python数据分析:pandas学习之Series数组
为什么学习pandas
学习pandas需要一些numpy学习基础:numpy学习总结
虽然numpy已经可以结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢?
numpy 能够帮我们处理数值型数据,但是这还不够
很多时候,我们数据除了数值之外,还有字符串,时间序列等
比如:我们通过爬虫获取到了存储在数据库中的数据
所以, numpy能够帮助我们处理数值,但是pandas处理处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据
pandas常用的数据类型
1.Series一维, 带标签(索引)数组
2. DataFrame二维, Series容器
pandas的Series学习
- 创建一个Series数组
import pandas as pd
import numpy as np
# 创建长度为10的Series数组
t = pd.Series(np.arange(10))
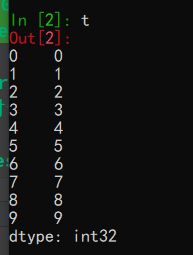
这样就可以创建一个简单的Series数组了,数组的左边是它的索引,右边是它的值
,因此它有index和values方法
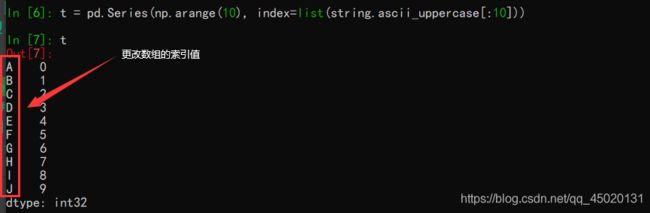
更改Series数组的索引值
其中index=list(string.ascii_uppercase[:10])表示的是取前10位大写字母来代替索引
在这里插入代码片
注意: pd.Series能够干什么,能够传入什么类型的数据让其变为series结构,index是什么?
在什么位置,对于我们常见的数据库或者ndarray来说,index是什么,如何给一组数据指定index?
在pd.Series()中的参数可以传入一个字典,也能传入一个列表,元组等
重新给其指定其他的索引之后,如果能够对应上,就取其值,如果不能,就为nan, 此时数据的类型就为float类型了,因为numpy中的nan为float类型,pandas会自动根据数据类型更改Series的dtype类型,若要修改此类型,使用.astype即可修改
pandas之Series切片和索引
t = pd.Series(np.arange(10), index=list(string.ascii_uppercase[:10]))
t[2:10:2] # 从第三个开始以步长为2,到第10个为止
t[[2, 3, 6]] # 选择第三个, 第四个, 和第七个的值
t["F"] # 选择索引为F的值
结果如下:
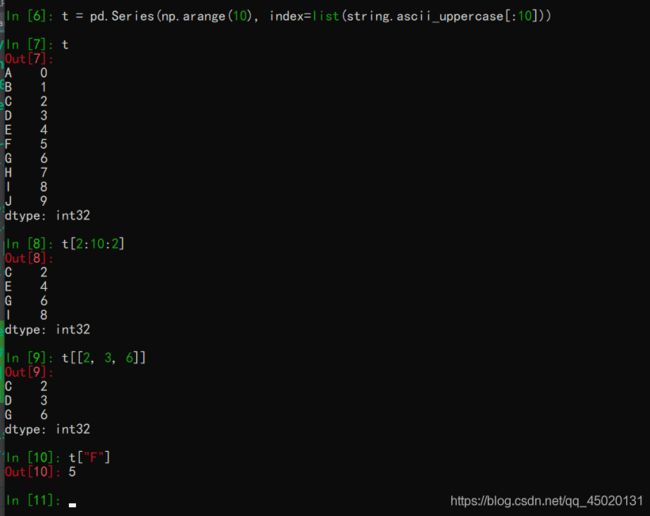
切片:在"[]"中直接传入start end 或者步长即可
索引:一个的时候传入序号或者index,多个的时候传入序号或者index的列表
pandas之Series的索引和值
对于一个陌生的series类型,我们如何知道它的索引和具体的值呢:
t.index ==> 返回数组的索引,是一个列表类型,可以进行遍历,也可进行强制类型转换,如: tuple(t.index) # 进行强制类型转换
t.values ==> 返回数组的值,是一个列表类型,可以进行遍历,也可进行强制类型转换,如: tuple(t.values)
Series对象本质上由两个数组构成。
一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键 -> 值
ndarray的很多方法都可以运用于series类型,比如argmax,clip
series具有where方法,但是结果和ndarray不同,具体方法可以查看官方文档np.Series.where使用教程
pandas读取mongodb数据
这里由于我的mongodb里面没有数据,所以我就手动添加了一些数据(0.0)
from pymongo import MongoClient
import pandas as pd
client = MongoClient()
collection = client["xin"]["test"]
data = list(collection.find())
a = ["hello", "world"]
data.append(a)
t1 = data[0]
t1 = pd.Series(t1)
print(t1)
结果如下

pandas读取外部文件
pandas提供了很多读取数据的方法,比如:

这里我以csv文件举例
import pandas as pd
# pandas 读取文件
t = pd.read_csv("./demo.csv")
print(t)
csv文件结果如下
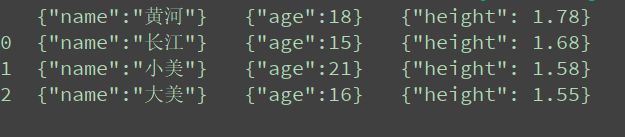
我们这组的数据存在csv文件中,我们直接使用pd.read_csv即可
和我们想象中的有些差别,我们以为他会是一个Series类型,但实际上它是一个DataFrame数组类型。
那么在下一小节中我们就来了解这种数据类型