Leaning the Model Update for Siamese Trackers 【论文笔记】
写前bb
最近在一直纠结Siamrpn的复现,由于对RPN网络和目标框回归的过程不是很了解,希望这周能搞清楚并且复现出来吧。看到公众号有推送ICCV2019的论文集,瞅了眼发现这篇文章名字异常显眼,立马下下来看起来!搜了下网上好像已经有相关的阅读笔记(还是我看的晚一点),我也挤挤时间Markdown一下啦。
Abstract
目前,现有的更新模板策略一般是线性组合先前的几帧,这样会导致随着时间的推移,信息大量的减少。(应该是说没有很好的去学习到前面的信息)因此,我们提出的方法是可以主动学习如何更新,而不是手动去设计更新规则,提出的方法是:UpdateNet。用了VOT2016,VOT2018,LaSOT和TrackingNet这些数据集来验证我们的方法。
1.Introduction
首先分析了一下已有的两种跟踪方法:基于Siamese网络的方法,还有一种是基于检测的跟踪方法。本文针对基于Siamese网络的方法,这是因为这种方法跑的速度和精度都有一定的保障。(然后讲了一下Siamese类的方法一般是怎么工作的,可以参考下我之前的那篇介绍Siamfc的论文笔记,这里就不过多叙述了。)目前大多基于Siamese网络的跟踪器处理更新问题,都是采用简单的线性更新策略,使用固定的学习率。(average这个操作不是很清楚)然而这种方法有个缺点,就是不能满足改变更新的需求并且运用到可能出现所有的场景中,并且这种更新是在全空间维度是固定的,这样就不能够做到局部的部分更新。举例:局部遮挡问题,这种问题就不能被很好地解决,因为这需要对模板的特定部分进行更新。
在本文中,我们提出的方法可以看做是一种函数,需要输入(1)第一帧的groundtruth模板。(2)由所有先前帧得到的累加模板。(3)在当前帧中所预测目标位置处的模板。我们将该UpdateNet结合SiamFC和DaSiamRPN来进行测试。
2.Related work
跟踪的框架 :目前现有的跟踪框架可以分为两类,基于检测和基于模板匹配的。基于检测的跟踪器是将目标的定位问题变成分类问题,通过目标前景和背景的图片来学习分类器从而得到决策边界。另一种方法是基于模板匹配的,通常是利用Siamese网络。
目标模板的更新 :目前的跟踪器用的更新策略方法有以下这些:(1)简单的线性拟合 (效果不好)(2)固定的更新策略(只用了最近的几帧信息)(3)利用先前一系列的frames来更新模板(计算量太大了)(4)ECO的更新策略(还是只用了线性拟合)然后列举了一些论文使用的方法,如使用LSTM来进行更新(效果不是很好),结合transformation matrix+regularized linear regression(存在边界效应)。最后还是我们提出的方法是最好的~
3.Updating the object template
我们在这节中,回顾了跟踪采用的标准更新机制,提出它们的缺点,然后介绍我们的方法是怎么解决这些问题的。
标准的更新方法 :最近一些跟踪方法使用了简单的averaging策略来更新目标表观模型(Given a new data sample不是很明白…)这种策略是源自于早期的跟踪方法,因为其能产生效果还行的结果,所以一直被当做在线更新的标准方法。在该方法中,模板利用随时间呈指数衰减的权值进行更新(这句话没有看很懂)。指数权值的选择由以下用来更新模板的递归公式产生:
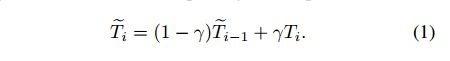
i i i是帧数, T i T_i Ti是仅利用当前帧计算得到的模板样本(后面再仔细解释下), T ~ i \tilde{T}_{i} T~i是累积模板,更新率 γ \gamma γ通常取一个固定小的数值(如0.01),依据目标在相邻帧中表观变化平稳的假设下。关于Siamese跟踪器, T T T指的是全卷积特征提取器在某一帧中所提取到的目标表观模板(我认为在这里指的应该是模板的特征)。尽管模板平均(template averaging不知道是什么意思)是一种简单的整合新信息的方法,但是还是有以下几个严重的缺陷:
- 给每个视频分别设定固定的更新率。
- 针对所有的空间维度的更新是固定的,包括通道维度,这样不能针对模板的部分区域进行更新,很难解决部分遮挡问题。
- 更新的时候逐步丢失掉 T 0 T_0 T0的信息,毫无疑问,它包含的信息才是标答。
- 更新机制只是对先前表观模板进行一个简单的线性组合。
学习更新:我们提出的能够学习可适应更新策略模型能够解决上述提到的问题。为了解决上述的问题,我们给出一个通用的函数来更新模板:
(公式中每个变量的意义在之前已经解释过了)这个函数用卷积神经网络来表示,我们把这个网络叫做UpdateNet。
运用 UpdateNet的跟踪框架

我们通过第一帧的groudtruth得到 T 0 G T T_0^{GT} T0GT ;通过用先前所有的帧 T ~ i − 1 \tilde{T}_{i-1} T~i−1预测到当前帧 i i i目标的位置(紫色的虚线),然后在这个区域内提取特征(蓝色的实线)。我们将 T 0 G T T_0^{GT} T0GT , T ~ i − 1 \tilde{T}_{i-1} T~i−1和 T i T_i Ti的特征当做网络的输入,输出新的累积的模板 T ~ i \tilde{T}_{i} T~i。对于第一帧,我们把 T ~ i − 1 \tilde{T}_{i-1} T~i−1和 T i T_i Ti设置为 T 0 G T T_0^{GT} T0GT 。同时,由于我们的输入只有 T 0 G T T_0^{GT} T0GT这个是groundtruth,所以我们采用残差学习策略,这样UpdateNet可以学习如何根据当前帧来利用 T 0 G T T_0^{GT} T0GT。该方法是将 T 0 G T T_0^{GT} T0GT与UpdateNet的输出加上一个短接。
训练UpdateNet:
我们训练updatenet来预测接下来帧的目标模板,预测的 T ~ i \tilde{T}_{i} T~i应该和从下一帧的gt位置截取的 T i + 1 G T T_{i+1}^{GT} Ti+1GT目标模板越相近越好。为了达到这个目的,我们通过缩小更新的模板和下一帧gt之间的欧氏距离,公式定义如下:

接下来,讲述如何产生训练所需要的数据,同时引入针对updatenet的多阶段训练。
训练样本: 首先训练updatenet网络,我们需要( T 0 G T T_0^{GT} T0GT, T ~ i − 1 \tilde{T}_{i-1} T~i−1, T i T_i Ti)和 T i + 1 G T T_{i+1}^{GT} Ti+1GT,其中 T ~ i − 1 \tilde{T}_{i-1} T~i−1和 T i + 1 G T T_{i+1}^{GT} Ti+1GT比较好得到(都是现成的),如果我们 T i T_i Ti用的是gt的话,Updatenet不能很好地学习(因为偏差会很小)。因此,我们利用在第i帧不精确的位置来提取 T i T_i Ti样本,可以利用累积的模板 T ~ i − 1 \tilde{T}_{i-1} T~i−1来模拟这个场景,理想的表示在线跟踪过程中会发生的误差。
多阶段训练: 理论上,我们可以利用updatenet产生的输出 T ~ i − 1 \tilde{T}_{i-1} T~i−1,但是这样会使得训练重循环,导致计算复杂。为了避免这样,我们分阶段来训练。第一个阶段,我们在训练集上运行原始的跟踪器,利用标准的线性更新:
![]()
这样,产生累积的模板,并为每一帧预测位置。同时,我们将更新率 γ \gamma γ调整到一个合适的值。尽管,我们采用的是比较简单的线性更新策略,但是也近似得到了在推理阶段给updatenet的输入值。在之后每一次训练阶段 k ∈ { 1 , . . . K } k \in \{1,...K\} k∈{1,...K},我们利用每上一个阶段训练出来的Updatenet来获得累加模板和预测的目标位置:

(Such training data samples closely resemble the expected data distribution at inference time, as they have been output by UpdateNet)在后面的实验阶段,我们得到一个比较合适的K值。
4.Experiment
训练数据集: 我们使用的是LaSOT,只用到了其中一个包含了20个序列的子集来自随机选取的20个不同的类别,一共有45578帧。我们发现仅仅使用这些就已经足够了,使用剩下的数据集带来的提升只有一些。
用来评估的数据集:VOT018/16 , LaSOT , TrackingNet
实施的细节: 我们使用Siamfc,Dasiamrpn作为我们的基准跟踪器,在训练阶段1的模板产生部分我们使用来自CFNet的更新率0.0102。 同时我们使用的是不添加更新策略的DaSiamRPN。在后面的小节中,分析了线性的更新率在跟踪表现上的影响。训练Updatenet期间,我们将 T 0 G T T_0^{GT} T0GT, T ~ i − 1 \tilde{T}_{i-1} T~i−1, T i T_i Ti和 T i + 1 G T T_{i+1}^{GT} Ti+1GT作为输入量,它们都是来自同一个视频。需要注意的是, T i T_i Ti和 T ~ i − 1 \tilde{T}_{i-1} T~i−1是产生于真实的跟踪过程,而 T 0 G T T_0^{GT} T0GT, T i + 1 G T T_{i+1}^{GT} Ti+1GT是ground-truth模板。模板的尺寸应该是H×W×C。Updatenet是一个两层的卷积神经网络:Conv1(1×1×3C×96)+ ReLU + Conv2(1×1×96×C)。对于Siamfc,H=W=6,C=256,而DaSiamRPN的C=512。在第一个阶段,权重是从零初始化的(?),同时学习率在每个epoch从 1 0 − 6 10^{-6} 10−6衰减至 1 0 − 7 10^{-7} 10−7。接下来的阶段,权重由上一阶段产生的最好的model来初始化,同时每个epoch中学习率由 1 0 − 7 10^{-7} 10−7衰减至 1 0 − 8 10^{-8} 10−8。我们训练的mini-batch的大小为64,epoch为50,使用SGD(momentum=0.9,weight decay= 0.0005)。
切割实验: blablabla做了一系类的切割实验,我们最后得出:训练三个阶段,同时skip connection从 T 0 G T T_0^{GT} T0GT开始,效果是最好的。
更新展示的分析:

为了了解在特征上进行更新策略的推理阶段,我们将SiamFC的累加模板可视化出来,其中包括利用线性更新和Updatenet的方法。同时我们还加进了ground-truth模板。(For each template we show the feature maps of the four most dynamic channels in the ground-truth template??不是很清楚为什么要进行这个操作,four most dynamic channels?是什么)。为了进行对比,累加模板的产生是利用ground-truth的物体位置,不采用跟踪阶段所预测到的位置。(这个原因说的也很敷衍…不是很明白)。在此期间,我们关注到一些有趣的事情,首先,使用UpdateNet积累的模板比线性更新中的模板更接近于ground-truth。其次,由Updatenet得到的response map更sharper,说明我们的更新策略没有对学到的特征desired correlation属性产生坏的影响。最后,线性更新策略得到的累积模板改变速度很慢,并且不能很好地应对视频中的表观变化。
为了进一步对所观察到的进行研究,我们提出量化相邻两帧的模板更新速度。对于每个 i ∈ { 1 , . . . , N } i\in\{1,...,N\} i∈{1,...,N} 我们计算模板的平均差异:
![]()
公式中,N代表视频的总帧数, ∑ \sum ∑指的是featuremap中所有的元素数目(eg,E=6×6×256)

最后一行的图包含了VOT2018总共60个视频的平均变化速度(很好奇到底是怎么画出来的??)从图上看,会发现Updatenet会比线性更新更接近ground-truth。
通用性和跟踪速度:在VOT2018数据集上,比较了各个算法的FPS和EAO的表现。
微调线性更新率: 在这节中讨论对测试集进行更新率的微调是否能够带来更好的表现
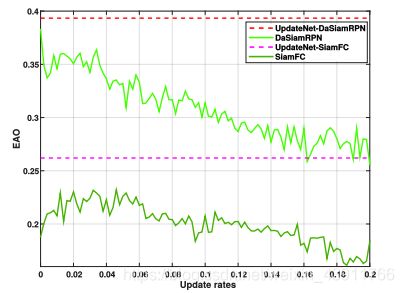
根据上图可以看出,即使对更新率进行了微调,也不能保证结果有所改进。(如DaSiamRPN随着更新率的增加,EAO一直在下降)
与其他更新策略的比较: 通过在VOT2016数据集上的结果比较,发现还是Updatenet更胜一筹。

LaSOT数据集:
LaSOT数据集里大部分都是长时间的序列,因此跟踪器的更新模块十分重要,我们在该数据集下比较了十种算法,最后我们的算法表现最佳。
TrackingNet数据集: 同上,结果是Updatenet的效果很明显
5.Conclusions
blahblahblah
写完bb
总体来说,这篇文章写得很通俗易懂,就是增加了一个网络来进行更新模板的学习和产生,对于训练阶段十分好奇到底是怎么实现的。还需要再仔细看代码好好理解下,希望今天杭州的雨赶快停把,渣男赶快开心起来!!!!(总算是把这篇文章给Markdown结束完)
2019.11.27