RLlib算法
1.High-throughput architectures(高通量的架构)
Distributed Prioritized Experience Replay (Ape-X)
Apex论文和实现
DQN、DDPG和QMIX (APEX_DQN、APEX_DDPG、APEX_QMIX)的Ape-X变量使用一个GPU学习器和许多CPU worker来收集实验。实验收集可以扩展到数百个CPU worker,因为实验的分布式优先级高于存储在重播缓冲区。
Tuned examples: PongNoFrameskip-v4, Pendulum-v0, MountainCarContinuous-v0, {BeamRider,Breakout,Qbert,SpaceInvaders}NoFrameskip-v4.
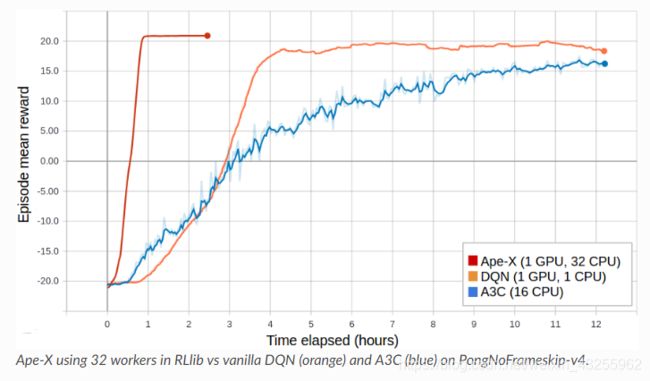
Atari results @10M steps: more details
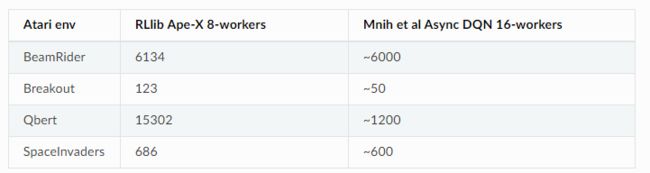
Scalability:

Ape-X 说明配置信息(详细信息请参考训练API)
APEX_DEFAULT_CONFIG = merge_dicts(
DQN_CONFIG, # see also the options in dqn.py, which are also supported
{
"optimizer": merge_dicts(
DQN_CONFIG["optimizer"], {
"max_weight_sync_delay": 400,
"num_replay_buffer_shards": 4,
"debug": False
}),
"n_step": 3,
"num_gpus": 1,
"num_workers": 32,
"buffer_size": 2000000,
"learning_starts": 50000,
"train_batch_size": 512,
"sample_batch_size": 50,
"target_network_update_freq": 500000,
"timesteps_per_iteration": 25000,
"per_worker_exploration": True,
"worker_side_prioritization": True,
"min_iter_time_s": 30,
},
)
Importance Weighted Actor-Learner Architecture (IMPALA)
IMPALA论文和实现。
在IMPALA中,一个中央学习者在一个紧密的循环中运行SGD,同时异步地从许多参与者进程中提取样本批。RLlib的IMPALA实现使用DeepMind的参考V-trace代码。注意,我们不提供开箱即用的深度剩余网络,但是可以作为自定义模型插入其中。还支持多个学习gpu和经验回放。
Atari results @10M steps: more details
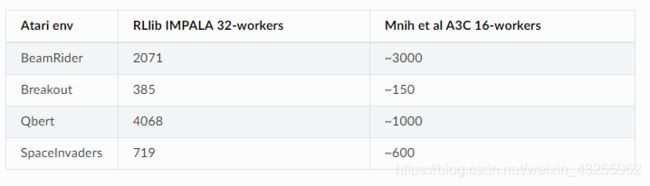

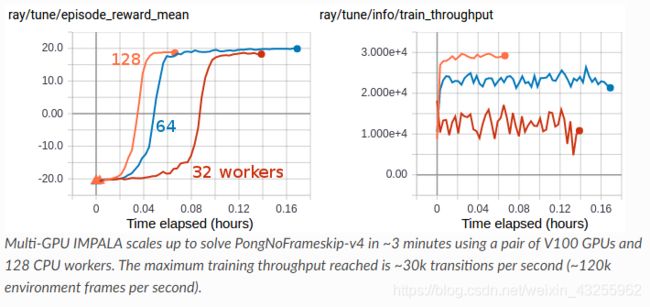
~使用一对V100 gpu和128个CPU工人,多gpu IMPALA可以在3分钟内解决PongNoFrameskip-v4问题。最大训练吞吐量达到30k转换每秒(120k环境帧每秒)。~
IMPALA-specific configs:
DEFAULT_CONFIG = with_common_config({
# V-trace params (see vtrace.py).
"vtrace": True,
"vtrace_clip_rho_threshold": 1.0,
"vtrace_clip_pg_rho_threshold": 1.0,
# System params.
#
# == Overview of data flow in IMPALA ==
# 1. Policy evaluation in parallel across `num_workers` actors produces
# batches of size `sample_batch_size * num_envs_per_worker`.
# 2. If enabled, the replay buffer stores and produces batches of size
# `sample_batch_size * num_envs_per_worker`.
# 3. If enabled, the minibatch ring buffer stores and replays batches of
# size `train_batch_size` up to `num_sgd_iter` times per batch.
# 4. The learner thread executes data parallel SGD across `num_gpus` GPUs
# on batches of size `train_batch_size`.
#
"sample_batch_size": 50,
"train_batch_size": 500,
"min_iter_time_s": 10,
"num_workers": 2,
# number of GPUs the learner should use.
"num_gpus": 1,
# set >1 to load data into GPUs in parallel. Increases GPU memory usage
# proportionally with the number of buffers.
"num_data_loader_buffers": 1,
# how many train batches should be retained for minibatching. This conf
# only has an effect if `num_sgd_iter > 1`.
"minibatch_buffer_size": 1,
# number of passes to make over each train batch
"num_sgd_iter": 1,
# set >0 to enable experience replay. Saved samples will be replayed with
# a p:1 proportion to new data samples.
"replay_proportion": 0.0,
# number of sample batches to store for replay. The number of transitions
# saved total will be (replay_buffer_num_slots * sample_batch_size).
"replay_buffer_num_slots": 0,
# max queue size for train batches feeding into the learner
"learner_queue_size": 16,
# level of queuing for sampling.
"max_sample_requests_in_flight_per_worker": 2,
# max number of workers to broadcast one set of weights to
"broadcast_interval": 1,
# use intermediate actors for multi-level aggregation. This can make sense
# if ingesting >2GB/s of samples, or if the data requires decompression.
"num_aggregation_workers": 0,
# Learning params.
"grad_clip": 40.0,
# either "adam" or "rmsprop"
"opt_type": "adam",
"lr": 0.0005,
"lr_schedule": None,
# rmsprop considered
"decay": 0.99,
"momentum": 0.0,
"epsilon": 0.1,
# balancing the three losses
"vf_loss_coeff": 0.5,
"entropy_coeff": 0.01,
# use fake (infinite speed) sampler for testing
"_fake_sampler": False,
})
Asynchronous Proximal Policy Optimization (APPO)
待完善。。。。
2.Gradient-based
Advantage Actor-Critic (A2C, A3C)
Deep Deterministic Policy Gradients (DDPG, TD3)
Deep Q Networks (DQN, Rainbow, Parametric DQN)
Policy Gradients
Proximal Policy Optimization (PPO)
3.Derivative-free
Augmented Random Search (ARS)
Evolution Strategies
4.Multi-agent specific
QMIX Monotonic Value Factorisation (QMIX, VDN, IQN)
5.Offline
Advantage Re-Weighted Imitation Learning (MARWIL)