数据链路层的三个基本问题——封装成帧、透明传输和差错检测
参考资料:《计算机网络》第七版(谢希仁著)
一、封装成帧
封装成帧(framing)就是在一段数据的前后分别添加首部和尾部,这样就构成了一个帧,接收端在收到物理层上交的比特流后,就能根据首部和尾部的标记,从收到的比特流中识别帧的开始和结束。
分组交换的一个重要概念就是:所有在互联网上传送的数据都以分组(即IP数据报)为传送单位,网络层的IP数据报传送到数据链路层就成为帧的数据部分,在帧的数据部分的前面和后面分别添加上首部和尾部,构成了一个完整的帧,这样的帧就是数据链路层的数据传送单元,因此一个帧的帧长等于帧的数据部分长度加上帧首部和帧尾部的长度。
在发送帧时,是从帧首部开始发送的,到帧尾部结束,首部和尾部的一个重要作用就是进行帧定界(即确定帧的界限),此外,首部和尾部还包括许多必要的控制信息,因此各种数据链路层协议都对帧首部和帧尾部的格式有明确的规定。
为了提高帧的传输效率,应当使帧的数据部分长度尽可能地大于首部和尾部的长度,但是,每一种链路层协议都规定了所能传送的帧的数据部分长度上限——最大传送单元MTU(Maximum Transfer Unit)。

当数据是由可打印的ASCII码组成的文本文件时,帧定界可以使用特殊的帧定界符,ASCI码是7位编码,一共可组合成128个不同的ASCII码,其中可打印的有95个,而不可打印的控制字符有33个,注意,这里可打印的字符是指可以从键盘上输入的字符,我们使用的标准键盘有47个键可输入94个字符(包括使用Shift键),加上空格键,一共可输入95个可打印字符。
控制字符SOH(Start Of Header)放在一帧的最前面,表示帧的首部开始,另一个控制字符EOT(End Of Transmission)表示帧的结束,需注意的是,SOH和EOT都是控制字符的名称,当数据是由可打印的ASCII码组成的文本文件时,SOH和EOT的十六进制编码分别是01(二进制是0000001)和04(二进制是00000100)。

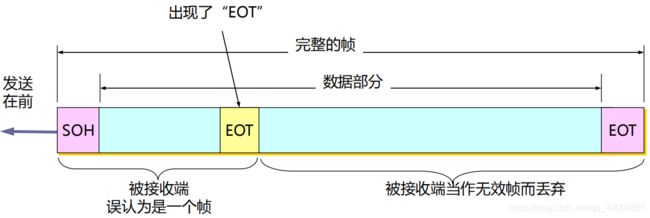
当数据在传输中出现差错时,帧定界符的作用更加明显。假定发送端在尚未发送完一个帧时突然出故障,中断了发送,但随后很快又恢复正常,于是重新从头开始发送刚才未发送完的帧,由于使用了帧定界符,接收端就知道前面收到的数据是个不完整的帧(只有首部开始符SOH而没有传输结束符EOT),必须丢弃,而后面收到的数据有明确的帧定界符(SOH和EOT),因此这是一个完整的帧,应当收下。
需注意的是,不同的协议使用的帧定界符也并不相同,但是它们的思想是相同的,都是对SOH和EOT的某种实现。
二、透明传输
由于帧的开始和结束的标记使用专门指明的控制字符,因此,所传输的数据中的任何8比特的组合一定不允许和用作帧定界的控制字符的比特编码一样,否则就会出现帧定界的错误。
当传送的帧是用文本文件组成的帧时(文本文件中的字符都是从键盘上输入的),其数据部分显然不会出现像SOH或EOT这样的帧定界控制字符,可见不管从键盘上输入什么字符都可以放在这样的帧中传输过去,因此这样的传输就是透明传输。
但是,当数据部分是非ASCI码的文本文件时(如二进制代码的计算机程序或图像等),情况就不同了,如果数据中的某个字节的二进制代码恰好和SOH或EOT这种控制字符一样,数据链路层就会错误地找到帧的边界,把部分帧收下(误认为是个完整的帧),而把剩下的那部分数据丢弃(这部分找不到帧定界控制字符SOH),如下图所示:
透明传输中的“透明”是一个很重要的术语,它表示某一个实际存在的事物看起来却好像不存在一样(例如,你看不见在你前面有块100%透明的玻璃的存在),在数据链路层透明传送数据表示无论什么样的比特组合的数据,都能够按照原样没有差错地通过这个数据链路层,因此,对所传送的数据来说,这些数据就看不见数据链路层有什么妨碍数据传输的东西,或者说,数据链路层对这些数据来说是透明的。
为了解决透明传输问题,就必须设法使数据中可能出现的与控制字符SOH或EOT相同的二进制代码在接收端不被解释为控制字符。
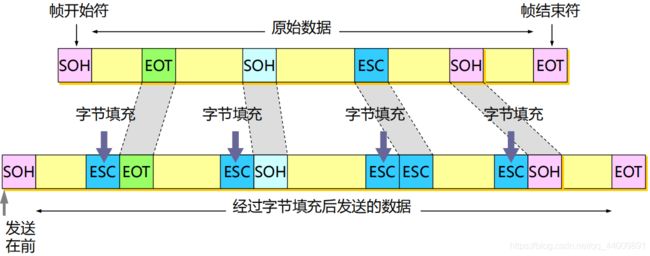
具体的方法是:发送端的数据链路层在数据中出现“SOH"或“EOT"的前面插入一个转义字符“ESC(其十六进制编码是1B,二进制是00011011),而接收端的数据链路层在把数据送往网络层之前删除这个插入的转义字符。这种方法称为字节填充(byte stuffing)或字符填充(character stuffing)。 如果转义字符也出现在数据当中,那么解决方法仍然是在转义字符的前面插入一个转义字符。因此,当接收端收到连续的两个转义字符时,就删除其中前面的一个。
三、差错检测
现实的通信链路都不会是理想的,因此数据帧在传输中通常可能发生以下两种错误:
-
比特差错:比特在传输过程中可能会产生差错,1可能会变成0,而0也可能变成1。
在一段时间内,传输错误比特的数量占所传输比特总数的比率称为误码率BER(Bit Error Rate),例如,误码率为0.1时,表示平均每传送10个比特就会出现一个比特的差错。误码率与信噪比有很大的关系,信噪比越高,误码率越低,因此如果设法提高信噪比,就可以使误码率减小。
但是,实际的通信链路并非是理想的,它不可能使误码率下降到零,因此,为了保证数据传输的可靠性,在计算机网络传输数据时,必须采用各种差错检测措施,目前在数据链路层广泛使用了循环冗余检验CRC(Cyclic Redundancy Check)的检错技术。
下面通过一个简单的例子来说明循环冗余检验的原理,现假定待传送的数据M = 1101011011(k=10)。
CRC的基本原理:
-
在发送端,先把数据划分为组,假定每组k个比特。
-
通过CRC运算,在数据M的后面添加供差错检测用的n位冗余码,然后构成一个帧发送出去,一共发送(k+n)位。在所要发送的数据后面增加n位的冗余码,虽然增大了数据传输的开销,但却可以进行差错检测,当传输可能出现差错时,付出这种代价往往是很值得的。
- CRC运算的过程:
-
用二进制数的模2乘法进行2ⁿ乘M的运算,这相当于在M后面添加n个0,得到的(k+n)位的数使用模2除法除以收发双方事先商定的长度为(n+1)位的除数P,得出商是Q而余数是R(n位,比P少一位),关于模2运算的具体内容请参照:模2运算。
-
假定除数P= 10011(即n = 4),则经模2除法运算后的结果是:商Q = 1100001010(这个商并没有什么用处),而余数R = 1110,这个余数R就作为冗余码拼接在数据M的后面发送出去。
-
这种为了进行检错而添加的冗余码常称为帧检验序列FCS(Frame Check Sequence),因此加上FCS后发送的帧是11010110111110(即2ⁿ × M + FCS,这里的×是模2乘法),共有(k + n)位。需注意的是,循环冗余检验CRC和帧检验序列FCS并不是同一个概念,CRC是一种检错方法,而FCS是添加在数据后面的冗余码,在检错方法上可以选用CRC,但也可不选用CRC。
-

-
在接收端,先从接收的数据帧中提取出n位冗余码,进行CRC检验,如果检验的结果正确,则接受(accept)数据帧,如果检验的结果不正确,则直接丢弃,可见,CRC检验不能确定错误发生的原因,只能判断数据帧是否正确。
- CRC检验的过程:
-
把收到的每一个帧都除以同样的除数P(模2除法),然后检查得到的余数R,如果在传输过程中无差错,那么经过CRC检验后得出的余数R肯定是0,但如果出现误码,那么余数R仍等于零的概率是非常非常小的。
-
在接收端对收到的每一帧经过CRC检验后,一般有以下两种情况:
-
若得出的余数R=0,则判定这个帧没有差错,就接受(accept);
-
若得出的余数R≠0,则判定这个帧有差错(但无法确定究竟是哪一位或哪几位出现了差错),就丢弃。
-
徐注意的是,在数据链路层,发送端帧检验序列FCS的生成和接收端的CRC检验都是用硬件完成的,处理很迅速,因此并不会延误数据的传输。
从以上不难看出,如果我们在传送数据时不以帧为单位来传送,那么就无法加入冗余码以进行差错检验,因此,如果要在数据链路层进行差错检验,就必须把数据划分为帧,每一帧都加上冗余码,一帧接一帧地传送,然后在接收方逐帧进行差错检验。
-
-
传输差错:收到的帧没有出现比特差错,但却出现了帧丢失、帧重复和帧失序。
例如,发送方连续传送三个帧: ABC,假定接收端收到的每一个帧都没有比特差错,但却出现下面的几种情况:
-
帧丢失:收到AC(丢失B);
-
帧重复:收到ABBC(收到两个B);
-
帧失序:收到ACB(后发送的帧反而先到达了接收端,这与一般数据链路层的传输概念不一样)。
因此,我们应当明确,“无比特差错”与“无传输差错”并不是同样的概念,在数据链路层使用CRC检验,能够实现无比特差错的传输,但这还不是可靠传输。
-
强调一下,在数据链路层若仅仅使用循环冗余检验CRC差错检测技术,则只能做到对帧的无差错接受(即认为:凡是接收端数据链路层接受的帧,我们都能以非常接近于1的概率认为这些帧在传输过程中没有产生差错),接收端丢弃的帧虽然曾收到了,但最终还是因为有差错被丢弃,即没有被接受,以上所述的可以近似地表述为(通常都是这样认为):“凡是接收端数据链路层接受的帧均无差错”。
需注意的是,通常并不要求数据链路层向网络层提供可靠传输的服务,所谓可靠传输就是数据链路层的发送端发送什么,在接收端就收到什么,一般有以下两种情况:
-
对于通信质量良好的有线传输链路,数据链路层协议不使用确认和重传机制,即不要求数据链路层向上提供可靠传输的服务,如果在数据链路层传输数据时出现了差错并且需要进行改正,那么改正差错的任务就由上层协议(例如,运输层的TCP协议)来完成。
-
对于通信质量较差的无线传输链路,数据链路层协议使用确认和重传机制,数据链路层向上提供可靠传输的服务。