《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》
目录
- 《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》
- 1、Bert研究意义
- 2、摘要
- 3、Bert衍生模型以及Elmo、GPT、Bert对比
- 3.1 RoBERTa
- 3.2 ALBERT
- 3.3 其它
- 3.4 ELMO、GPT、BERT比较
- 4、Model Architecture
- 5、Pre-training BERT
- 5.1 BERT、GPT、ELMP比较图
- 5.2 MLM —— Mask Language Model
- 6、Fine-tuning BERT
- 6.1 问答任务(阅读理解)详解
- 7、模型蒸馏
《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》
- 预训练的深度双向trandformer用于语义理解;
- 作者:Jacob Devlin;
- 单位:Google;
- 发表会议及时间:2018;
1、Bert研究意义
- 获得了left-to-right和right-to-left的上下文信息;
- nlp领域正式开始pretraining+fine-tuning的模型训练方式;
2、摘要
- 论文提粗了一种新的语言表征模型bert,不同于其他的语言表征模型吧,bert可以同时学习向左和向右的上下文信息;
- 预训练的bert可以直接fine-tuning,只需要加相应的输出层,无需太多模型结构的改动;
- bert模型在各项nlp下游任务中都表现得良好;
3、Bert衍生模型以及Elmo、GPT、Bert对比
3.1 RoBERTa
RoBERTa在原有BERT的基础上用了更多的数据,模型更大,参数更多,把BERT的静态mask变为动态mask。静态mask就是指在每一个epoch中mask的位置是一样的,动态mask中每一个epoch中mask的位置是不同的,使用动态mask可以式模型获得更多的随机信息;
3.2 ALBERT
ALBERT属于轻量级的BERT,BERT是一种参数量比较大的模型,为了能减少模型的参数,有两种方法,一种方法是蒸馏方法,还有一种方法是调整模型结果,这也是ALBERT使用的方法。
ALBERT使用跨层的参数共享,在原始BERT中transformer中不同layer层之间的参数是不共享的,这样导致模型的参数量非常大,在ALBERT中进行跨层的参数共享,使参数量减少,论文指出,改论文使用的参数共享方法,不仅模型性能没有降低,反而模型结果优于BERT的结果;
3.3 其它
BERT-WWM、ERINE、SpanBERT、TinyBERT、Sentence-BERT、k-Bert等;
3.4 ELMO、GPT、BERT比较
| 模型 | 模型采用结构 | 预训练形式 | 优点 | 缺点 | 在Glue上表现 |
|---|---|---|---|---|---|
| ELMO | Bilstm+LM | feature-based | 动态的词向量表征 | 双向只是单纯的concat两个lstm,并没有真正的双向 | 最差 |
| GPT | Transformer Decoder部分(含有sequence mask,去掉中间的Encoder-Decoder的attention) | fine-tuning | 在文本生成任务上表现出色,同时采用辅助目标函数和LM(language model)模型 | 单向的transformer结构,无法利用全局上下文信息 | 较差 |
| BERT | Transformer Encoder部分 | fine-tuning | 在各项下游任务中表现出色,采用MLM(masked language model)的实现形式完成真正意义上的双向,增加了句子级别预测的任务 | 在文本生成任务上表现不好 | 最好 |
4、Model Architecture

以上图大致描述了BERT的结构,假定模型的输入为 [ w 1 , w 2 , w 3 , w 4 , w 5 ] [w_1,w_2,w_3,w_4,w_5] [w1,w2,w3,w4,w5],输入的词为one-hot形式向量,图中的Embedding层包含三部分,其形式如下所示:

BERT的输入由两个句子组成时,在第一个句子的开头添加[CLS],在两个句子间和第二个句子结尾分别添加[SEP],通过添加分隔符分割两个句子;
因为输入是两个句子,因此需要一种标志提示哪一部分属于句子A,哪一部分属于句子B,因此引入了Segment Embeddings,以此区分句子A和句子B。当使用BERT进行文本分类时,BERT模型的输入为一个句子,这样在Segment Embeddings中只有一种信息,不用区分句子A和句子B;
因为BERT模型没办法提取到词与词之间的位置信息,因此BERT引入了位置信息嵌入矩阵Position Embeddings,用于添加词的位置信息;
输入的单词经过Embedding之后输入到Transformer的Encoder部分,论文中提供的预训练模型有两个版本,一个是 B E R T B A S E BERT_{BASE} BERTBASE,一个是 B E R T L A R G E BERT_{LARGE} BERTLARGE: B E R T B A S E ( L = 12 , H = 768 , A = 12 , T o t a l P a r a m e t e r s = 110 M ) BERT_{BASE}(L=12,H=768,A=12,TotalParameters=110M) BERTBASE(L=12,H=768,A=12,TotalParameters=110M) B E R T L A R G E ( L = 24 , H = 1024 , A = 16 , T o t a l P a r a m e t e r s = 340 M ) BERT_{LARGE}(L=24,H=1024,A=16,TotalParameters=340M) BERTLARGE(L=24,H=1024,A=16,TotalParameters=340M)
上述表述中L表示Transformer的层数,H表示hidden size,A表示head的数量;
经过Encoder层之后接一个全连接层,使用GELU激活函数和Norm数据处理,其输出对mask的词进行预测,整个过程就是模型预训练的一个过程;
5、Pre-training BERT
5.1 BERT、GPT、ELMP比较图

5.2 MLM —— Mask Language Model
为了使模型学习到句子left-to-right和right-to-left的全局信息,BERT采用了两种策略:
策略1:Mask LM。随机mask一个酒醉中15%的词,用其上下文做预测: m y d o g i s h a i r y − > m y d o g i s [ m a s k ] my\space dog\space is \space hairy -> my\space dog\space is \space [mask] my dog is hairy−>my dog is [mask]
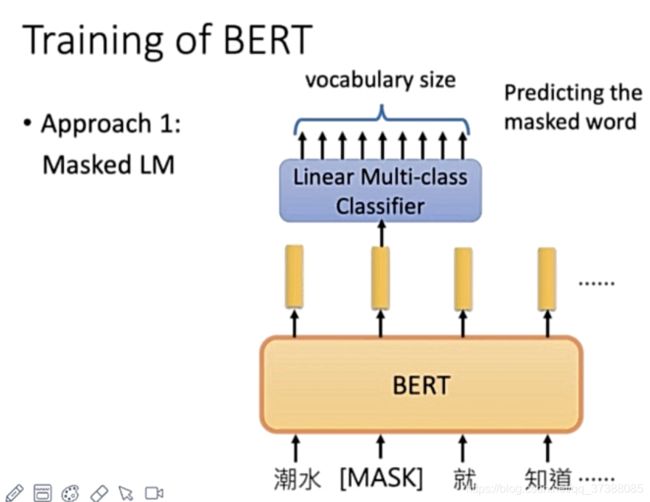
为了保证预训练和微调时的一致性,采用以下措施:
- 80%的机会采用mask: m y d o g i s h a i r y − > m y d o g i s [ m a s k ] my\space dog\space is \space hairy -> my\space dog\space is \space [mask] my dog is hairy−>my dog is [mask]
- 10%的机会随机选取一个词代替mask: m y d o g i s h a i r y − > m y d o g i s a p p l e my\space dog\space is \space hairy -> my\space dog\space is \space apple my dog is hairy−>my dog is apple
- 10%的机会保持原始词不变: m y d o g i s h a i r y − > m y d o g i s h a i r y my\space dog\space is \space hairy -> my\space dog\space is \space hairy my dog is hairy−>my dog is hairy
上面的图片简单描述了BERT的MLM预训练过程,这个过程与word2vec的连续词袋模型大致一样,但是word2vec中通过背景窗口大小的上下文预测其中心词,而Bert的MLM模型是通过上下文句子预测mask的词。
策略2:Next Sentence Prediction
选择一些句子对A和B,其中50%的数据中B是A的下一个句子,50%的数据中B是从语料库中随机获取的,并不是A的下一个句子;这样做是针对句子间的任务,例如SNLI;
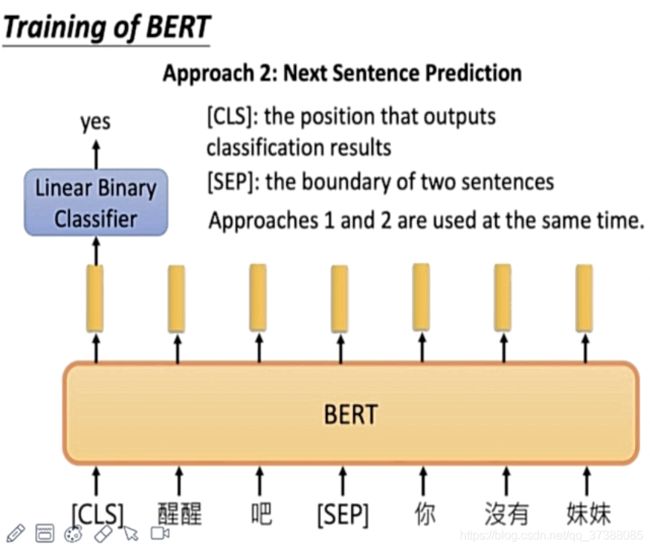
在预训练BERT的时候,模型同时使用两种策略进行训练。
6、Fine-tuning BERT

在句子分类任务中,就是在句子开始的[CLS]对应的token输出端接一个相应的线性层,BERT结构的参数时fine-tuning,但是线性层的参数时从头到尾训练的;
NER任务中每个token后面都会有对应的输出;
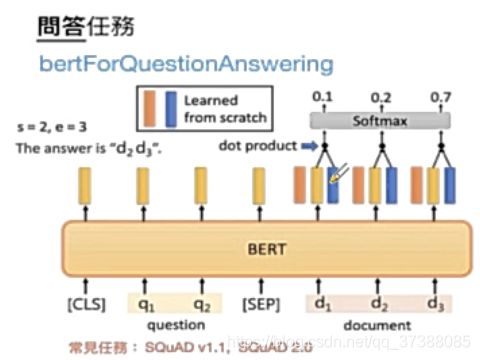
如上图所示,给定问题输入 Q = { q 1 , . . . , q n } Q=\{q_1,...,q_n\} Q={q1,...,qn},给定查询文档输入 D = { d 1 , . . . , d m } D=\{d_1,...,d_m\} D={d1,...,dm},D部分的输出为上图对应的黄色部分,为了寻找Answer的起始位置s和结束位置e,需要在Encoder的输出端添加一个橙色部分的向量和蓝色部分的向量,橙色部分的向量维度和Encoder的输出维度一样,使用黄色部分向量和橙色部分向量进行点积(dot product)再拼接一个softmax寻找Answer的起始位置s,同时,使用蓝色部分向量和黄色部分向量进行点乘再拼接一个softmax寻找Answer的结束位置e,这样就找到了Answer的范围[d_s,…,d_e]。
6.1 问答任务(阅读理解)详解
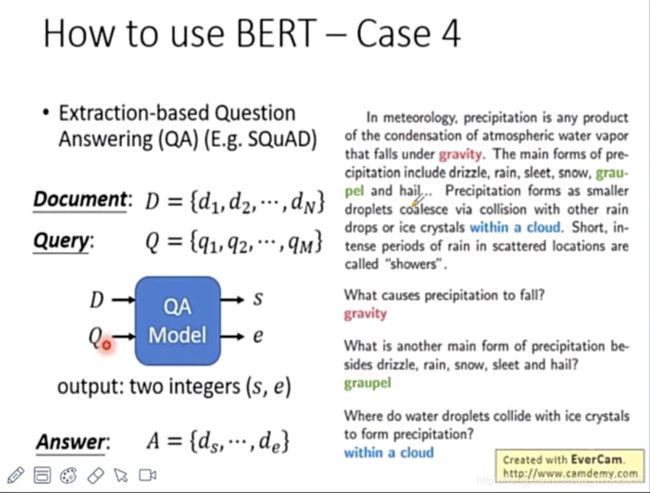
如上图所示,给定Document和Query,Document是模型进行阅读的,给定D和Q,模型会给出Answer在D中的起始位置s和结束位置e,得到最后的Answer: A = { d s , . . . , d e } A=\{d_{s},...,d_{e}\} A={ds,...,de};
7、模型蒸馏
- 首先训练一个大的模型,这个大模型也称为teacher模型;
- 利用teacher模型输出的概率分布训练小模型,小模型称为student模型;
- 训练student模型时,包含两种label,soft label对应了teacher模型输出的概率分布,而hard label是原来的one-hot label;
- 模型蒸馏训练的小模型会学习到大模型的表现以及泛化能力: K L ( p ∥ q ) = E p ( log ( p / q ) ) = ∑ i p i log ( p i ) − ∑ i p i log ( q i ) K L(p \| q)=E_{p}(\log (p / q))=\sum_{i} p_{i} \log \left(p_{i}\right)-\sum_{i} p_{i} \log \left(q_{i}\right) KL(p∥q)=Ep(log(p/q))=i∑pilog(pi)−i∑pilog(qi)公式中的i表示当前的token,p代表teacher模型的分布,q代表student模型的分布,采用KL散度作为损失函数;