小白科研笔记:深入理解mmDetection框架——训练推断流程
1. 前言
这篇博客讨论mmDetection框架的训练推断的总体流程。在讲解它的训练流程的过程中,我会以3d目标检测算法SA-SSD为讲解对象。首先解析训练流程,然后去讨论推断流程。
2. 训练
训练过程中的程序调用图如下所示。配置文件的重要性不言而喻,学习mmDetection框架的第一步就是立理解配置文件。这里假设读者都已了解。配置文件主要提供五个方面的参数。
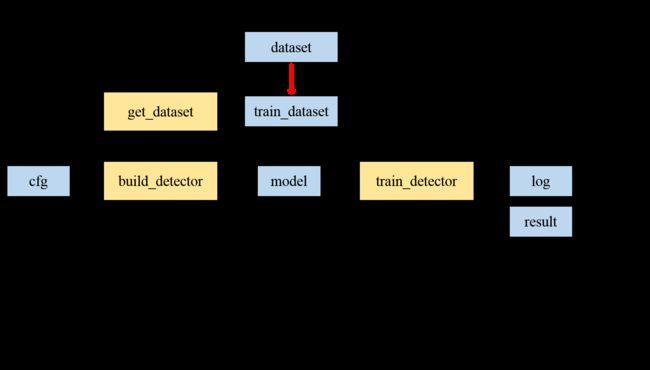
图1:总体训练流程图
build_detector属于网路框架搭建模块的函数,get_dataset属于数据模块的函数,在这篇博客不去做介绍(留到后面讲)。接下来重点分析train_detector。它的图解如下所示。
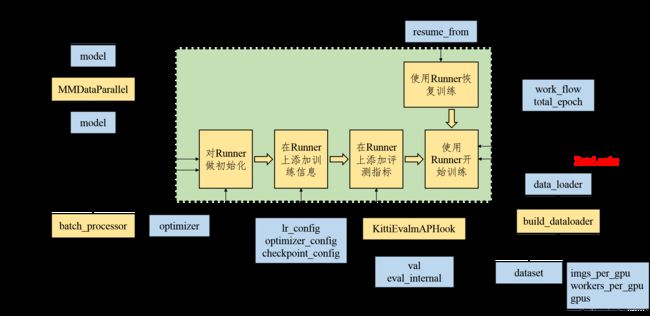
图2:train_detector流程图解
mmDetection的训练主要是调用mmcv的框架训练小助手Runner。Runner可根据配置文件,自动地完成目标检测网络的训练。当然,它的底层还是调用Pytorch的函数,比如数据的加载会调用Pytorch的DataLoader,反向传播依然是Pytorch的backward()。Runner考虑了多个GPU的训练细节。
Runner的代码写的同样很有意思。代码中使用hook的技术,可以参考这篇知乎笔记(笔记中的hook跟Runner源码中使用到的hook似乎意义不太一样)。在我的理解,hook是插件。核心训练代码如下所示:
while self.epoch < max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
# 根据 workflow 内容,决定此 Epoch 是训练网络还是评估网络
if isinstance(mode, str): # self.train()
if not hasattr(self, mode):
raise ValueError(
'runner has no method named "{}" to run an epoch'.
format(mode))
# 使用 getattr 传递函数句柄
# epoch_runner = self.train() 或者 self.val()
epoch_runner = getattr(self, mode)
elif callable(mode): # custom train()
epoch_runner = mode
else:
raise TypeError('mode in workflow must be a str or '
'callable function, not {}'.format(
type(mode)))
# 执行 workflow
for _ in range(epochs):
if mode == 'train' and self.epoch >= max_epochs:
return
epoch_runner(data_loaders[i], **kwargs)
再简单看一下Runner中self.train()的核心代码:
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(data_loader)
self.call_hook('before_train_epoch')
# 通过 data_loader 喂数据
for i, data_batch in enumerate(data_loader):
self._inner_iter = i
self.call_hook('before_train_iter')
# 输出训练误差
outputs = self.batch_processor(
self.model, data_batch, train_mode=True, **kwargs)
if not isinstance(outputs, dict):
raise TypeError('batch_processor() must return a dict')
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'],
outputs['num_samples'])
self.outputs = outputs
self.call_hook('after_train_iter')
self._iter += 1
self.call_hook('after_train_epoch')
self._epoch += 1
Runner的更多细节代码不做叙述,但是相信读者在看过图2后,会对Runner的初始化,设置,训练测评等流程有一个宏观了解。
3. 推断
推断过程中的程序调用图如下所示。single_test是网络推断的代码,靠data_loader喂数据,data_loader的设定可以追溯到get_dataset和配置文件上。检测网络在完成推断之后需要计算指标,调用get_official_eval_result。该函数的分析放在指标计算的专题做讲解。
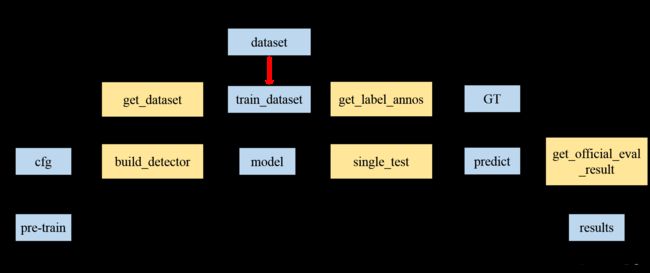
图3:总体推断流程图
4. 结束语
这篇博客简要讨论了mmDetection框架的训练推断流程。