一挑战的基本方法就是“基于图像金字塔的特征金字塔(简称为特征图像金字塔)”,这些金字塔具有尺度不变性,可以通过扫描位置和金字塔层来检测大范围上的尺度。将图像金字塔各层提取特征的主要好处就在于产生了一个多尺度特征表示,这个表示的所有层语义很强,包括高精度的层。尽管这样,然而,对每层进行特征提取有很明显的限制,Inference time将急剧上升,在图像金字塔上进行end-to-end的训练内存上也不可行,最多只能在测试的时候将就用一下。Fast and Faster R-CNN也尽量避免采用这种方法。
图像金字塔不是唯一计算多次度特征表示的方法,用卷积计算次采样得到特征阶层具有内在的多尺度性。这种特征阶层生成具有不同空间精度的特征图,但由于卷积深度不同,产生了极大的语义鸿沟。高精度的图有低层次的特征,这就损害了目标识别的表现能力。
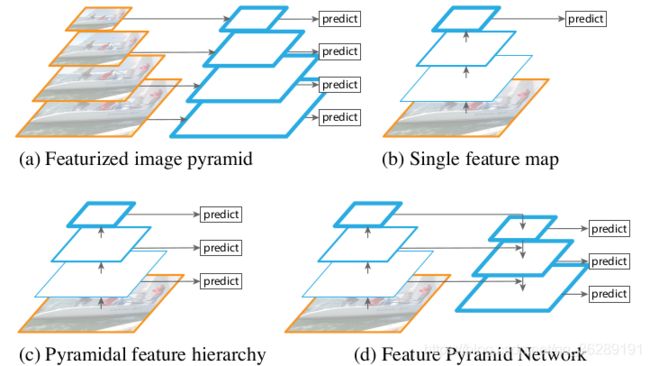
注:特征图蓝色边界越宽,表示是语义越强的特征。
(a).使用图像金字塔构:造特征金字塔,速度很慢
(b).使用单一尺度特征更快地检测,如Fast and Faster R-CNN
(c).用卷积计算得到金字塔特征阶层,如SSD,SSD为了避免使用低层的特征,从conv4 3 of VGG开始,这导致其不能使用特征阶层的高精度图,不能检测小物体。
(d). FPN网络
下面具体介绍FPN
目标:卷积得到的特征金字塔具有从低到高的语义,并在整个过程中构建具有高级语义的特征金字塔
输入:单尺度,随意大小的图像
输出:多层次上与特征图大小成比例的输出
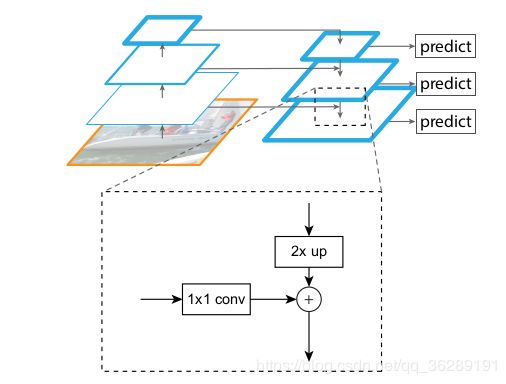
自底向上:主卷积层(RES-NET)的前馈计算,其计算尺度步长为2。值得注意的是RES-NET中,每一个stage包括多层卷积,这里每一个level取得是每个stage最后一层卷积的输出,这个level正好在下个stage之前。
自顶向下:从更高金字塔层上采样(如最近领域上采样)空间更粗糙、语义更强的特征图来得到更高精度的特征。这些特征通过横向连接用自底向上通路上的特征进行加强。
整个过程:在C5上添加一个1×1卷积层来生成最粗糙分辨率映射,上采样为2倍,由于P5之上没有其他层,P5直接从C5映射过来;P4先通过P5上采样,在与C5映射过来的特征进行融合;之后每层都如此,最后对所有融合之后得到的层采用3*3的卷积核,步长为1的卷积对每个融合结果进行卷积,消除上采样的混叠效应。于是对应下图的C2,C3,C4,C5我们得到与其具有相同空间尺寸的P2,P3,P4,P5。

retinanet的主网络部分采用的是FPN结构,两个不同任务的子网络,一个是分类网络,一个是位置回归网络。

retinanet的主网络部分结构并不与FPN中提到的结构完全一致,retinanet使用特征金字塔层P3,P4,P5,P6,P7,其中,P3,P4,P5与FPN中的产生方式一样,通过上采样和横向连接从C3,C4,C5中产生,P6是在C5的基础上通过3x3的卷积核,步长为2的卷积得到的,P7在P6的基础上加了个RELU再通过3x3的卷积核,步长为2的卷积得到的。这部分的kreas代码如下:
def __create_pyramid_features(C3, C4, C5, feature_size=256):
""" Creates the FPN layers on top of the backbone features.
Args
C3 : Feature stage C3 from the backbone.
C4 : Feature stage C4 from the backbone.
C5 : Feature stage C5 from the backbone.
feature_size : The feature size to use for the resulting feature levels.
Returns
A list of feature levels [P3, P4, P5, P6, P7].
"""
# upsample C5 to get P5 from the FPN paper
P5 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C5_reduced')(C5)
P5_upsampled = layers.UpsampleLike(name='P5_upsampled')([P5, C4])
P5 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P5')(P5)
# add P5 elementwise to C4
P4 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C4_reduced')(C4)
P4 = keras.layers.Add(name='P4_merged')([P5_upsampled, P4])
P4_upsampled = layers.UpsampleLike(name='P4_upsampled')([P4, C3])
P4 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P4')(P4)
# add P4 elementwise to C3
P3 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C3_reduced')(C3)
P3 = keras.layers.Add(name='P3_merged')([P4_upsampled, P3])
P3 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P3')(P3)
# "P6 is obtained via a 3x3 stride-2 conv on C5"
P6 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=2, padding='same', name='P6')(C5)
# "P7 is computed by applying ReLU followed by a 3x3 stride-2 conv on P6"
P7 = keras.layers.Activation('relu', name='C6_relu')(P6)
P7 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=2, padding='same', name='P7')(P7)
return [P3, P4, P5, P6, P7]在P3-P7层上选用的anchors拥有的像素区域大小从32x32到512x512,每层之间的长度是两倍的关系。每个金字塔层有三种长宽比例【1:2 ,1:1 ,2:1],有三种尺寸大小【2^0, 2^(1/3), 2^(2/3)】。总共便是每层9个anchors。大小从32像素到813像素。
其中 32=(32x2^0) 813=(512x2^(2/3))
分类子网络和回归子网络的参数是分开的,但结构却相似。都是用小型FCN网络,将金字塔层作为输入,接着连接4个3x3的卷积层,fliter为金字塔层的通道数(论文中是256),每个卷积层后都有RELU激活函数,这之后连接的是fliter为KA(K是目标种类数,A是每层的anchors数,论文中是9)的3x3的卷积层,激活函数是sigmoid。
另外提一下retinanet的主要亮点是损失函数
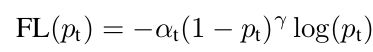
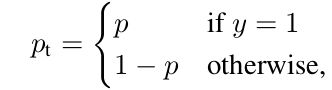
在传统的交叉熵函数前面加上了权重,这样便使得量大类别(主要是backgroud)的权重急剧减小,提高量少类别的权重,解决类别分类不平衡的问题。