Python 科学计算库 — Pandas 基本数据结构:Series 和 DataFrame
导入Pandas模块:import pandas as pd
Panda有两种数据结构,分别是Series 和DataFrame。
- Series:类似于一维数组的对象,是由一组数据(各种NumPy数据类型)及一组与之相关的数据标签(索引)组成。仅由一组数据也可产生Series 对象。注意:Series 中的索引值是可以重复的。
- DataFrame:表格型的数据结构,由一组有序的列组成,每列可以是不同的数据类型(数值、字符串、布尔型等)。DataFrame 既有行索引,也有列索引,可以看作是Series 组成的字典。
一、Series
1、Series 创建方法
通过一维数组、列表、字典创建
pd.Series(value, index=[], dtype=...) # index 默认从0 到n-1
- value:可以是一维数组、列表、字典等。
- index:索引列,默认从0到n-1
# 1、通过一维数组创建
arr = np.array([1,5,8])
ser01 = pd.Series(arr)
# 2、直接通过列表创建
ser02 = pd.Series([2, 6, 8, 4])
# 3、使用字典创建: 字典的key 作为索引
dic = {'语文':93,'数学':88,'英语':90}
ser03 = pd.Series(dic)
输出:
0 1
1 5
2 8
dtype: int32
0 2
1 6
2 8
3 4
dtype: int64
数学 88
英语 90
语文 93
dtype: int64
# 1、创建时指定index
ser1 = pd.Series([26, 25, 28], index = ['Arthur', 'Selina', 'Tom'])
dic = {'语文':93,'数学':88,'英语':90}
ser2 = pd.Series(dic)
# 2、修改index
ser2.index = ['化学', '物理', '历史']
输出:
Arthur 26
Selina 25
Tom 28
dtype: int64
化学 88
物理 90
历史 93
dtype: int64
2、Series 属性及方法
| 编号 | 属性/方法 | 描述 |
|---|---|---|
| 1 | axes | 返回行标签列表,即索引列组成的列表 |
| 2 | dtype | 返回对象的数据类型 |
| 3 | empty | 判空,如果Series对象为空,返回True |
| 4 | ndim | 返回底层数据的维数,默认定义为1 |
| 5 | size | 返回基础数据中的元素个数 |
| 6 | values | 将Series 对象作为ndarray 返回 |
| 7 | head(n) | 返回前n行 |
| 8 | tail(n) | 返回最后n行 |
classes = ['语文', '数学', '英语']
score = [98, 95, 90]
ser = pd.Series(score, index = classes)
ser # 输出ser
ser.axes # 返回行标签列表
ser.values # 返回ndarray对象
输出:
语文 98
数学 95
英语 90
dtype: int64
[Index([‘语文’, ‘数学’, ‘英语’], dtype=‘object’)]
array([98, 95, 90], dtype=int64)
3、Series 值的获取
Series 值的获取主要有两种方式:
- 方括号 + 索引:
ser['语文'] - 方括号 + 下标:
ser[2]
1、以上两种方式都可以获取一个或多个数据,获取多个数据时,索引或标签用列表表示,如ser[[0, 3]], ser[['数学', '体育']]。
2、通过索引获取,当索引有重复数据时,相同索引的数据都会被获取到。
classes = ['语文', '数学', '英语', '体育', '数学']
score = [98, 95, 90, 92, 100]
ser = pd.Series(score, index = classes)
# 1、通过索引标签获取一个或多个数据:多个数据的索引用列表表示
print("通过索引获取数学的成绩:", ser['数学']) # 会获取所有的数学成绩
print("通过索引获取数学和体育的成绩:\n", ser[['数学', '体育']])
# 2、通过下标获取一个或多个数据:多个数据的下标用列表表示
print("通过下标获取英语的成绩:", ser[2]) # 下标取值:[0, len-1]
print("通过下标获取数学和体育的成绩:\n", ser[[1, 3]])
# 3、head(n): 获取前n 行的数据
print("获取前两门课的成绩:\n", ser.head(2))
# 4、tail(n): 获取后n 行的数据
print("获取后两门课的成绩:\n", ser.tail(2))
输出:
通过索引获取数学的成绩: 数学 95
数学 100
dtype: int64
通过索引获取数学和体育的成绩:
数学 95
数学 100
体育 92
dtype: int64
通过下标获取英语的成绩: 90
通过下标获取数学和体育的成绩:
数学 95
体育 92
dtype: int64
获取前两门课的成绩:
语文 98
数学 95
dtype: int64
获取后两门课的成绩:
体育 92
数学 100
dtype: int64
切片
1、既可以切索引,也可以切下标。
两者的区别:通过下标切片-前闭后开;通过索引切片-前闭后闭!
2、切片时若边界是重复索引,则会报错。
# 5、切片:既可以切索引,也可以切下标
classes = ['语文', '数学', '英语', '体育', '数学']
score = [98, 95, 90, 92, 100]
ser = pd.Series(score, index = classes)
print("通过下标进行切片:\n", ser[0:2]) # 取不到下标为2的数据
print("通过索引进行切片:\n", ser['语文':'英语']) # 能取到英语的成绩
print("通过索引进行切片:\n", ser['语文':'数学'])
输出结果:
通过下标进行切片:
语文 98
数学 95
dtype: int64
通过索引进行切片:
语文 98
数学 95
英语 90
dtype: int64
KeyError: “Cannot get right slice bound for non-unique label: ‘数学’”
4、Series 的运算
Series 完全保留了NumPy 中的数组运算,Series 进行运算时,索引与值之间的映射关系不会改变。
在操作Series 时,基本上可以把Series 看成NumPy 中的ndarray数组进行操作,ndarray 的绝大多数操作和方法都可以直接应用到Series 对象上。
arr1 = np.array([1, 4, 9])
arr2 = np.array([10, 11, 12])
ser1 = pd.Series(arr1)
ser2 = pd.Series(arr2)
# 1、Series 与标量进行运算
print("Series 与标量进行运算:\n", ser1 + 10)
# 2、Series 与Series进行运算
print("Series 与Series 进行运算:\n", ser1 + ser2)
# 3、ndarray 的通用函数:sqrt,log,mod...
print("求平方根:\n", np.sqrt(ser1))
print("取对数:\n", np.log(ser1).round(3))
print("点积:", np.dot(ser1, ser2))
输出结果:
Series 与标量进行运算:
0 11
1 14
2 19
dtype: int32
Series 与Series 进行运算:
0 11
1 15
2 21
dtype: int32
求平方根:
0 1.0
1 2.0
2 3.0
dtype: float64
取对数:
0 0.000
1 1.386
2 2.197
dtype: float64
点积: 162
Series 自动对齐
- 自动对齐:两个Series 运算时,是根据索引index 进行运算,即相同索引的数据进行运算,与元素位置无关。如果index 不存在,返回NaN。
- 两个数组运算时,是根据元素的坐标位置进行运算:相同位置的数据进行运算。如果数组维度不同,则无法进行运算。
class1 = ['语文', '数学', '英语']
class2 = ['数学', '英语', '语文', '体育']
score1 = [91, 92, 93]
score2 = [80, 85, 100, 88]
ser1 = pd.Series(score1, index = class1)
ser2 = pd.Series(score2, index = class2)
print("ser1 + ser2:\n", ser1 + ser2)
输出结果:
ser1 + ser2:
体育 NaN
数学 172.0
英语 178.0
语文 191.0
dtype: float64
5、Series 缺失值检测
缺失值:一般用NaN(Not a Number)表示。
Pandas 中的缺失值检测函数有两个:isnull 和 notnull,两个函数的返回值都是一个布尔类型的Series 对象。
pd.isnull(ser):若索引对应的数据是缺失值,则返回True;否则返回False。也可以用pd.isna(ser)。pd.notnull(ser):若索引对应的数据不是缺失值,则返回True;否则返回False。
score = np.array([92, np.NAN, 100, np.Inf])
classes = ['数学', '语文', '英语', '体育']
ser = pd.Series(score, index = classes)
print("isnull 返回值:\n", pd.isnull(ser))
print("isna 返回值:\n", pd.isna(ser))
print("notnull 返回值:\n", pd.notnull(ser))
输出结果:
isnull 返回值:
数学 False
语文 True
英语 False
体育 False
dtype: bool
isna 返回值:
数学 False
语文 True
英语 False
体育 False
dtype: bool
notnull 返回值:
数学 True
语文 False
英语 True
体育 True
dtype: bool
二、DataFrame
数据帧(DataFrame)是二位数据结构,数据以行和列的表格方式排列。
数据帧的功能特点:潜在的列是不同的类型;大小可变;标记轴(行和列);可以对行和列进行算术运算。
DataFrame 创建
DataFrame 对象创建方法:
panda.DataFrame( data=None, index=None, columns=None, dtype=None, copy=False)
- data:用于创建DataFrame 对象的数据,可以是以下形式:ndarray,Series,List,dictionary,Constant 和DataFrame。
- index:行标签,默认是[0, n-1]
- columns:列标签,默认是[0, n-1]。通过字典创建对象时,字典的key 作为列索引。
- dtype:每一列的数据类型
- copy:默认为False,表示用于复制数据;如果为True,则操作会改变元数据。
一般只给定data,index 和columns 3个参数,其它默认。

# 1、通过列表创建
classes = ['语文', '数学', '英语']
names = ['Arthur', 'Selina']
scores = [[80, 85, 88], [92, 96, 99]]
df = pd.DataFrame(scores, index = names, columns = classes)
# 2、通过字典创建
dic = {'语文':[80, 92], '数学':[85, 96], '英语':[88, 99]}
df2 = pd.DataFrame(dic, index = names)
以上两种方法创建的对象是一样的,如下:

DataFrame 数据操作:增删改查
1、查找数据
查找返回的数据都是Series 对象。
-
获取指定列的数据:直接通过列索引,
df[‘数学’] -
获取指定行的数据:loc,iloc,ix
- loc:通过行标签获取行数据,
df.loc['Arthur'] - iloc:通过行号获取行数据,
df.iloc[1] - ix:通过行标签或者行号获取,基于loc 和iloc 的混合。
- loc:通过行标签获取行数据,
-
获取多行或多列数据:用列表表示,
df.loc['Arthur', 'Selina'] -
获取指定行指定列的数据:
df.loc['Selina', '数学'] -
行切片:既可以通过行索引,也可以通过行号进行切片。
注意:通过索引,前闭后闭;通过行号,前闭后开!
# 1、获取指定行或指定列的数据
print("获取数学列的数据:\n", df['数学'])
print("获取Selina行的数据:\n", df.loc['Selina'])
# 2、获取多行或多列数据
print("获取数学和英语列的数据:\n", df[['数学', '英语']])
# 3、获取指定行指定列的数据
print("获取Selina的数学和英语成绩:\n", df.loc['Selina', ['数学', '英语']])
# 4、行切片
# print("获取第0行到最后一行的数据:\n", df.iloc[0:])
print("获取从Arthur到Selina所有行的数据:\n", df.loc['Arthur':'Selina'])
print("获取语文和数学两列数据:\n", df[['语文', '数学']])
输出结果:
获取数学列的数据:
Arthur 85
Selina 96
Name: 数学, dtype: int64
获取Selina行的数据:
语文 92
数学 96
英语 99
Name: Selina, dtype: int64
获取数学和英语列的数据:
数学 英语
Arthur 85 88
Selina 96 99
获取Selina的数学和英语成绩:
数学 96
英语 99
Name: Selina, dtype: int64
获取从Arthur到Selina所有行的数据:
语文 数学 英语
Arthur 80 85 88
Selina 92 96 99
获取语文和数学两列数据:
语文 数学
Arthur 80 85
Selina 92 96
2、增加和修改数据:直接赋值
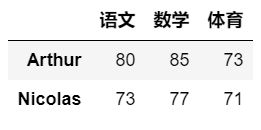
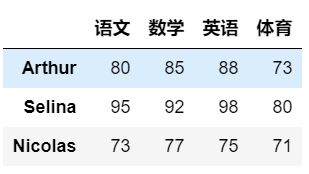
# 增加一行数据
df.loc['Nicolas'] = [73, 77, 75]
# 增加一列数据
df['体育'] = [63, 65, 61]
# 修改行数据
df.loc['Selina'] = [95, 92, 98, 70]
# 修改列数据
df['体育'] = [73, 80, 71]
以下分别是增加和修改之后的输出结果:

3、删除数据
- 删除行:drop() 方法,返回删除指定行后的DataFrame。
- 删除列:pop() 方法,返回删除后的Series;del 语句,直接对原对象进行操作。
# 删除行
df1 = df.drop('Selina') # 返回DataFrame
# 删除列
# ser = df.pop('英语') # 返回Series
del (df1['英语']) # 对原对象进行修改
输出结果: