SiamFC:Fully-Convolutional Siamese Networks for Object Tracking
作者在本文中提出了一种新的基于全卷积Siamese网络的跟踪算法,并在ILSVRC15数据集上进行了端到端的训练,实时性非常好。

全卷积Siamese神经网络结构如上图所示。Z表示模板图片,x表示待搜索的图片。
作者提出用一个函数f(z,x) 来比较一个模板图片z和x中相同尺寸的候选区域,如果两个图片描述了相同的物体就得到一个很高的分数,反之得到一个很低的分数。为了得到一张新图片中物体的位置,可以尽可能的划分出可能的候选区域,选择与之前相似度最大的候选区域。
一、Fully-convolutional Siamese architecture
Siamese networks用φ![]() 来对两个输入z和x进行处理,然后用fz,x=g(φz,φx)
来对两个输入z和x进行处理,然后用fz,x=g(φz,φx)![]() 来对处理结果进行计算。
来对处理结果进行计算。
下面给出一个全卷积的函数的定义,为了给出这个定义,引入Lτ![]() 来表示一个平移操作
来表示一个平移操作![]() ,如何h函数满足下面的(1)的公式,那么就说h函数就是全卷积的。
,如何h函数满足下面的(1)的公式,那么就说h函数就是全卷积的。
![]()
全卷积网络的有点在于可以提供一个更大的搜索图片放入网络中,它将一相同的评价标准计算密集网格上所有已生成子窗口的相似性。用互相关层来合并φ 提取的两个特征,如公式(2)所示。这个网络的输出不是一个单一的分数,而是一个分数矩阵,如上面的图所示。

在追踪中,我们使用以目标的前一位置为中心的搜索图像,相对于分数图的中心的最大分数的位置,通过网络的扩大,使每一帧的目标被取代。通过组合少量缩放图像,可以在一个前向通道中搜索多个缩放图像。在比较大的搜索图像上,用互相关合并特征图以及一次性评价网络是和用内积运算合并特征图以及独立的在每个转化的子窗口评价网络是等价的。但是互相关提供了一个可靠地简单的方法来在现有的convnet库框架内有效地实现该操作。
二、Training with large search images
逻辑损失函数:
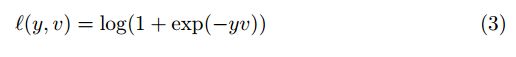
其中,v表示样本–搜索图像的实际得分,y是标签。上式表示的正样本的概率为 ![]()
(sigmoid函数),负样本的概率为![]() ,则按交叉熵的公式很容易得到式 (3) 的loss。
,则按交叉熵的公式很容易得到式 (3) 的loss。
在训练过程中,训练时采用所有候选位置的平均loss来表示,公式如(4)所示:

y[u]ϵ{+1,-1} 表示对于每一个位置u ϵ D 的实际标签,v[u]表示D中u的值,D就是SiamFC输出的最后的分数图。
如何得到神经网络参数:
通过SGD方法优下面的问题可以得到卷积参数θ![]() 。
。

如何得到训练数据:
训练图片对是在带注释的视频数据集合中通过提取以目标为中心的模板和搜索这些图片得到的,如下图所示。步骤如下:
1.搜索区域x 以目标区域z为中心
2.如果超出图像则用像素平均值填充,保持目标宽高比不变
3.训练时不考虑目标类别
4.网络的输入尺寸统一

如何得到网络输出的标签:
分数图D中的元素u如果和目标中心的距离≤ 半径R,就标记为正标签,反之标记为负标签,公式如下。k 为网络的总步长,c为目标的中心,u为score map的一个位置,R为定义的半径。

如何定位目标区域(画框):
在训练完后,通过获取图像得到相似性矩阵,然后直接利用双三次插值将D,即17*17的矩阵变为255*255的矩阵,从而定位目标区域。双三次插值的原理如下:
对于每个待求像素点x,其像素值可由其相邻左右各两个像素加权求得:

三、Practical considerations
Dataset curation:
在训练的过程中,模板图片的尺寸是127*127的,待搜索图片的尺寸是255*255的。图片是缩放的,这样框的外面就会额外增加区域。具体来说,如果一个框的尺寸是w*h的,并且额外增加的margin是p,那么s作为尺寸变换函数会将框变成127*127大小的图片,公式如下所示。
![]()
作者使用处理后得到的A作为模板图片,![]() ,视频的每一帧对应的模板图片和待搜索图片都是离线处理得到的,这样就避免了在训练过程中的裁剪。在这个实验中,作者用了ImageNet Video中的所有4417个的视频,超过2,000,000个标注的跟踪框作为训练集。
,视频的每一帧对应的模板图片和待搜索图片都是离线处理得到的,这样就避免了在训练过程中的裁剪。在这个实验中,作者用了ImageNet Video中的所有4417个的视频,超过2,000,000个标注的跟踪框作为训练集。
Network architecture:
网络结构如下图所示:

四、Experiments
Dataset size:

VOT 2015:


五、总结
这篇文章用了全卷积的孪生网络,通过处理后模板图片在处理后待检测图片上做卷积,得到两者的相似程度,得到目标的位置,再反推回去可以得到原图中的框,但是这种方法没有充分利用原图中框定点坐标信息,得到的框不准确,之后有人提出了SiamRPN的方法,直接在最后输出分数矩阵还有回归框信息的矩阵,类似于Rcnn的思想,直接得到最后的框的坐标信息。