Prometheus学习笔记(三)Alertmanager报警模块集成钉钉机器人
一、简介
Alertmanager是Prometheus的一个报警通知组件,需要结合Prometheus使用。Prometheus将监测到的异常事件发送给Alertmanager,Alertmanager发送异常事件的通知(邮件、webhook等)。
Prometheus安装文档
二、安装Alertmanager
Alertmanager下载地址
# 解压安装包
tar -zxvf alertmanager-0.21.0.linux-amd64.tar.gz
# 文件列表
./
├── alertmanager # alertmanager的启动程序
├── alertmanager.yml # alertmanager的配置文件
├── amtool
├── LICENSE
└── NOTICE
三、报警规则
修改prometheus的配置文件prometheus.yml
# Alertmanager configuration
# 改为alertmanager的地址
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.1.23:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
# 指定规则文件
rule_files:
- rules/*.yml
在rules目录中添加.yml结尾的规则文件,prometheus会根据这些规则配置文件进行监控报警。
模版:
# 一个配置文件里包含多个组
groups:
- name: example # 组名
# 触发规则列表
rules:
- alert: HighErrorRate # 警告名
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 # 触发规则
for: 10m # 规则触发持续多长时间发送告警
# 告警附加标签
labels:
severity: page
# 告警附加注释
annotations:
summary: High request latency
- node_alived.yml
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up == 0
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "主机宕机 !!!"
description: "该实例主机已经宕机超过一分钟了。"
- memory_over.yml
groups:
- name: 内存报警规则
rules:
- alert: 内存使用率告警
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 50
for: 1m
labels:
severity: warning
annotations:
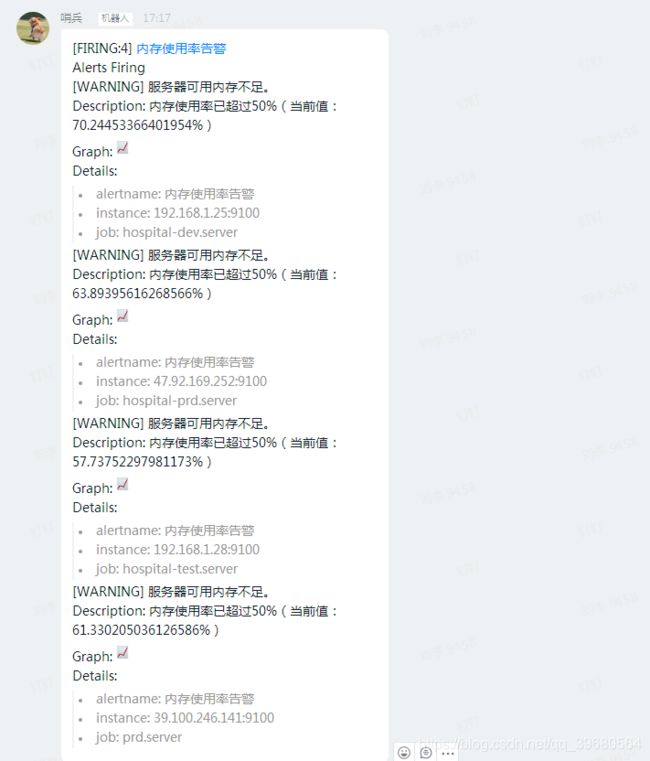
summary: "服务器可用内存不足。"
description: "内存使用率已超过50%(当前值:{{ $value }}%)"
- cpu_over.yml
groups:
- name: CPU报警规则
rules:
- alert: CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 50
for: 1m
labels:
severity: warning
annotations:
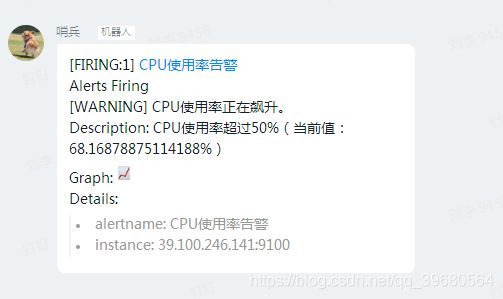
summary: "CPU使用率正在飙升。"
description: "CPU使用率超过50%(当前值:{{ $value }}%)"
- disk_over.yml
groups:
- name: 磁盘使用率报警规则
rules:
- alert: 磁盘使用率告警
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 80
for: 20m
labels:
severity: warning
annotations:
summary: "硬盘分区使用率过高"
description: "分区使用大于80%(当前值:{{ $value }}%)"
热加载配置
curl -XPOST 127.0.0.1:9090/-/reload
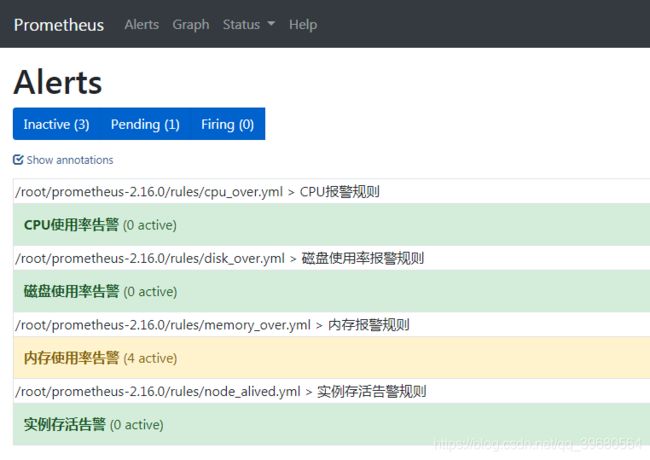
登陆prometheus的UI界面,查看Alerts规则
- Inactive:没有触发阈值
- Pending:已触发阈值但未满足告警持续时间
- Firing:已触发阈值且满足告警持续时间
四、通知规则
docker安装钉钉报警插件,启用一个名为:webhook1的钉钉机器人。
docker run -d \
--name dingtalk \
--restart always \
-p 8060:8060 \
timonwong/prometheus-webhook-dingtalk:master \
--ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=xxxx(自己的钉钉机器人token)"
设置alertmanager.yml的route与receivers。
route属性用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- send_resolved: true
url: 'http://192.168.1.23:8060/dingtalk/webhook1/send'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
启动alertmanager测试