【OS学习笔记】十 实模式:实现一个程序加载器-程序加载器如何将用户程序加载到内存并执行
上一篇文章学习了以下内容:
- 用一种不同的分段方法,从另一个不同的的角度理解处理器的分段内存访问机制
- 使用循环和条件转移指令来优化主引导扇区代码
点击链接查看上一篇文章:点击链接查看
对于主引导扇区部分。大概前几篇文章已经学的差不多了。现在是时候跳过主引导扇区去学习其他部分内容。本篇文章记录学习以下内容:
- 学习操作系统加载应用程序的过程,演示段的重定位方法,最终彻底理解8086的分段内存管理机制
- 深入理解程序的加载与段地址的重定位过程
- 学习X86处理器过程调用的程序执行机制
1、主引导扇区过后是什么
主引导扇区是处理器迈向广阔天地的第一块跳板。离开主引导扇区后,前方通常就是操作系统。
和主引导扇区一样,操作系统也是位于硬盘上的。操作系统需要安装到硬盘上。这个安装的过程不仅需要将操作系统的指令和数据写入硬盘,通常还要更新主引导扇区的内容。好让主引导扇区直接连着操作系统。
我们前面写的主引导扇区一直都是在显示字符串和做加法。这这太过简单。不过作为初学,很有必要。
操作系统通常肩负着处理器管理、内存分配、程序加载、进程调度等的任务。想要自己写一个操作系统,还是相当困难的。但是我们可以模拟一下操作系统的一些功能,写一个小程序。比如,我们可以模拟操作系统加载用户程序到内存的这一过程。
我们知道编译好的程序通常都是存放在硬盘这样的载体上,需要加载到内存之后才能运行。这个过程很复杂。首先需要读取硬盘,然后决定把它加载到内存的什么位置。最重要的是程序通常都是分段的,载入内存之后,还需要重新计算它的段地址。这叫做段的重定位。
那么本篇文章目的就是:把主引导扇区改造成一个加载器程序,它的功能是加载用户程序,并执行该程序(将处理器的控制权交给用户程序)。
说明:参考的原书X86汇编在这里讲了很多如何从硬盘读数据这种太底层的操作。对于一个只是想了解底层原理的应用程序开发人员不必过多了解对硬件的操作。所以我对硬件的操作极其简单的一笔概括(本人是Java后台开发工作)。想要深入理解硬件的操作请参考原书籍。
2、代码清单
本篇文章的汇编代码较多。加载程序有150行,而用户程序也达到了行。
所以本文不直接贴代码。而是在讲解的时候分段贴出代码。整个书本的代码我上传到CSDN资源。点击下载观看:点击下载
本文的代码是
- 8-1 (主引导扇区程序/加载器),源程序文件:c08_mbr.asm
- 8-2(被加载的用户程序),源程序文件:c08.asm
3、分析
3.1 用户程序的结构(代码8-2)
3.11 整体结构
处理器的工作模式是将内存分成逻辑上的段。指令的获取和数据的访问一律按“段地址:偏移地址”的方式进行访问。相对应的,一个规范的应用程序,应当包含代码段、数据段、附加段和栈段。
这样一来,段的划分和段与段之间的界限在程序加载到内存之前就已经划分好了。
还记得在前几篇文章中我们写的主引导扇区程序的汇编代码,都是整个程序作为一个分段。这样导致数据段与代码段都是重合的。这样很容易出错。所以今天我们的用户程序,就不会只有一个段。而是采用多个段来写。
我们先用以下图示来给出一个合格的程序应该有哪些段。
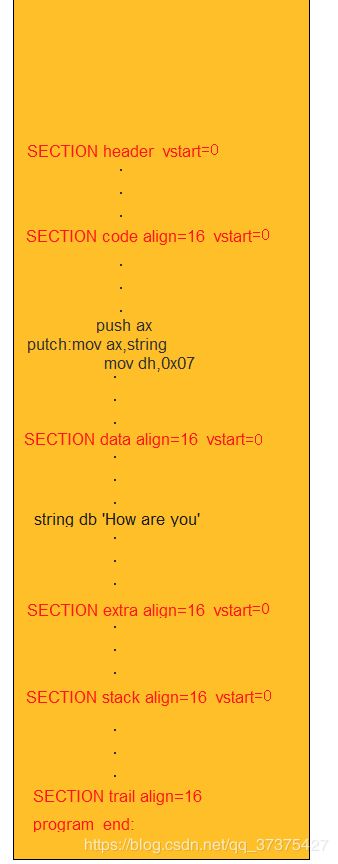
NASM编译器使用汇编指令“SECTION”或者“SEGMENT”来定义段。align用于指定段的对其方式。vstart用于指定在在某一个段内的指令的汇编地址是从该段所在的段头开始计算而不是从程序的最开始的头开始计算。
所以可以看出图中"program_end:"这个标号的汇编地址是从程序的开头开始计算的。所以program_end可以代表整个程序的长度。
由图中可以看出一个合格的程序大概需要有这些段:分别是header code data extra stack trail
我们再前面的文章中,也学习了代码段,数据段,栈段,附加段。trail段很好理解,一般在结尾给一个标号用于代表整个程序的长度的。
段的汇编地址其实就是段内的第一个元素的汇编地址。
可以用如下方法得到段的汇编地址:
section.段名称.start
3.12 用户程序的头结构
上面大概知道了我们用户程序的整体分段结构。浏览一下本章的代码8-2,我们会发现我们的用户程序一共定义了7个段,分别是:第7行定义的header段,27行定义的code_1段,163行定义的code_2段,173行定义的data_1段,194行定义的data_2段,201行定义的stack段和208行定义的trail段。
一般情况下,加载器程序和用户程序是由不同的公司不同的人开发的。所以加载器与用户程序实际上彼此并不知道彼此长什么样。他们并不了解彼此的结构与功能。
那么加载器该如何加载用户程序呢?
首先用户程序中必须得有一些信息,加载器可以利用这些信息将用户程序加载到内存中去。
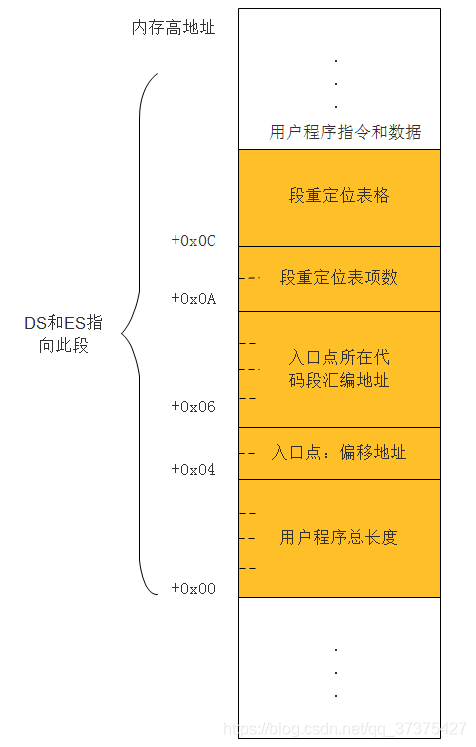
实际上在用户程序中,有这么一个段,叫做头部。它里面包含了一些重要的信息,加载器利用这些信息足以将用户程序加载到内存中进行运行。顾名思义,头部,在用户程序的开头位置。如下图:
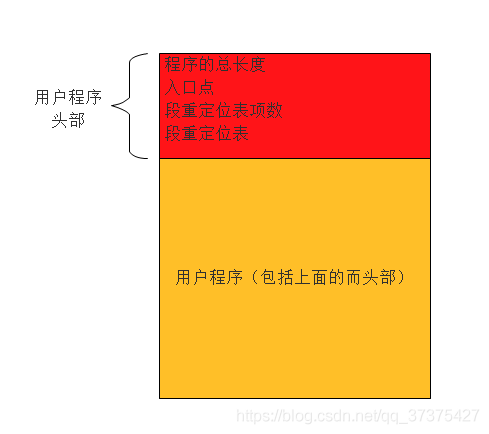
用户程序为了能够让加载器将自己加载到内存中去,必须包含以下介个方面:
- 用户程序的尺寸,即以字节为单位的大小
- 应用程序的入口点,包括段地址和偏移地址
- 段重定位表以及每个表的表项。因为用户程序一般不止一个段,比较大的程序可能包含多个代码段和数据段。在程序没有加载进内存之前,各个段都有自己的段地址(即汇编地址),但是程序加载进内存之后,一般来说加载到哪个内存地址是不知道的,所以说此时各个段的实际内存地址肯定变了,所以此时需要对段进行重定位。
以下是我们的用户程序8-2中的头部代码:
SECTION header vstart=0 ;定义用户程序头部段
program_length dd program_end ;程序总长度[0x00]
;用户程序入口点
code_entry dw start ;偏移地址[0x04]
dd section.code_1.start ;段地址[0x06]
realloc_tbl_len dw (header_end-code_1_segment)/4
;段重定位表项个数[0x0a]
;段重定位表
code_1_segment dd section.code_1.start ;[0x0c]
code_2_segment dd section.code_2.start ;[0x10]
data_1_segment dd section.data_1.start ;[0x14]
data_2_segment dd section.data_2.start ;[0x18]
stack_segment dd section.stack.start ;[0x1c]
header_end:
注意:每段代码后面的[]括号,里面的值是当前行的汇编地址。
我们可以看到我们的用户程序头部中包含以下信息:
-
program_end代表程序的整个长度。因为在程序的最后一行如下图:

可以看到,program_end这个标号的汇编地址,就是整个程序的长度的大小。 -
程序的入口点的地址。包括段地址
section.code_1.start和偏移地址start。可以看到在段code_1中,有一个标号start。该程序就是从start处开始执行的。相当于程序的入口点。 -
段重定位表。可以看出,段重定位表项将各个段的汇编地址都记录在内,用于在加载到内存地址时的重定位工作。
trail段没有记录在内,是因为trail段只用于标识程序的结尾,从而标记程序的整个大小,并没有数据与指令可以给CPU执行。
我们知道了用户程序的大概分段以及用户程序的头部信息,就足以。
3.2 加载器的工作流程
上面的用户程序是8-2.现在我们的加载器程序是8-1.注意区分程序文件。
从大的角度来说,加载器要家在一个程序到内存中并使之执行,需要做两件事情:
- 看看内存中的什么位置是空闲的,即从哪个物理内存地址开始加载用户程序。
- 用户程序在硬盘上的什么位置,它的起始逻辑扇区号是多少。
那么我们的加载器应该将用户程序加载到什么位置呢?首先我们再来回顾一下整个的1M的内存空间的布局情况,如下图:
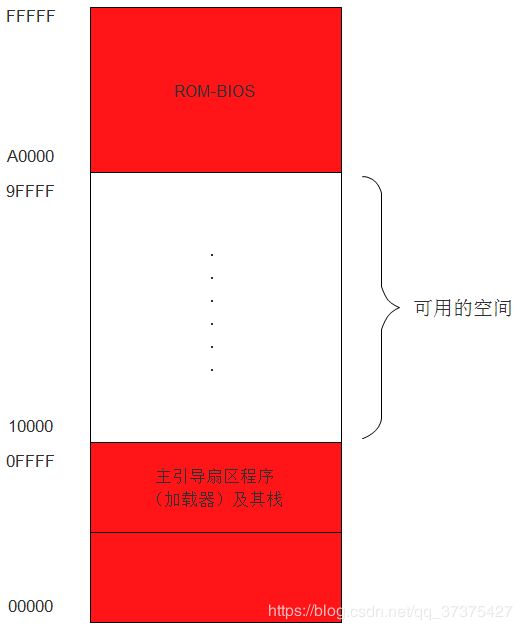
如图可知,我们可以在0x10000-0x9FFFF范围内加载用户程序。车不多500多KB。事实上,如果将低端的内存空间合理安排一下,还可以腾出更多空降,但是没必要,这里我们用不了那么多。
所以在这里我们将用户程序加载到0x10000这个物理地址处。在源程序(8-1)的151行有如下代码:phy_base dd 0x10000
3.21 准备加载用户程序(加载与重定位)
3.211、加载用户程序(从硬盘读)
我们已经知道了将用户程序加载到具体的物理地址的位置。接下来就可以加载了。
我们的主引导扇区程序(加载器程序)在这只定义了一个段:SECTION mbr align=16 vstart=0x7c00
vstart=0x7c00子句代表段内所有元素的汇编地址都将从0x7c00开始计算。否则,因为主引导扇区的实际加载地址是0x0000:0x7c00,当我们引用一个标号时还需要加上那个落差0x7c00.
代码清单8-1第12-14行:
mov ax,0
mov ss,ax
mov sp,ax
用于初始化栈段寄存器SS和栈指针寄存器SP。栈的段地址是0x0000,段的长度是64KB,栈指针将在段内0xFFFF-0x0000之间变化。
代码清单8-1第16-21行用于取得一个真实的物理地址。这个地址是用户程序的加载地址。并将DS和ES指向该地址的段地址,用于后期的操作。
mov ax,[cs:phy_base] ;计算用于加载用户程序的逻辑段地址
mov dx,[cs:phy_base+0x02]
mov bx,16
div bx
mov ds,ax ;令DS和ES指向该段以进行操作
mov es,ax
好了到目前为止。加载器已经准备好了一个状态。这个状态是它已经取得了用户程序的加载地址(真实的物理地址),并且用DS于ES来指向这个个地址的段地址,以方便后期的操作。
那么接下来,就是读取硬盘上的用户程序了。说白了就是访问其他硬件。那么我们对如何访问硬盘以及从硬盘上读取数据并不感兴趣。所以这里直接略过这部分的汇编代码的详细解说(感兴趣的话可以阅读原书籍内容)。
但是有一点内容可以说明,就是从硬盘上读数据不是一下子就能读完的。所以在这里,设置了一个过程调用,在需要读数据的时候直接调用相关的读书的汇编代码即可,不需要重复写读数据的代码。
处理器支持过程调用的指令机制。过程实际上就是一段普通的代码。处理器可以用过程调用指令转移到这段代码执行,然后再遇到过程返回指令时重新返回到调用出的下一条指令接着执行。
如下图是一个过程调用示意图:
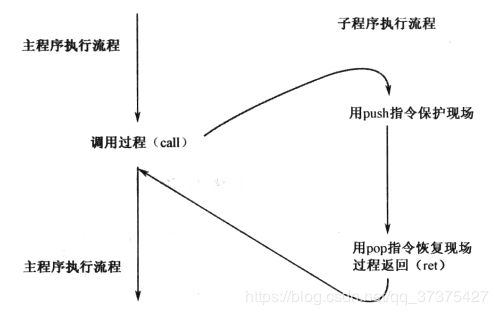
在调用其他过程之前,由于其他过程可能会使用一些寄存器,所以在这之前需要将这些寄存器的值先存起来,一般使用栈来保存这些值。在调用过程之后,再使用pop指令将之前保存过的寄存器的值在弹出来。
一般过程调用的指令是call指令。例如代码清单8-1中的24-27行就是用于读取程序的起始部分。
xor di,di
mov si,app_lba_start ;程序在硬盘上的起始逻辑扇区号
xor bx,bx ;加载到DS:0x0000处
call read_hard_disk_0
在read_hard_disk_0这个标号下的代码,首先需要push一些寄存器:
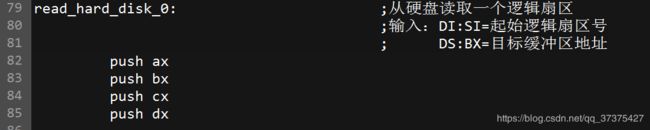
在最后的时候,将这些寄存器恢复:
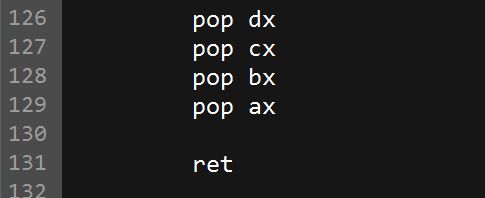
如下图所示是调用前后栈的变化:
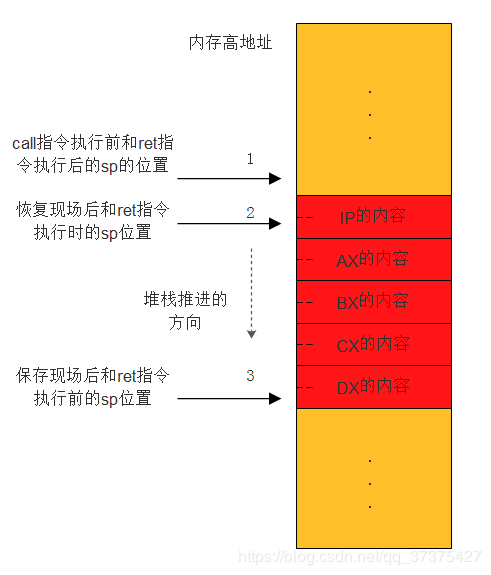
在call read_hard_disk_0指令执行前,栈指针位于箭头1 所指示的位置;call指令执行后,由于压入了IP的内容,故栈指针移动到箭头2 所指示的位置处;进入过程后,出于保护现场的目的,压入了4个通用寄存器AX,BX,CX,DX,此时栈指针继续向低地址方向推进到箭头3 所指示的位置。
在过程的最后,是恢复现场,连续反序弹出4个通用寄存器内容。此时栈指针又回到进入过程内部的位置,即箭头2 处。最后,ret指令执行时,由于处理器自动弹出一个字到IP寄存器,故过程返回后的瞬间,栈指针仍旧回到过程调用前,即箭头1 所指示的位置。然后处理器就继续之前的代码进行执行。
再回到上一段代码的意思,它是读程序的开始的一部分。
为什么要先读取程序的开始一部分呢(实际上是一个扇区512字节的大小)。因为这里面包含了程序的头部。加载器需要先将头部读进来,然后才能判断整个源程序的大小(防止多读或者少读),从而接着读剩下的代码。
代码清单8-2,30-55行,首先根据刚刚读的程序头,来计算用户程序的总长度。然后将整个程序代码加载进内存当中。这里的代码我就不贴了,可以自己看源码。下面我们先来看一下程序头部的各个条目在内存中目前的地址(偏移地址)。如下图:
由图中可知用户程序的总长度位于最开始的偏移地址为0的地方。并占有两个字。由此对比30-55行代码,将会更加清晰明了。
好了,整个用户程序已经被加载器加载到内存中了。那么接下来要做的就是对整个用户程序进行重定位工作了。
3.212、重定位用户程序
整个用户程序已经被加载器加载到内存中了。那么接下来要做的就是对整个用户程序进行重定位工作了。
实际上就是确定每个段的段地址即可(并不需要知道每一条指令的地址)。重定位实际上就是在现在这个真实的物理内存上计算出各个段的段地址,然后将真实的段地址再覆盖程序头部的各个段原来的汇编段地址即可。
由于用户程序的各个段的汇编地址是可以得出来的,所以我们可以计算各个段的长度。知道了各个段的长度,然后又知道用户程序在内存中的起始位置地址phy_base。那么就可以很容易计算出各个段在内存中的地址。如下图,清晰明了:
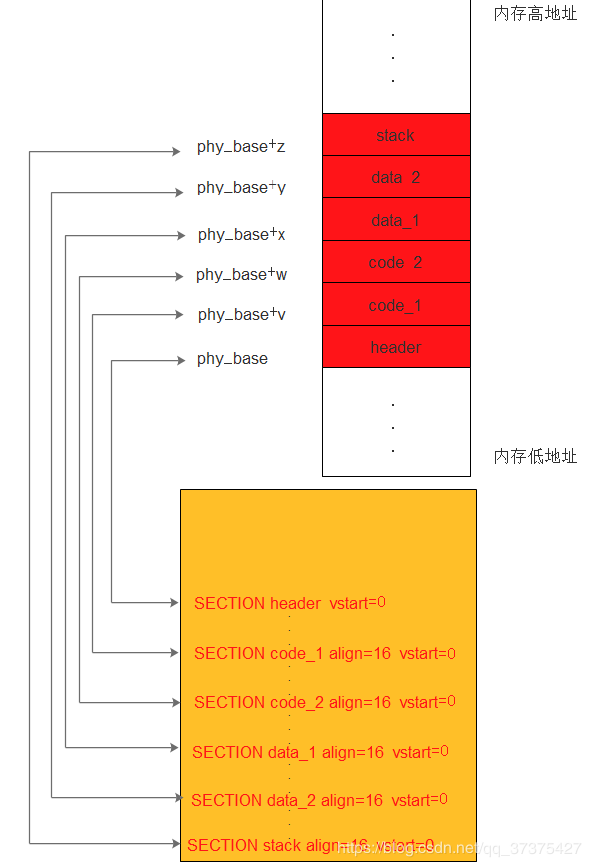
以上图示清晰的展示了内存中的各个段与源程序的汇编地址的表示的段的关系。
源程序58-62行重定位了用户程序的入口点的代码段。
65-74行,重定位其他各个段。
3.22 将控制权交给用户程序
76行代码:jmp far [0x04] ;转移到用户程序
当对用户程序的各个段进行了重定位后。就将控制权交给用户程序了。我们在此前知道用户程序的头结构在内存中的结构如下:
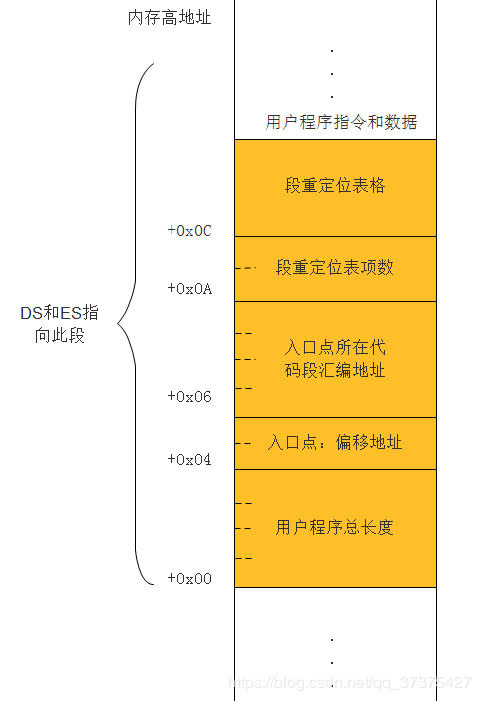
由此得知用处程序的入口点地址存在于内存的0x04处。所以上面来一个段间远跳转,将执行流跳转到内存偏移地址为0x04处。从而开始整个用户程序的执行。
就提是先访问DS所指向的数据段,从偏移地址0x04处取出两个字,并分别传送到代码段寄存器CS与指令指针寄存器IP,以替代他们原先的内容。于是处理器就自行转移到指定的位置开始执行指令。
至此,我们已经将用户程序运行起来了。真是相当的不容易啊!!!
4、总结
本片文章学会以下内容
-
用户程序的分段结构大致模样
-
用户程序的头部结构
-
加载器是如何加载用户程序到内存的
- 首先读用户程序开头一部分(一般是512字节),从而获取程序头部
- 再根据用户程序头部读取剩余的代码
-
将用户程序加载到内存后还需要对用户程序的各个段进行重定位
- 根据各个段的长度以及用户程序在内存中的起始位置计算重定位后的地址
-
重定位后,将控制权交给用户程序。这里直接给一个远跳转指令,跳转到用户程序的入口点执行即可。
以上内容对理解程序的结构非常有帮助。
笔记记得不是很全,像汇编的语法以及如何将代码写到虚拟硬盘的主引导扇区这些都没有写。如果又不懂的可以加我联系方式一起交流。
学习探讨加个人:
qq:1126137994
微信:liu1126137994