Digging Into Self-Supervised Monocular Depth Estimation(2019.8)
深入研究基于自监督的单目深度估计
贡献:
(1)一个最小投影损失来解决遮挡问题。
(2)全分辨率的多尺度采样方法,减少视觉混乱
(3)设计一个 auto-masking loss 来忽略相机运动假设
一、介绍
作为监督学习的替代选择,自监督方法被证明能够仅使用合成的立体图像对或单目视频对单目深度估计模型进行训练。
在两种自监督方法中,单目视频比基于立体图像的监督方法更有效,但是其自身存在一些问题。除了对深度进行估计,还需要在训练中估计当前时刻图像对之间的自运动。因此,通常利用有限个序列作为输入训练一个pose estimation 网络,并输出一个相对相机变换。相反,使用立体数据进行训练,使相机位姿估计只能进行一次离线矫正,但是会因为遮挡和纹理重叠造成困难。
我们将提出的三个结构和新的损失函数相结合,并对单目视频、立体图像对、以及共同结合进行训练:
(1)新的 appearance matching loss 解决了使用单目监督时,由遮挡像素造成的问题。
(2)简单有效的 auto-masking 忽略了单目训练中没有找到相对相机运动的像素。
(3) 多尺度 appearance matching loss 以输入分辨率对所有图像进行采样,减少了深度混乱。
二、相关工作
2.1. 监督深度估计
由于同样的输入图像能够投影出多个深度,因此从单张图片估计深度本身就存在问题。 由于监督学习在训练中的真实数据很难获得,因此大部分开始向弱监督训练数据探索,比如:已知物体的大小形状[66]、稀疏的基本深度[77, 6]、受监督的appearance-matching部分[72, 73]、或者不成对的合成深度数据[45][2][16][78],这些都需要额外的深度或者标注。合成的数据是替代品,但是,生成的大量包含变化的真实世界的场景和运动的合成数据是不容易的。 最近提出的structure-from-motion (SfM)能够生成对相机位姿和深度的稀疏监督信号[35, 28, 68],SFM主要作为前处理功能对学习进行解耦。 最近【65】通过结合从传统立体方法得到噪声的深度信息在我们的模型上,提高了深度估计效果。
2.2 自监督深度估计
模型的输入为立体对或者单目序列,通过用给定的图像向周围图像进行投影,最小化图像重投影误差来进行训练。
(1)自监督立体训练
自监督的一种方法来自于立体对,这里,在训练中提供了同步的立体对,通过预测两者间的像素视差,能够在测试时估计出深度。[67] 针对新的图像合成问题,提出了这样带有离散深度的模型。[12]通过预测连续深度值扩展了之前的方法,[15](Godard)加入left-right depth consistency项后比如今的监督方法效果还要好。
基于立体对的方法,经过发展产生了:1)半监督数据[30, 39],2)generative adversarial networks(GAN 生成对抗网络)[1, 48]、3)添加一致性[50]、4)临时信息[33, 73, 3]、5)对于实时应用使用e[49]
(2)自监督单目训练
自监督的一个低约束部分在于使用的是单目视频,其中连续的实时图像作为训练信号,这里,网络需要对图像之间深度和相机位姿进行估计,由于存在运动物体会有一定难度。其中,估计的位姿只在训练中被需要帮助约束深度估计网络。
在第一批自监督方法中,[76] 使用单独的位姿网络训练深度估计网络。为了解决固定场景运动,需要一个额外的运动解释掩膜(motion explanation mask)来消除违背固定场景假设的区域,然而,后来的迭代能够在线解决这一部分。[71] 将运动为分解为,动态与静态,使用深度和光流来解释物体运动,提高了光流估计,但是将光流深度一起训练时没有进步。[22]在光流孤寂中展现了其模型对遮挡区的有效性。
最近的方法,将单目与基于立体的方法效果差距缩小,其中:
[70] 用估计的深度与估计的平面法向量进行约束
[69] 促进边缘一致性。
[40] 提出了一个基于匹配误差的大致几何模型促进实时的深度一致性。
[62]使用深度归一化层克服由常用的[15]中的深度平滑部分得到的小深度值引起的变化
[5]利用提前计算出的已知种类的实例分割mask解决移动物体。
(3)基于损失的变化
自监督训练主要依赖于明显特征(亮度恒定)以及图像间的物体表面属性(Lambertian)。
[15] 包含了一个基于appearance loss 的局部结构
[64] 与简单的成对像素差[67, 12, 76] 相比具有更好的深度估计
[28] 加入一个误差自适应部分扩展了这个方法
[43] 加入了一个基于损失的对抗网络促进了类似于真实环境的合成图像,
[73] 在 [72] 的启发下,使用ground truth 深度训练一个表面匹配部分。
三、方法
这里,使用单张彩色图输入It, 生成一张深度图Dt
3.1 自监督训练
自监督深度估计方法可以看作是一个新的图像合成(view-synthesis)。通过从另一张图像的视角对目标图像进行估计。通过使用一个中间变量来约束网络,这里是深度或视差。 有一个本身存在的问题就是,对于每个像素由很多种可能的深度,因此需要两帧间的相对位姿来正确进行重建。 传统的双目和单目立体方法,通过促进深度图的平滑度解决其不确定性(ambiguity)。然后,在全局优化中,通过在patches中计算 photo-consistency 处理每个像素的深度[11]。
与[12, 15, 76]像素,在训练时我们将问题定义为了最小化重投影误差,我们对原始图像It' 和与之相对的目标图像It 之间的位姿设为Tt→t‘. 用预测出的稠密深度图最小化重投影误差Lp:
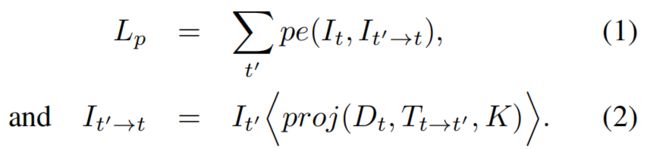
其中,pe 是图像重投影误差,如:在像素空间的L1距离; proj()为向It'投影的深度图Dt 的二维坐标结果;<>为采样操作。为了进行简化,我们假设提前计算好了内参K。 与[21]一样,我们对源图采用了双线性采样,这样局部可微,然后按照[75][15],使用L1和SSIM[64] 计算函数pe。
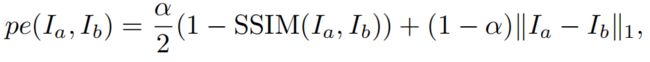
其中a = 0.85,按照[15]我们使用边缘已知平滑度
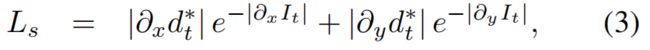
d∗t = dt/dt 是来自[62] 的平均归一化的逆深度,来防止深度消失
1)在双目训练中,It' 是立体对It图像的第二张图像,并已知其相对位姿。但单目序列中不知道相对位姿,[76] 可以利用重投影函数proj 训练一个位姿估计网络估计相对位姿Tt→t‘。在训练中,同时解决了相机的位姿和深度来最小化Lp,
2)对于单目训练,使用与It 相邻的两帧图像作为源图(It'∈ {It-1, It+1})
3)在混合训练(MS)中,It'包含了相邻帧图像和立体图像对。
3.2 改进的自监督深度估计
(1) 最小化每像素的重投影损失
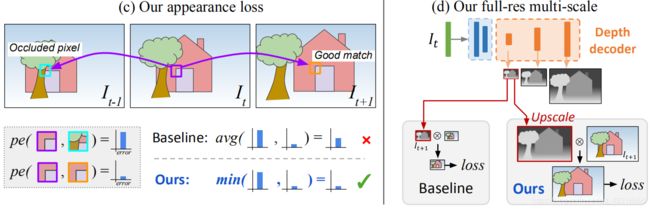
当计算多图的repro error时,现有的方法将所有的重投影误差平均到每一个可能的原图中,这将在目标图像出现但在其他图像消失的像素引起问题(图3(C))。
如果网络正确估计出一个像素的深度值,那么相对遮挡的原图可能会匹配不到从而造成高的图像损失惩罚。 以上问题像素主要来自于两方面:1)在图像边缘由于自运动而出视野(out-of-view)的像素 2)受到遮挡的像素
移出图像的像素能够在重投影误差被标注(masking)出从而减少[40][61], 但是不能解决遮挡问题,而平均投影将会造成模糊的深度不连续情况。
我们提出对于每个像素,不是对所有原图进行平均图像误差,我们仅仅选择了最小化,最终误差如下:
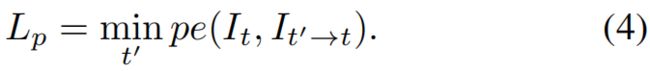

如图4所示,使用我们的重投影损失能够很大减少图像边缘的无处理,改善了遮挡边缘的陡度。
(2)Auto-Masking Stationary Pixels
自监督的弹幕训练总是在固定背景和一个运动相机的假设下进行的。当这些假设不成立时,比如:当相机是固定的但是场景中有移动物体,效果将会大大影响。这个问题可能会造成测试的深度图出现无限深度的孔,对于在训练中观察到物体移动是很常见的。由此我们做出了两点贡献:
1)一个简单的auto-masking方法,过滤出在连续帧中没有变化的像素点。这对于与相机保持同速运行、甚至当相机停止移动时刻意忽略视频中所有的图像都有效。
2) 像[76, 61, 38] 我们向loss中加入了一个per-pixel mask ,不同于之前的方法,我们的mask是二进制的,µ ∈ {0, 1},,并且
在前向传播中能够自动计算,而不是从物体运动中学习或是估计。
我们发现:连续帧中保持不变的像素可能是:
1.相机是静止的
2.与相机进行同样相对变化的运动物体
3. 处在一个一个低纹理区。
因此,我们设置µ 只包含那些It '→t 与 It 之间重投影误差低于原始图像与转换图像的像素,加入到损失。
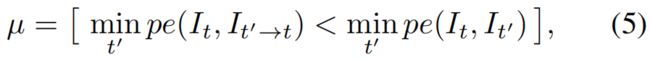
这里,[ ] 是 Iverson 括号,当相机与另一个移动物体处于相同移动速度时,µ 代表的是在图像中保持静止的像素,防止影响误差。同样,当相机静止时,mask 可以过滤掉所有图像的像素(图5)

(3)多尺度估计
由于双线性采样器的梯度局限,以及防止训练目标被困在局部最小化。现有的网络使用多尺度深度估计和图像重建。这里总损失是由解码器在不同尺度的损失结合在一起。[12, 15] 在每个decoder层的分辨率下进行图像损失计算,我们发现这会更容易在低分辨率深度图中间的低纹理区出现‘holes’,还人为的纹理重复(从彩色图错误转化过来的深度图中的细节)。在深度图中'Holes'会发生在低分辨率的低纹理区,并且图像损失不明确。
在立体重建[56] 启发下,选用了多尺度结构,对视差图和彩色图扩大两倍后计算重投影误差。 没有在模糊的低纹理区计算损失,首先对低分辨率深度图(来自中间层)上采样到输入分辨率大小,然后进行重投影,重新采样,然后在高分辨率下计算pe损失( 图3(d) )。这个过程和匹配patches相似,由于低分辨率视差值依赖于在高分辨率下对像素的所有'patch'进行变换。这有效的约束了深度图在每个尺度都达到效果。如:尽可能精确的重建高分辨率的输入目标图像
(4)最终训练损失
将每个像素的平滑度损失和经过mask的图像损失结合在一起,利用每一个像素、尺度和batch。
L = µ Lp + λ Ls
3.3 额外的考虑
深度估计模型基于普遍的 U-Net 结构[53],比如:encoder-decoder网络,带有跳跃连接,能够使我们表达出深度提取的特征以及局部信息。 我们使用ResNet18 [17] 作为encoder,包含了11M个参数,之前方法使用的DispNet和ResNet50模型则体积大、网络慢。与[30, 16] 相比,我们使用提前在ImageNet [54],训练好的权重,并且在小模型下提高了准确率。我们的深度decoder在所有输出上使用了sigmoid函数,并在其他地方使用了ELU非线性正则化。
深度decoder与[15]相似,通过将sigmoid的输出σ 使用D = 1/(aσ + b)转为了深度,其中a和b用了将D约束在0.1-100单元内。另外,使用了reflflection padding代替了0 padding,在解码器中,当样本在图像边缘外时,返回原图中最近边缘的像素值。这样减少了很多边缘问题。
对于位姿估计,按照[62]并使用axis-angle的方法表示预测的旋转,并对旋转和偏移输出进行0.01的尺度变化。对于单目训练,使用一个三帧长度的序列,pose网络由ResNet18组成,经过改变将一对色彩图(或者6通道)作为输入,并估计出一个6-DoF的相对位姿。
此外进行了数据加强和水平翻转,对50%数据进行改变:随机亮度、对比、饱和度和色调,分别进行±0.2, ±0.2, ±0.2, 和±0.1的调整。重要的是,色彩增强至被应用于喂入网络的蚃,而不是被用作计算Lp,所有被喂入位姿和深度的网络的三张图像都被同样的参数增强。
本模型,使用Adam训练20周期, batch_size 设为12 , 输入/输出分辨率除特殊情况为 640 × 192, 学习率在前15周期里10^-4 ,在后来降为10^-5。 选用10%作为数据的验证集。平滑度部分λ 设为0.001.
总结
共三个贡献:
1)一个最小重投影误差,对每个像素进行计算,解决了单目视频中帧图像间的遮挡问题
2)设计一个auto-masking loss 忽略了不清晰以及固定的像素
3)全分辨率得多尺度采样方法