DianNao系列加速器总结(1)——架构与运算单元
本文为DianNao系列加速器总结的第一篇,有较多公式,简书不支持公式渲染,公示完整版待该总结完成后将统一发表在个人博客
简介
DianNao系列是中科院计算所推出的系列机器学习加速器,包括以下四个成员:
- DianNao:神经网络加速器,DianNao系列的开山之作。
- DaDianNao:神经网络“超级计算机”,DianNao的多核升级版本
- ShiDianNao:机器视觉专用加速器,集成了视频处理部分
- PuDianNao:机器学习加速器,DianNao系列收山之作,可支持7种机器学习算法
DianNao系列相比于其他神经网络加速器,除了关心运算的实现外,更关心存储的优化。
整体架构
DianNao系列的整体架构比较类似,均分为以下三个部分:
- 运算核心:完成对应的运算加速功能
- 缓存:缓存输入输出数据与参数,减小访存带宽需求
- 控制:协调运算核心和缓存的工作
前三代(DianNao,DaDianNao,ShiDianNao)的整体架构如下图所示:
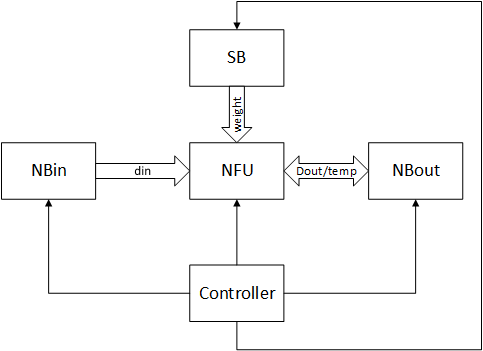
其中:
- NBin,NBout和SB:均为存储器,分别用于存储输入数据,输出数据或临时数据和参数
- NFU:运算核心,用于完成神经网络相关的运算
以下为原论文中所绘制的架构图(左图为DianNao/DaDianNao,右图为ShiDianNao):
[图片上传中...(PuDianNao_structure.png-dc039b-1525185332874-0)]

最后一代PuDianNao为了适应更多的机器学习算法(PuDianNao不专门为神经网络设计),抛弃了按功能分别缓存的方法,转而使用按重用频率缓存,因此架构上发生了一些变化,如下图所示:
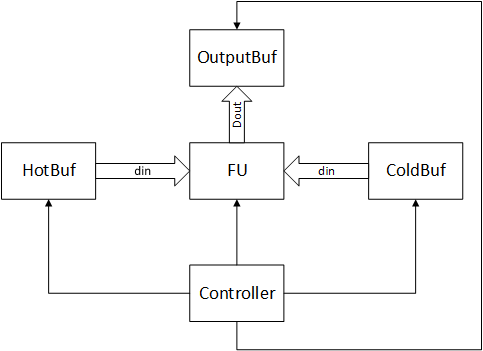
其中:
- HotBuf,ColdBuf:输入数据缓存,分别用于存储频繁重用和重用时间间隔较长的输入数据
- OutBuf:输出数据缓存,用于存储输出数据
- FU:功能模块,完成机器学习相关运算
- Controller:控制核心,协调存储器和功能模块的工作
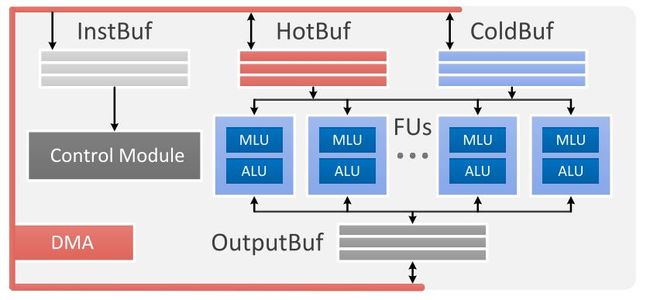
原论文中绘制的系统结构图如下所示:
运算模块
运算模块用于完成待加速的运算,是加速器的核心部分之一。
运算分析
DianNao系列的论文每一篇都会花大量的篇幅阐述运算分析部分,这对学习者来说非常友好。
DianNao与DaDianNao
这两个系列支持的神经网络计算类型较为基础,论文中概括,要想实现卷积神经网络,需要实现以下几种操作:
- 卷积运算:$out(x,y)^{fo} = \sum \limits_{f_i = 0}^{K_{if}} \sum \limits_{k_x = 0}^{K_x} \sum\limits_{k_y = 0}^{K_y} w_{f_i,f_o}(k_x,k_y) \times in(x+k_x,y+k_y)^{f_i}$
- 池化运算:$out(x,y)^f = max_{0 \leq k_x \leq K_x,0 \leq k_y \leq K_y} in(x+k_x,y+k_y)^f$
- LRN(区域响应标准化,当时批标准化还未流行):$out(x,y)^f = \cfrac{in(x,y)^f}{(c + \alpha \sum \limits_{g=max(0,f-k/2)}{min(N_f,f+k/2)}(a(x,y)g)2){\beta}}$
- 矩阵乘:$out(j) = t(\sum\limits^{N_i}{i = 0} w{ij} \cdot in(i))$
其中,DianNao未实现LRN功能,该功能在DaDianNao中才实现。另外,DaDianNao支持神经网络的训练,其训练过程所需要的运算,基本与测试过程基本相同。
ShiDianNao
ShiDianNao除了支持DianNao所支持的操作外,对于标准化,还支持LCN(局部对比度归一化):
$$
O^{mi}{a,b} = \cfrac{I^{mi}{a,b}}{(k+\alpha \times \sum\limits{min(Mi-1,mi+M/2)}_{j=max(0,mi-M/2)}(Ij_{a,b}))^\beta}
$$
PuDianNao
PuDianNao支持7种机器学习算法:神经网络,线性模型,支持向量机,决策树,朴素贝叶斯,K临近和K类聚,所需要支持的运算较多,因此PuDianNao的运算分析主要集中在存储方面,其运算核心的设计中说明PuDianNao支持的运算主要有:向量点乘,距离计算,计数,排序和非线性函数。其他未覆盖的计算使用ALU实现。
运算模块设计
DianNao
DianNao的运算模块奠定了DianNao系列运算模块的主基调。结构图如下所示:
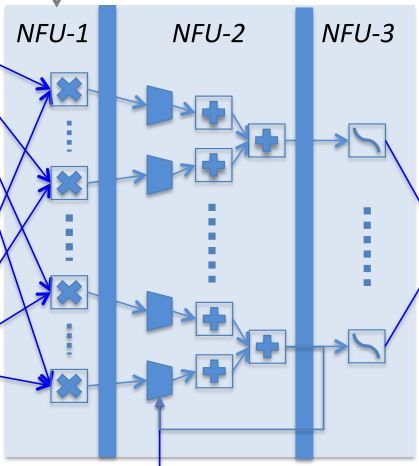
运算模块分为三级流水线:
- NFU-1:乘法器阵列,16bit定点数乘法器,1位符号位,5位整数位,10位小数位
- NFU-2:加法树/最大值树,将乘法器所得的结果累加或取最大值,可选的与上一次/部分和累加。这一部分的结尾处有寄存器结构,可以存储这一次运算的部分和。
- NFU-3:非线性激活函数,该部分由分段线性近似实现非线性函数
当需要实现向量相乘和卷积运算时,使用NFU-1完成对应位置元素相乘,NFU-2完成相乘结果相加,最后由NFU-3完成激活函数映射。完成池化运算时,使用NFU-2完成多个元素取最大值或取平均值运算。由此分析,尽管该运算模块非常简单,也覆盖了神经网络所需要的大部分运算(LRN在DianNao中未实现)
DaDianNao
DaDianNao的运算单元NFU与DianNao基本相同,最大的区别是为了完成训练任务多加了几条数据通路,且配置更加灵活。NFU的尺寸为16x16,即16个输出神经元,每个输出神经元有16个输入(输入端需要一次提供256个数据)。同时,NFU可以可选的跳过一些步骤以达到灵活可配置的功能。DaDianNao的NFU结构如下所示:
ShiDianNao
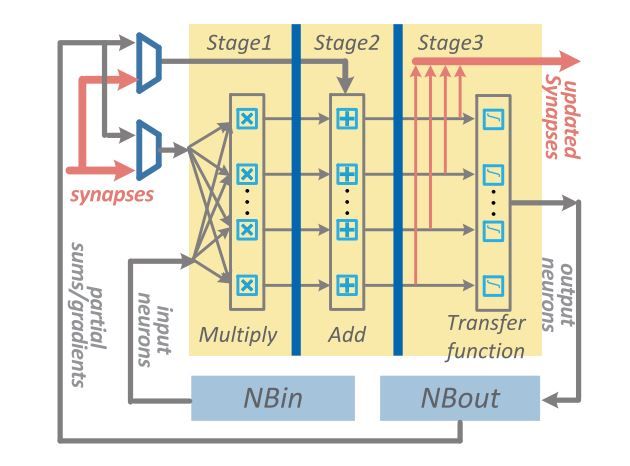
ShiDianNao是DianNao系列中唯一一个考虑运算单元级数据重用的加速器,也是唯一使用二维运算阵列的加速器,其加速器的运算阵列结构如下所示:

ShiDianNao的运算阵列为2D格点结构,对于每一个运算单元(节点)而言,运算所使用的参数统一来源于Kernel,而参与运算的数据则可能来自于:
- 数据缓存NBin
- 下方的节点
- 右侧的节点
下图为每个运算单元的结构(左)和抽象结构(右):
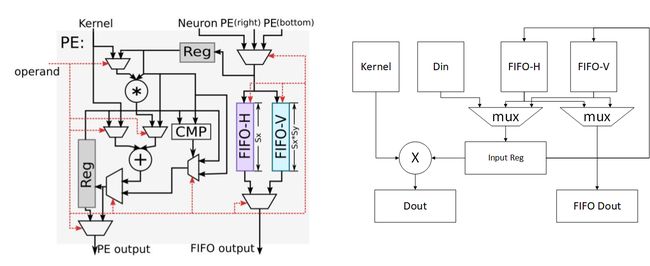
该计算节点的功能包括转发数据和进行计算:
- 转发数据:每个数据可来源于右侧节点,下方节点和NBin,根据控制信号选择其中一个存储到输入寄存器中,且根据控制信号可选的将其存储到FIFO-H和FIFO-V中。同时根据控制信号选择FIFO-H和FIFO-V中的信号从FIFO output端口输出
- 进行计算:根据控制信号进行计算,包括相加,累加,乘加和比较等,并将结果存储到输出寄存器中,并根据控制信号选择寄存器或计算结果输出到PE output端口。
对于计算功能,根据上文的结构图,可以发现,PE支持的运算有:kernel和输入数据相乘并与输出寄存器数据相加(乘加),输入数据与输出寄存器数据取最大或最小(应用于池化),kernel与输入数据相加(向量加法),输入数据与输出寄存器数据相加(累加)等。
PuDianNao
PuDianNao的运算单元是电脑系列中唯一一个异构的,除了有MLU(机器学习单元)外,还有一个ALU用于处理通用运算和MLU无法处理的运算,其运算单元(左)和MLU(右)结构如下图所示:
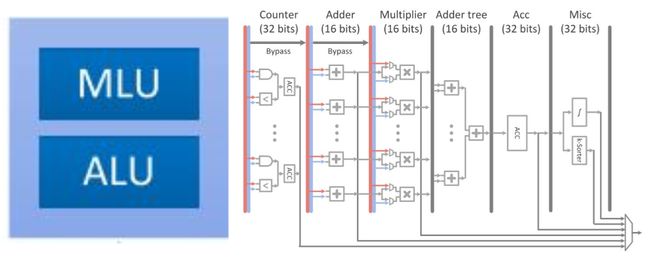
MLU分为6层:
- 计数层/比较层:这一层的处理为两个数按位与或比较大小,结果将被累加,这一层可以单独输出且可以被bypass
- 加法层:这一层为两个输入对应相加,这一层可以单独输出且可以被bypass
- 乘法层:这一层为两个输入或上一层(加法层)结果对应位置相乘,可以单独输出
- 加法树层:将乘法层的结果累加
- 累加层:将上一层(加法树层)的结果累加,可以单独输出
- 特殊处理层:由一个分段线性逼近实现的非线性函数和k排序器(输出上一层输出中最小的输出)组成
该运算单元是DianNao系列中功能最多的单元,配置非常灵活。例如实现向量相乘(对应位置相乘后累加)时,弃用计数层,加法层,将数据从乘法层,加法树层和累加层流过即可实现。