CUDA: (七) Histogram Calculation(GPU vs CPU), Atomic Operations
Atomic Operation
什么叫Atomic operation(原子操作)呢?或者说在什么情况下我们需要进行Atomic operation呢?
考虑一种情况,我们会经常出现这样一个问题,例如有大量的线程尝试修改少量内存,或者当我们尝试执行读取-修改-写入操作时,将会产生更多的问题,例如加一操作,当多个线程在同一内存位置上执行此操作时,可能会给出错误的输出。
举个实际例子:
假设一个内存位置的初始值为6,并且线程p和q试图增加该内存位置,那么最终答案应为8。但是在执行时,可能会同时读取p和q线程同时获得该值,则两者都将获得值6。他们将其增加到7,并且两者都将把这个7存储在内存中。因此,我们的最终结果不是8而是7,这是错误的。
再举个例子:
以ATM取现为例,假设你的帐户中有5,000人民币并且有两个具有相同帐户的ATM卡。你和朋友同时前往两个不同的ATM机提取4,000人民币。你们两个同时刷卡;因此,当ATM检查余额,则两者都会显示5,000元。当你们俩都取走4,000元,那么两台机器都将查看初始余额,即5,000元。提款金额少于余额,因此两台机器都会给4,000元。即使你的余额为5,000元,也可以获得8,000元,这是危险的。
那么我们就来看下代码吧,首先我们先不使用 automic operation的核函数:
__global__ void histogram_without_atomic(int *d_b, int *d_a){
int tid = threadIdx.x + blockDim.x*blockIdx.x;
int item = d_a[tid];
if(tid<SIZE){
d_b[item]++;
}
}
初始化一个数组,长度为10000,有0-255这256个数,按照计算应该是有部分数字(0-15)有40个,有部分数字(16-255)有39个,但实际上却如下所示:
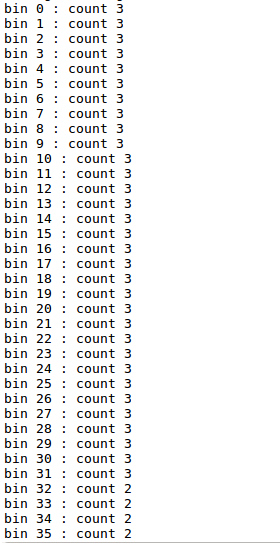
所以说我们需要使用automic operation,等一个线程成功写入到内存后,另一个线程再进行修改,但是这样也会存在一个问题,就是速度变慢,因为线程之间存在等待。
使用automic operation的核函数
__global__ void histogram_atomic(int *d_b, int *d_a){
int tid = threadIdx.x + blockDim.x * blockIdx.x;
int item = d_a[tid];
if(tid < SIZE){
atomicAdd(&(d_b[item]), 1);
}
}
输出结果如下所示:
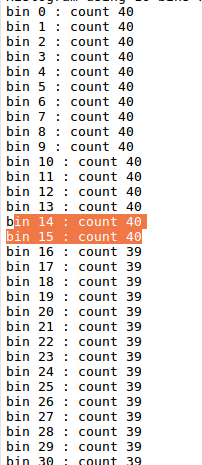
使用shared memory的核函数:
__global__ void histogram_shared_memory(int *d_b, int *d_a){
int tid = threadIdx.x + blockDim.x*blockIdx.x;
int offset = blockDim.x*gridDim.x;
__shared__ int cache[NUM_BIN];
cache[threadIdx.x] = 0;
__syncthreads();
while(tid < SIZE){
atomicAdd(&(cache[d_a[tid]]), 1);
tid += offset;
}
__syncthreads();
atomicAdd(&(d_b[threadIdx.x]), cache[threadIdx.x]);
}
按理说使用shared memory速度会更加快,但是这个数据量并不是很明显
下面贴出完整代码
#include 参考书籍:
- Hands-On GPU-Accelerated Computer Vision with OpenCV and CUDA
PS:
24426,这不仅仅是个数字,是一个个活生生的人,希望他们都能早日康复,只有失去才知道珍惜,现在希望疫情早点结束,能够不戴口罩,在马路上肆无忌惮的走着就行!


武汉加油!湖北加油!中国加油!↖(ω)↗