无监督学习 | DBSCAN 原理及Sklearn实现
文章目录
- 1. 密度聚类
- 2. DBSCAN
- 2.1 算法原理
- 3. DBSCAN 优缺点
- 3.1 优点
- 3.2 缺点
- 3.3 与 KMeans 比较
- 4. SKlearn 实现
- 5. 在线可视化 DBSCAN
- 参考文献
相关文章:
机器学习 | 目录
机器学习 | 聚类评估指标
机器学习 | 距离计算
无监督学习 | KMeans 与 KMeans++ 原理
无监督学习 | GMM 高斯混合聚类原理及Sklearn实现
1. 密度聚类
密度聚类亦称“基于密度的聚类”(Density-Based Clustering),此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果[1]。这类算法可以克服 KMeans、BIRCH等只适用于凸样本集的情况。
常用的密度聚类算法:DBSCAN、MDCA、OPTICS、DENCLUE等。[2]
密度聚类的主要特点是:
(1)发现任意形状的簇
(2)对噪声数据不敏感
(3)一次扫描
(4)需要密度参数作为停止条件
(5)计算量大、复杂度高
2. DBSCAN
DBSCAN(具有噪声的基于密度的空间聚类,Density-Based Spatial Clustering of Applications with Noise)是一种著名的密度聚类算法,它基于一组“邻域”(neighborhood)参数( ε , M i n P t s \varepsilon, MinPts ε,MinPts)来刻画样本分布的紧密程度。
首先我们通过一个简单的例子来介绍 DBSCAN,对于以下数据,我们任意选取一个点,定义一个以 ϵ \epsilon ϵ 为半径的邻域,若邻域内没有其他点,则这个点定义为噪声或异常点。

若这个点不是噪声,则考虑第二个参数:邻域内最少样本个数 M i n P t s MinPts MinPts,若某点邻域内最少样本个数不少于 M i n P t s MinPts MinPts,则这个点定义为核心点。对于该邻域内的非核心对象,定义为边界点,假设 M i n P t s MinPts MinPts=5 ,则聚类过程如下图所示:

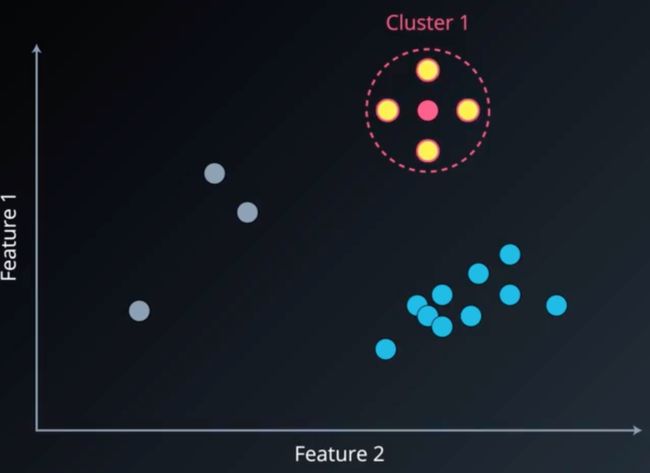
同理,继续扫描其余的点,可得其他簇:
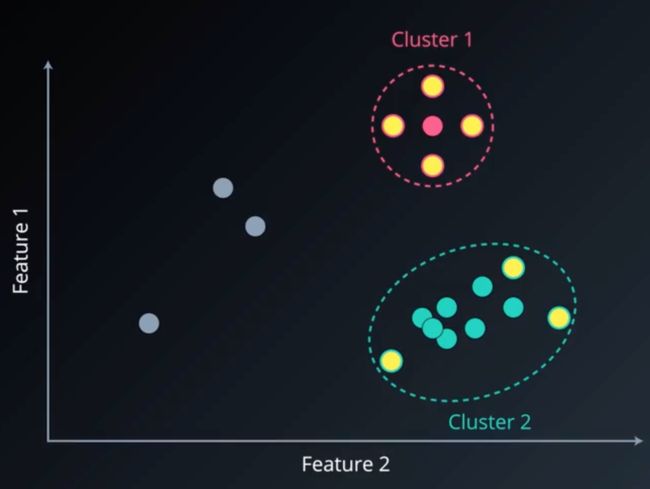
下面,我们将通过严格的数学定义,来描述 DBSCAN 聚类算法。
2.1 算法原理
首先,给定数据集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m\} D={x1,x2,...,xm},我们定义下面几个概念:
-
ϵ \epsilon ϵ 邻域:对 x j ∈ D x_j \in D xj∈D,其 ϵ \epsilon ϵ 邻域包含数据集 D D D 中与 x j x_j xj 的距离不大于 ϵ \epsilon ϵ 的样本,即 N ϵ = { x o ∈ D ∣ d i s t ( x i , x j ≤ ϵ ) } N_{\epsilon}=\{x_o \in D| dist(x_i,x_j \leq \epsilon) \} Nϵ={xo∈D∣dist(xi,xj≤ϵ)};
-
核心对象(core object):若 x j x_j xj 的 ε \varepsilon ε 邻域至少包含 M i n P t s MinPts MinPts 个样本,即 ∣ N ϵ ( x j ) ≥ M i n P t s ∣ |N_{\epsilon}(x_j) \geq MinPts| ∣Nϵ(xj)≥MinPts∣,则 x j x_j xj 是一个核心对象;
-
密度直达(directly density-reachable):若 x j x_j xj 位于 x i x_i xi 的 ϵ \epsilon ϵ 邻域中,且 x i x_i xi 是核心对象,则称 x j x_j xj 由 x i x_i xi 密度直达;
-
密度可达(density-reachable):对 x i x_i xi 与 x j x_j xj,若存在样本序列 p 1 , p 2 , . . . , p n p_1,p_2,...,p_n p1,p2,...,pn,其中 p 1 = x i , p n = x j p_1 = x_i,p_n=x_j p1=xi,pn=xj 且 p i + 1 p_{i+1} pi+1 由 p i p_i pi 密度直达,则称 x i x_i xi 由 x j x_j xj 可达;
-
密度相连(density-connected):对 x i x_i xi 与 x j x_j xj,若存在 x k x_k xk 使得 x i x_i xi 与 x j x_j xj 均由 x k x_k xk 密度可达,则称 x i x_i xi 与 x j x_j xj 密度相连。
对于邻域中的距离函数 dist(⋅,⋅),在默认情形下设为欧式距离。
下图给出了上述概念的直观显示,假设 M i n P t s = 3 MinPts=3 MinPts=3:虚线显示出 ϵ \epsilon ϵ 邻域, x 1 x_1 x1 是核心对象, x 2 x_2 x2 由 x 1 x_1 x1 密度直达, x 3 x_3 x3 由 x 1 x_1 x1 密度可达, x 3 x_3 x3 与 x 4 x_4 x4 密度相连。
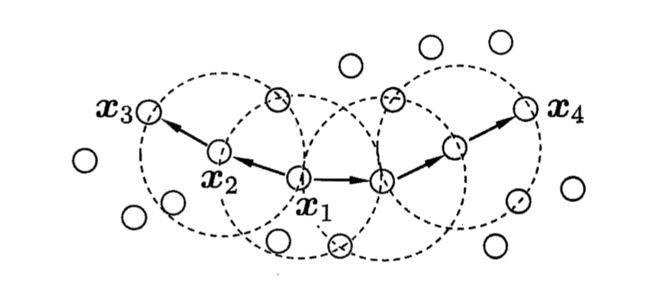
基于这些概念,DBSCAN 将“簇”定义为:密度可达关系导出的最大的密度相连样本集合。形式化地说,给定邻域参数( ϵ , M i n P t s \epsilon,MinPts ϵ,MinPts),簇 C ⊆ D C \subseteq D C⊆D 是满足以下性质的非空样本子集:
连 接 性 ( c o n n e c t i v i t y ) : x i ∈ C , x j ∈ C ⇒ x i 与 x j 密 度 相 连 (1) 连接性(connectivity):x_i \in C,x_j \in C \Rightarrow x_i 与 x_j 密度相连 \tag{1} 连接性(connectivity):xi∈C,xj∈C⇒xi与xj密度相连(1)
最 大 性 ( m a x i m a l i t y ) : x i ∈ C , x j 由 x i 密 度 可 达 ⇒ x j ∈ C (2) 最大性(maximality):x_i \in C,x_j 由 x_i 密度可达 \Rightarrow x_j \in C \tag{2} 最大性(maximality):xi∈C,xj由xi密度可达⇒xj∈C(2)
若 x x x 为核心对象,则 x x x 密度可达的所有样本组成的集合记为 X = { x ′ ∈ D ∣ x ′ 由 x 密 度 可 达 } X=\{x' \in D| x' 由 x 密度可达\} X={x′∈D∣x′由x密度可达},其中 X X X 为满足连接性和最大性的簇。
于是,DBSCAN 算法先任选数据集中的一个核心对象为“种子”(seed),再由此出发确定相应的聚类簇。
算法描述如下图所示,
-
在第 1-7 行中,算法先根据给定的邻域参数( ϵ , M i n P t s \epsilon,MinPts ϵ,MinPts)找出所有核心对象;
-
在第 10-24 行中,以任一核心对象为出发点,找出由密度可达的样本以生成聚类簇,知道所有核心对象均被访问过为止。

3. DBSCAN 优缺点
3.1 优点
(1)不用指明类别数量;
(2)能灵活找到并分离各种形状和大小的类;
(3)能很好地处理噪声和离群点。
3.2 缺点
(1)对于从两个类均可达的边界点,由于各个点是被随机访问的,因此 DBSCAN 不能保证每次都返回相同聚类;
(2)在不同密度的类方面有一定难度。
3.3 与 KMeans 比较
从下面的图中可以看出,DBSCAN 在不规则的数据上,能更好地分类。
4. SKlearn 实现
sklearn.cluster.DBSCAN(eps=0.5, min_samples=5, metric=’euclidean’, metric_params=None, algorithm=’auto’, leaf_size=30, p=None, n_jobs=None)
eps : float, optional 【 ϵ \epsilon ϵ】
The maximum distance between two samples for one to be considered as in the neighborhood of the other. This is not a maximum bound on the distances of points within a cluster. This is the most important DBSCAN parameter to choose appropriately for your data set and distance function.
min_samples : int, optional 【 M i n P t s MinPts MinPts】
The number of samples (or total weight) in a neighborhood for a point to be considered as a core point. This includes the point itself.
5. 在线可视化 DBSCAN
你可以通过这个网站选择样本分布和参数,并在线可视化 DBSCAN 聚类的过程。

参考文献
[1] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 211.
[2] liuy9803.机器学习之密度聚类算法[EB/OL].https://blog.csdn.net/liuy9803/article/details/80812489, 2018-06-26 .