总结:Different Methods for Weight Initialization in Deep Learning
这里总结了三种权重的初始化方法,前两种比较常见,后一种是最新的。为了表达顺畅(当时写给一个歪果仁看的),用了英文,欢迎补充和指正。
尊重原创,转载请注明:http://blog.csdn.net/tangwei2014
1. Gaussian
Weights are randomly drawn from Gaussian distributions with fixed mean (e.g., 0) and fixed standard deviation (e.g., 0.01).
This is the most common initialization method in deep learning.
2. Xavier
This method proposes to adopt a properly scaled uniform or Gaussian distribution for initialization.
In Caffe (an openframework for deep learning) [2], It initializes the weights in network by drawing them from a distribution with zero mean and a specific variance,

Where W is the initialization distribution for the neuron in question, and n_in is the number of neurons feeding into it. The distribution used is typically Gaussian or uniform.
In Glorot & Bengio’s paper [1], itoriginally recommended using 
Where n_out is the number of neurons the result is fed to.
Reference:
[1] X. Glorot and Y. Bengio. Understanding the difficulty of training deepfeedforward neural networks. In International Conference on Artificial Intelligence and Statistics, pages 249–256, 2010.
[2] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S.Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast featureembedding. arXiv:1408.5093, 2014.
3. MSRA
This method is proposed to solve the training of extremely deep rectified models directly from scratch [1].
In this method,weights are initialized with a zero-mean Gaussian distribution whose std is
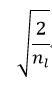
Where  is the spatial filter size in layer l and d_l−1 is the number of filters in layer l−1.
is the spatial filter size in layer l and d_l−1 is the number of filters in layer l−1.
Reference:
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, Technical report, arXiv, Feb. 2015