论文翻译:GraphTCN: Spatio-Temporal Interaction Modeling for Human Trajectory Prediction(行人轨迹预测2020)
GraphTCN: Spatio-Temporal Interaction Modeling for Human Trajectory Prediction
- 摘要
- 1 引言
- 2 相关工作
- 3 GraphTCN
- 4 实验
- 5 结论
GraphTCN:用于人类轨迹预测的时空交互建模
收录于CVPR2020
作者:Chengxin Wang, Shaofeng Cai, and Gary Tan
论文地址:arXiv:2003.07167v3 [cs.CV]
发表时间:26 Mar 2020
摘要
轨迹预测是在具有多智能体交互的自治应用程序中预测智能体的未来路径的一项基本且具有挑战性的任务,在智能应用程序中,智能体需要预测其相邻物体的未来运动以避免碰撞。为了及时准确地对环境做出反应,预测中需要高效率和准确性。常规方法,例如基于LSTM的模型,在预测中要花费相当大的计算成本,特别是对于长序列预测。为了支持更有效和准确的轨迹预测,我们改为提出一种基于CNN的新型时空图框架**GraphTCN,该框架以输入感知的方式捕获时空交互。**使用边缘图注意网络(EGAT)捕获代理在每个时间步的空间交互,并使用改进的门控卷积网络(CNN)对跨时间步的时间交互进行建模。与传统模型相比,GraphTCN中的空间模型和时间模型都是在每个本地时间窗口内计算的。因此,可以并行执行GraphTCN,以实现更高的效率,同时精度可与最佳方法相媲美。实验结果证实,与各种轨迹预测基准数据集上的最新方法相比,GraphTCN在效率和准确性上均实现了明显更好的性能。
1 引言
轨迹预测是自主应用程序的一项基本任务,如自主车辆、社交顺从机器人、模拟器中的代理,以便在共享环境中导航。
为了对环境作出及时和准确的反应,agent能够有效和准确地预测其邻居的未来路径是非常必要的。
虽然最近的研究[24,32,19]在建模复杂的社会互动之间的代理产生准确的未来路径方面取得了很大的进步,但轨迹预测仍然是一项具有挑战性的任务,其中预测模型在现实应用中的部署大多受到其高计算成本的限制。例如,某些小型机器人仅配备了有限的计算设备,无法承受现有解决方案的高推理成本。
特别地,轨迹预测通常在两个维度上建模,即时间维度和空间维度。时间维度为每个agent建模了历史运动动态。大多数最新技术[1,14,24,19]都专注于递归神经网络(RNN),例如长短期记忆(LSTM)[17]网络,以捕获此类序列动态因为RNN是专为序列建模而设计的。但是,**基于RNN的模型受到以下两个限制。
首先,在有效性方面,训练RNN模型由于梯度消失和爆炸问题而难以处理[28],尽管从理论上讲RNN在顺序数据建模中更具表现力,但实际上在很大程度上缺乏这种表现力[3]。 正如最近的发现所支持的那样,前馈网络(例如卷积神经网络(CNN))实际上可以在基准序列预测任务(例如语言建模[6]和机器翻译[10])上与RNN相媲美甚至更好。
其次,就效率而言,与前馈模型相比,RNN模型的训练和推理速度都非常慢。这是由于RNN的每个隐藏状态都依赖于先前的输入和隐藏状态这一事实。因此,RNN的预测是顺序生成的,因此无法并行化。
空间
空间维度模拟了agent与其邻居之间的相互作用。已经提出了三种捕获空间交互的方法,包括基于池的(pooling-based)[1,14],基于距离的[24]和基于注意力的(attention-based)[32,9,39,19]。基于池的方法采用基于网格的池[1]或对称函数[14]来汇总邻居的隐藏状态,而基于距离的方法则使用LSTM编码器对代理之间的几何关系进行编码。基于注意力的方法改为使用软注意力动态地产生邻居的重要性,这在建模复杂的社会互动中更为有效。但是,与基于池的方法和基于距离的方法相比,现有的基于注意力的方法过度依赖注意力,并且忽略了代理之间的几何距离。
为了解决上述在有效性和效率上的局限性,我们提出了一种基于CNN的新型时空图网络(STGNN),即GraphTCN,以捕获时空相互作用以进行轨迹预测。
时间
在时间维度上,与基于RNN的方法相比,我们采用了**改进的门控卷积网络(TCN)**来捕获每个代理的时间动态。CNN引入门控式高速公路机制通过关注更显着的特征来动态地调节信息流,而CNN的前馈特性使其在训练中更易于处理,并且可并行化,从而在训练和推理上都具有更高的效率。
在空间维度上,我们为每个时刻提出了一个边缘图注意力神经网络(EGAT),以更好地捕获代理之间的空间交互作用。
图中的节点表示代理(agent),两个代理之间的边表示它们的几何关系。 EGAT然后自适应地学习图的邻接矩阵,即图的自适应空间交互作用。总之,GraphTCN的空间和时间模块支持对代理之间的每个时间步长内以及每个代理的整个时间步内交互进行更有效的建模。我们的主要贡献可以概括如下:
1.我们提出了一种边缘图注意力神经网络(EGAT),以利用自注意力机制更好地捕获空间相互作用。
2.我们建议使用门控卷积网络(TCN)对时空相互作用进行建模,这被证明更加有效。
3.与最新方法相比,我们的时空框架实现了明显更好的性能。具体而言,我们将平均位移误差降低了20.9%,将最终位移误差降低了31.3%,并且与现有解决方案相比,可实现高达5.37倍wall-clock 的时间加速。
我们将本文组织如下:
在第二部分,我们介绍了背景并详细讨论了相关工作。
我们的GraphTCN框架和实现细节将在第3节中介绍。
在第4节中,将以准确度和效率衡量的GraphTCN结果与最新方法进行比较。
第5节总结了论文。
2 相关工作
2.1 Human-Human Interactions(人-人互动)
人群交互模型的研究可以追溯到社会力量模型[16],该模型采用非线性耦合的Langevin方程来表示在拥挤的场景中人类运动的吸引力和排斥力。类似的手工方法已经尝试使用连续体动力学[37],离散选择框架[2],高斯过程[41],贝叶斯模型[42]来建模人群交互,并在人群模拟[18,31]、 人群行为检测[25]和轨迹预测[44]中被证明是成功的。
但是,这些方法仅基于心理或身体认识来对社会行为进行建模,仅靠心理或身体认识不足以捕获复杂的人群互动。最近的工作已经研究了深度学习技术,以捕获代理(agent)与邻居(neighbors)之间的交互。Social LSTM [1]引入了社交池层,以聚合代理本地社区内的社交隐藏状态。Social GAN [14]使用对称函数来总结人群的全局交互,这是通过仅将上下文合并一次而有效实现的。与这些基于池的方法不同,基于注意力的方法[32,39,9]通过软注意力来区分邻居的重要性。基于注意力的方案提供了更好的人群理解,因为它们在行人之间分配了自适应的重要性。与注意力方法类似,图注意力网络(GAT)通过与邻接矩阵自适应地聚集邻域特征来学习社会交互。近期作品STGAT[19]直接采用GAT对LSTM隐藏状态的捕捉,捕捉行人之间的空间互动;但它完全依赖于注意力,忽略了agent的距离特征。
为了更好地捕获距离特征,我们使用新颖的图神经网络EGAT对行人交互进行建模,该网络建议学习图的邻接矩阵。具体而言,距离特征用于为最显着的交互信息学习自适应邻接矩阵,然后将其集成到图卷积中。
2.2Sequence Prediction(序列预测)
序列预测是指利用历史序列信息预测未来序列的问题。序列预测主要有两种方法,即基于模式的方法和基于计划的方法。
基于模式的方法总结序列的行为来生成序列,而基于计划的方法,如[21,22,30],通过学习概率分布来进行序列预测。最近,基于模式的方法已成为序列预测任务的主流,如速度识别[27,5,13]、活动识别[8,20]和自然语言处理[4,35,11]。具体来说,轨迹预测可以表示为序列预测任务,它利用agent的历史运动模式来生成序列中未来的路径。大多数轨迹预测方法采用递归神经网络(RNNs),例如长短期记忆(LSTM)网络[17],来捕捉序列中的时间运动,因为RNNs是为序列建模而设计的。然而,基于RNN的模型在训练过程中会遇到梯度消失和爆炸的问题,在预测过程中会过于关注最近的输入,尤其是对于长输入序列。
为了克服这些问题,许多序列预测工作[27,43]改为采用卷积神经网络(CNN),并取得了巨大的成功。卷积网络可以更好地捕获长期依赖性并大大提高预测效率。基于CNN的方法的优越性可以很大程度上归因于卷积运算,该运算独立于先前的时间步长,因此可以并行处理。最近的工作[26]提出了一个紧凑的CNN模型来捕获时间信息,并提出一个MLP层来同时生成未来序列。他们的结果证实,基于CNN的模型可以在轨迹预测中产生竞争性能。但是,它无法对行人之间的空间互动进行建模。
在这项工作中,我们建议捕获与EGAT的空间交互,并引入门控卷积网络以捕获每个行人的时间动态。具体来说,我们的CNN采用高速公路网络架构[34]来动态调节信息流,并跳过连接[15]以方便表征学习和训练。
2.3 Spatial-temporal Graph Networks for Trajectory Prediction(用于轨迹预测的时空图网络)
近年来,许多研究尝试将时空图神经网络(STGNN)用于序列预测任务,例如动作识别[45,33],出租车需求预测[47]和交通预测[46]。具体地,该序列可以被表述为节点和边缘的图的序列,其中节点对应于主体,边缘对应于它们的相互作用。因此,可以使用时空图网络对序列进行有效建模。
在轨迹预测中,可以在两个维度上对预测任务进行建模,即空间维度和时间维度。
具体而言,空间维度对主体及其邻居之间的交互进行建模,而时间维度对每个主体的历史轨迹进行建模。
因此,在STGNN中,图中的每个节点代表一个场景中的一个行人,并且两个节点之间的每个边捕获了两个相应行人之间的交互。例如,social attention[39]用主体的位置对每个节点进行建模,并用行人之间的距离对边缘进行建模,其中空间关系用注意力模块进行建模,然后用RNN进行时间建模。同样,[40]根据位置,用Edge RNN和Node RNN构造STGNN。 STGAT [19]使用GAT通过为邻居分配不同的重要性来捕获空间交互,并采用额外的LSTM来捕获每个代理的时间信息。这些方法的主要局限性是难以捕获沿时间维度的空间交互作用。值得注意的是,代理商的未来之路不仅取决于当前位置,还取决于其邻居。但是,在使用基于RNN的模型沿时间维度聚合节点特征期间,此类空间交互的细节可能会丢失。
3 GraphTCN
轨迹预测的目标是共同预测场景中存在的所有代理的未来路径。自然,代理的未来路径取决于其历史轨迹,即时间相互作用,并且还受邻近代理的轨迹,即空间相互作用的影响。因此,在为预测建模时空相互作用时,应该将轨迹预测模型考虑到这两个特征。
3.1. Problem Formulation
形式上,轨迹预测可以表示如下。我们假设在场景中观察到的N个行人的Tobs(观察时间)的轨迹长。
单个行人的位置i∈{1,…, N}在时间步长t∈{1,…, Tobs}记![]() ,则行人Xi的观察位置表示为
,则行人Xi的观察位置表示为![]() 轨迹预测的目标是预测所有的未来位置
轨迹预测的目标是预测所有的未来位置![]() 。
。
3.2. Overall Framework
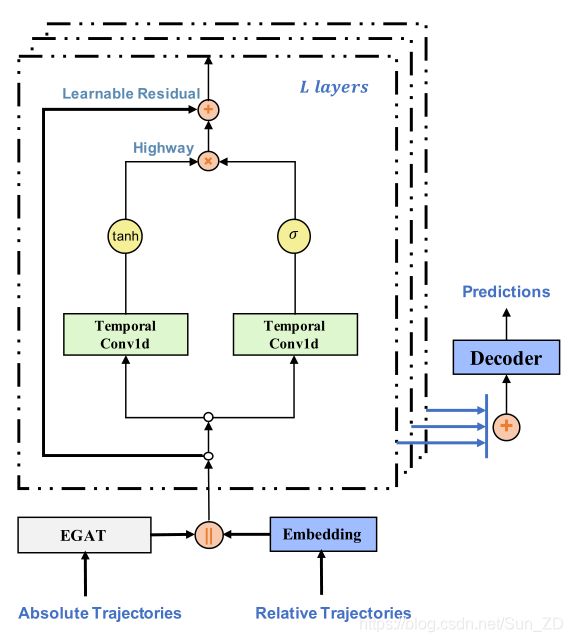
如图1所示,GraphTCN包括三个关键模块,包括边缘图关注(EGAT)模块,门控时间卷积(TCN)模块和解码器。
首先,EGAT捕获每个时间步长之间行人之间的空间互动。由于空间相互作用仅受行人之间的几何距离影响,因此我们仅将绝对轨迹输入到EGAT模块中。
如图1所示,GraphTCN由三个关键模块组成,分别是边缘图注意(EGAT)模块、门控时序卷积(TCN)模块和解码器。
首先,EGAT捕捉了行人在每个时间步间的空间互动。我们只在EGAT模块中输入绝对轨迹,因为空间的相互作用应该只受行人之间的几何距离的影响。(EGAT)![]()
然后对于每个时间步长,我们将每个行人的相对位置嵌入到一个固定长度的隐藏空间中,即时间嵌入,它代表了行人的时间动态,如步态、速度和加速度等。(Embedding)![]()
EGAT嵌入和时间嵌入随后在每个时间步长被连接在一起,作为TCN模块的输入。![]()
TCN模块是一个具有残差跳接[15]的前馈一维卷积网络[27]。剩余连接有助于梯度反向传播,使训练更加稳定;跳过连接有助于将中间特征转发给解码器模块,使预测更加准确。最后,解码器模块同时产生所有行人的未来轨迹。我们的框架的更多细节将在下面的部分中详细阐述。
3.3. EGAT Module for Spatial Interaction(EGAT空间互动模块)
总结:EGAT捕捉了行人在每个时间步间的空间互动。
输入:每个时间步上所有行人的绝对轨迹(因为空间的相互作用应该只受行人之间的几何距离的影响)
信息:节点,边,邻接矩阵
EGAT模块设计用于编码行人之间的空间互动。形式上,同一时间步内的行人可表示为无向图![]() ,其中节点
,其中节点![]() 对应第i个行人,加权边
对应第i个行人,加权边![]() 表示行人i和j之间的人与人之间的相互作用。
表示行人i和j之间的人与人之间的相互作用。
因此给 g 的邻接矩阵![]() 表示行人之间的空间关系。
表示行人之间的空间关系。
已有的研究表明,图注意网络(GAT)[38]通过自适应学习邻接矩阵来捕获邻域的影响是相当有效的。在这个作品中,EGAT不仅学习了邻接矩阵,还整合了行人的几何关系。为此,我们采用双随机邻接矩阵(DSM)作为注意图网络的输入邻接矩阵。
DSM具有很多不错的特性,例如具有最大特征值1的对称正半定性,这有助于稳定图卷积过程[12]来捕获空间相互作用。此外,我们注意到,行人更有可能受到其自身历史轨迹和邻近行人的影响。
因此,在归一化为DSM之前,我们首先构建初步的对称邻接矩阵,以通过计算行人之间的几何距离并为每个行人引入自连接来捕获行人之间的原始空间关系:

其中d(vt i,vt j)是在时间步长t行人i与行人j之间的欧式距离。然后,可以如下生成DSM:
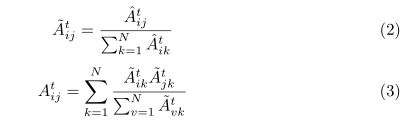
然后,利用DSM邻接矩阵的边缘特征来指导图形关注层中的关注操作[38]。具体而言,中间节点特征是通过以下嵌入和聚合功能获得的:
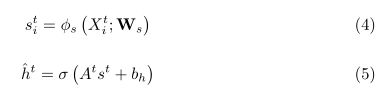
其中,函数,![]() 为嵌入函数,
为嵌入函数,![]() 为嵌入权重,而
为嵌入权重,而![]() 为LeakyReLU激活。然后得到时间步t下行人i的节点特征
为LeakyReLU激活。然后得到时间步t下行人i的节点特征![]() ,其中F1为节点特征的数量。新节点特征嵌入基于DSM聚合原始节点特征,将原始节点特征送入图注意层[38]中捕捉空间交互:
,其中F1为节点特征的数量。新节点特征嵌入基于DSM聚合原始节点特征,将原始节点特征送入图注意层[38]中捕捉空间交互:
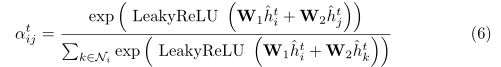
其中![]() 通过自我关注机制动态计算邻居j对行人i的重要权重。图注意力层可以学习一个自适应邻接矩阵,该矩阵捕获不同节点的相对重要性。为了稳定自我注意过程[38,43],采用了多头注意:
通过自我关注机制动态计算邻居j对行人i的重要权重。图注意力层可以学习一个自适应邻接矩阵,该矩阵捕获不同节点的相对重要性。为了稳定自我注意过程[38,43],采用了多头注意:
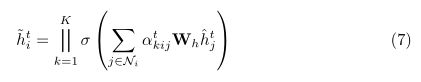
其中,![]() 为LeakyReLU激活,||是串联的,并且k索引第k个关注头。然后得到
为LeakyReLU激活,||是串联的,并且k索引第k个关注头。然后得到![]() 的最终节点特征,其中
的最终节点特征,其中![]() 捕捉了行人i与其相邻行人在每个时间步上的聚集空间互动。
捕捉了行人i与其相邻行人在每个时间步上的聚集空间互动。
3.4. TCN-based Spatial and Temporal Interaction Representation(基于TCN的时空交互表示)
总结:
输入:EGAT模块获得的空间嵌入和方程8获得的时间上下文嵌入作为TCN模块的输入:
输出:空间和时间的相互作用
行人的运动方式受历史轨迹和邻近行人的运动方式的影响很大。受[27]的启发,我们建议使用改进的时间卷积网络(TCN)来捕获行人之间的时空交互,如图2所示。具体地说,TCN模块采用了因果卷积,即一维卷积输入,并通过对因果卷积层进行放样,可以获得TCN的最终输出,该输出捕获空间和时间上的相互作用。
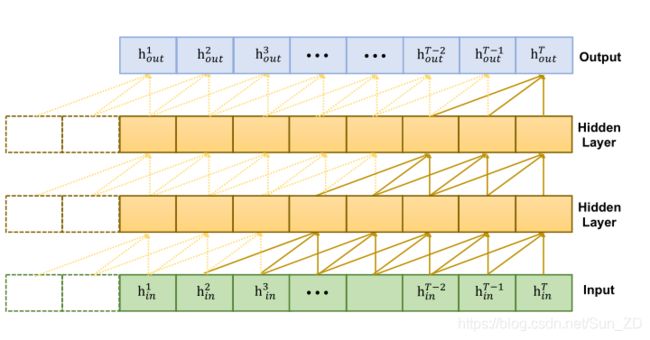
该网络可以看作是短期和长期编码器,其中较低的卷积层专注于局部短期相互作用,而在较高的层中,长期相互作用是通过较大的接收场捕获的。例如,如果TCN的内核大小为k,则第l层的接收场大小为(k -1)·l +1,其线性上升层增加。因此,TCN的顶层捕获了较长时间范围内的交互。由于输入的顺序在序列预测任务中很重要,因此我们对因果卷积采用大小为k − 1的左填充,而不是对称填充,其中每个卷积输出在相应的时间步长上对输入进行卷积。前面的k-1步骤也是如此。这样,每个因果卷积的输出大小都与输入相同。
为了融合跨时间步长的空间和时间交互,我们首先将EGAT模块获得的空间嵌入和方程8获得的时间上下文嵌入作为TCN模块的输入:
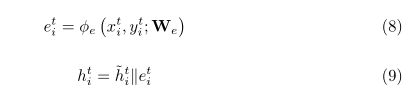
其中xt i和yt分别为行人i在第t个时间步处与其第一个时间步处和前一个时间步处的相对位置,为嵌入函数,k为连接操作,h = {h1, h2,…, hi RTobs F2。然后,每个核大小为k的因果卷积对空间和时间的相互作用进行卷积。门控功能在[27,7]中显示了捕获时间信息的强大能力。它利用两个非线性函数来控制旁路信号。因此,我们采用类似的门控激活单元来动态调节所形成的信息流
![]()
![]() 为tanh激活函数,令
为tanh激活函数,令![]() 为sigmoid函数,
为sigmoid函数,![]() 表示元素方向的乘法,Wg和Wf分别为可学习的一维卷积参数。然后,将h(L)跨时间维连接起来,得到TCN模块的最终输出,记为
表示元素方向的乘法,Wg和Wf分别为可学习的一维卷积参数。然后,将h(L)跨时间维连接起来,得到TCN模块的最终输出,记为![]() 。通过这种方式,嵌入向量反映了第i个行人与其邻居之间的时空相互作用。我们注意到,TCN可以用扩张卷积[27]处理更长的输入序列,这比基于rnn的方法更有效。
。通过这种方式,嵌入向量反映了第i个行人与其邻居之间的时空相互作用。我们注意到,TCN可以用扩张卷积[27]处理更长的输入序列,这比基于rnn的方法更有效。
3.5 Future Trajectory Prediction(未来轨迹预测)
在现实应用中,给定历史轨迹,未来运动有多种可能的方式。因此,我们也在我们的解码器模块中为最终运动的不确定性建模,用于轨迹预测。在广泛采用的多模态策略[14,24,19]的基础上,解码器模块通过引入随机噪声作为输入的一部分,产生多个社会可接受的轨迹则解码器所有行人到上一步的相对位置为:
![]()
其中![]() ,
,![]() (·)是一个LeakyReLU非线性的多层感知器,z是从N(0,1)中采样的随机噪声向量,Wzis是感知器的权值。然后我们将相对位置转换为绝对位置Y,并采用品种损失作为训练的损失函数,计算M条似是而非的轨迹中的最小ADE损失
(·)是一个LeakyReLU非线性的多层感知器,z是从N(0,1)中采样的随机噪声向量,Wzis是感知器的权值。然后我们将相对位置转换为绝对位置Y,并采用品种损失作为训练的损失函数,计算M条似是而非的轨迹中的最小ADE损失
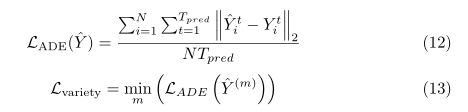
其中Y为ground truth, Y(1),…, Y(M)是预测的M条似是而非的轨迹。虽然这个损失函数可能导致一个稀释的概率密度函数[36],我们经验地发现,它有助于更好地预测多个未来轨迹。
4 实验
遵循约定[1,14,39,24],我们在两个轨迹预测基准数据集ETH [29]和UCY [23]上评估GraphTCN,并使用最新方法比较GraphTCN的性能。
Datasets ETH和UCY数据集中的带注释的轨迹作为全局坐标提供。在这些数据集中,行人表现出复杂的行为,包括非线性轨迹,从不同方向移动,一起行走,不可预测地行走,避免碰撞,站立等。这些数据集包括从固定的俯视图记录的五个独特的室外环境。 ETH和Hotel属于ETH数据集,而UCY数据集由UNIV,ZARA1和ZARA2组成。每个环境中单个场景的人群密度是不同的,每帧的行人密度在0到51之间。所有视频的每秒帧数(FPS)为25,行人轨迹以2.5 FPS提取。
Implementation Details 我们训练Adam优化与学习率0.0003, 50 epochs。Ws的嵌入大小设置为16。EGAT模块包括F1= 16和K = 4,2个注意层,第一图注意层和第二图注意层分别有1个attention heads。EGAT的最后一个节点特征的维数是16,而我们的维数是32。![]() 由3层组成,M设为20层。所有 LeakyReLU的斜率都是-0.2。
由3层组成,M设为20层。所有 LeakyReLU的斜率都是-0.2。
Evaluation Metrics(评价指标) 根据报告惯例[1,14,24],采用的评估指标包括平均位移误差(ADE)和最终位移误差(FDE)。方程12中定义了ADE,它是预测轨迹和地面真实总预测时间步长之间的平均欧几里得距离,而FDE是预测位置和最终时间步长Tpred处地面真实位置之间的欧几里得距离。该模型采用“留一法”策略进行训练,并相应地报告结果。根据3.2秒(即8个时间步长)的观察结果,在接下来的4.8秒(即12个时间步长)中产生预测。
Baselines 我们将我们的框架与以下基线方法进行比较:
Linear是一种线性回归模型,可以根据上一个输入点预测下一个坐标。
LSTM采用vanilla LSTM编解码器模型来预测每个行人的顺序。
Social LSTM [1]建立在LSTM之上,并引入了一个社交池层来捕获行人之间的空间互动。
我们进一步将GraphTCN与三种最先进的方法进行比较:
Social GAN [14]在Social LSTM和社交生成GAN的基础上进行了改进,以生成多个合理的轨迹。
Social Attention[39]为STGNN采用RNN混合模型来捕获空间互动和时间动态。
STGAT [19]还采用GAT对空间信息进行建模,并采用LSTM捕获时间相互作用。
4.1. Quantitive Analysis
Overall Results 我们将GraphTCN与表1中的最新基准进行了比较。结果表明,与这些基准数据集上的现有模型相比,GraphTCN始终具有更好的性能。具体来说,我们的GraphTCN的ADE和FDE平均达到0.34和0.57。特别是,与以前的最佳性能模型STGAT相比,GraphTCN分别平均平均降低了20.9%的ADE和31.3%的FDE。这些结果证实了我们的GraphTCN在预测准确性方面明显优于以前的方法,尤其是在更复杂的数据集ZARA1和ZARA2上。
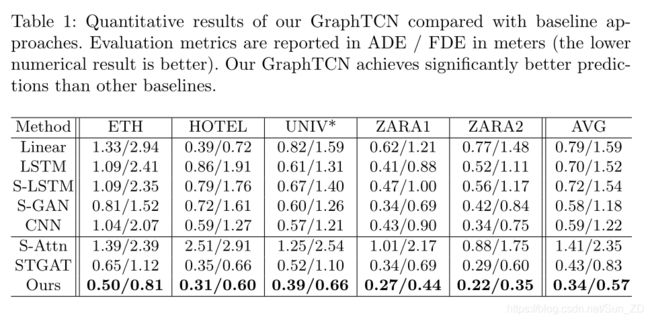
Speed Comparison 我们比较了GraphTCN与基线模型(Social GAN [14], Social Attention [39], STGAT[19])的推理速度。表2中的结果报告了模型推理时间和加速因子与社会注意[39]在相同数据集上的时钟秒的比较。从结果中我们可以看到,与这些基线方法相比,GraphTCN实现了更快的推断。特别是,GraphTCN需要0.81秒的推断时间,比Social-GAN和最类似的之前方法STGAT分别快1.32和5.37。

4.2. Qualitative Evaluation
我们还通过可视化和比较预测的轨迹与图3中性能最佳的STGAT来研究GraphTCN的预测结果。我们选择发生复杂相互作用的三种独特情况。复杂的交互包括行人站立,行人合并,行人跟随,行人躲避等。
从图3(a)中,我们可以观察到GraphTCN在固定行人上具有更好的性能。具体而言,由GraphTCN生成的轨迹遵循与地面真实情况相同的方向,而来自STGAT的预测则明显偏离路径。
图3(b)显示,当行人来自不同的群体时,STGAT可能无法做出令人满意的预测,而GraphTCN在一个行人遇到另一群体的情况下给出了更好的预测。
图3(c)证明了当行人从某个角度合并到同一方向时,GraphTCN可以成功地产生预测,从而避免将来发生碰撞。这些定性结果进一步证实,我们的GraphTCN可以产生更好的轨迹预测,这在复杂的现实世界场景中对于固定的行人和行进的人群都具有社会意义。

我们还在图4中展示了三种不同情况下在实际仪表中绘制的成功预测轨迹。
在图4 (a)中可以看到更具挑战性的场景,行人8只移动很短的距离,行人6、7几乎是静止的,行人5单独移动,两组行人(1,2,3,4)试图避免碰撞。从结果中我们可以观察到,我们的GraphTCN为行人6、7和8生成了可信的短轨迹,而行人5不受其他行人的影响。此外,行人1、2和3、4分组移动,未来的道路不会碰撞。
在图4 (b)中,两个行人3和4作为一组一起移动,我们的GraphTCN可以捕捉他们的组运动模式,并做出准确的组轨迹预测。即使在更复杂的场景中。
更多的行人出现在图4 ©中,我们的GraphTCN也会产生社会可接受的预测,即当他们朝相反的方向出发(行人3和1,2,7)或朝相同的方向相遇(行人8和4,5,6)。
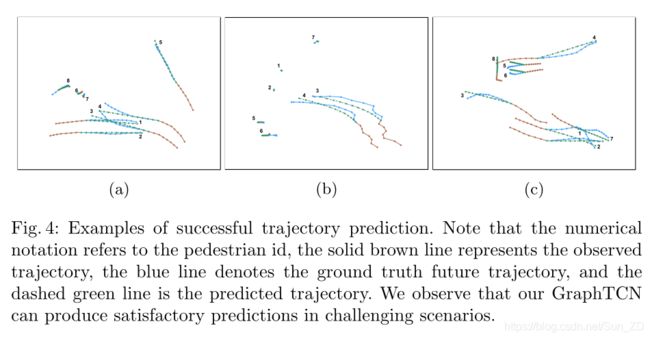
图5显示了GraphTCN的三种失败情况。
在图5(a)中,我们注意到,尽管我们的模型可以生成与地面真相具有相同方向的预测,但是到达最终点后,我们的预测轨迹会超调。原因可能是我们的模型同时预测了所有轨迹,这导致模型难以对那些高速历史轨迹进行低速预测。
图5(b)表明,当过去的轨迹接近线性时,我们的模型可能会产生线性的未来轨迹。
在图5(c)中,行人2、3和4的预测路径失败。这是因为与他们的未来路径相比,观察到的轨迹相对较短,并且行人具有一些不可预测的行为,这从本质上来说是一项具有挑战性的任务。

5 结论
在本文中,我们提出了GraphTCN进行轨迹预测,通过使用EGAT对行人的空间相互作用进行建模,并通过TCN对行人的空间和时间相互作用进行建模,从而有效地捕获了行人之间的时空相互作用。所提出的GraphTCN完全基于前馈网络,与现有解决方案相比,前馈网络在训练过程中更易于处理,更重要的是,其预测精度显着提高,推理速度更高。在长轨迹预测的情况下,GraphTCN的优势更加明显。实验结果证实,我们的GraphTCN在所有采用的基准数据集上均优于最新方法。