数学建模之时间序列模型及其应用
摘要
时间序列模型就是将预测对象按照时间顺序排列起来,用这一组时间序列过去的变化规律,推断今后变化的可能性及变化趋势、变化规律。
时间序列模型也是一种回归模型,其一方面承认事物发展的延续性,运用过去的数据来推测事物的发展趋势;另一方面又考虑到偶然因素产生的随机性,为了消除随机波动的影响,利用历史数据,进行统计分析,并对数据进行适当的处理,进行趋势预测。
- 优点是简单易行,便于掌握,能够充分运用原时间序列的各项数据,计算速度快,对模型参数有动态确定的能力,精度较好,采用组合的时间序列或者把时间序列和其他模型组合效果更好。
- 缺点是不能反映事物的内在联系,不能分析两个因素的相关关系,只适用于短期预测。
确定性时间序列分析
确定性因素分解
- 长期趋势变动(T):它是指时间序列朝着一 定的方向持续_上升或下降,或停留在某一水平上的倾向,它反映了客观事物的主要变化趋势。
- 季节变动(S):受季节变动影响所形成的一种长度和幅度固定的周期性波动。
- 循环变动©:通常是指周期为一年以上,由非季节因素引起的涨落起伏波形相似的波动。
- 不规则变动®:通常它分为突然变动和随机变动。
常用的确定性时间序列模型有:

随机时间序列的两个重要性质
通常根平稳性和随机性来描述一个完全没有信息的时间序列,也称为白噪声。
严平稳
严平稳是一种条件比较苛刻的平稳性定义,它认为只有当序列所有的统计性质都不会随着时间的推移而发生变化时,该序列才能被认为平稳。
宽平稳
宽平稳是使用序列的特征统计量(均值方差等)来定义的一种平稳性。它认为序列的统计性质主要由它的低阶矩决定,所以只要保证序列低阶矩平稳(二阶),就能保证序列的主要性质近似稳定。
平稳性检验
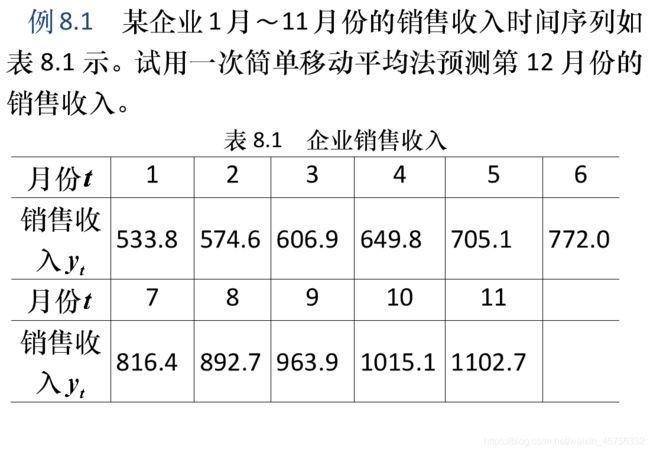
图检验方法(时序图检验、自相关图检验)
特点:操作简单,应用广泛,但结论带有一定主观
性。
统计检验方法(单位根检验)
特点:根据特征根是否在单位圆内来判断平稳性,有多种类型,结果具有客观性。
移动平均法

移动就是移动,平均就是平均,比如我们取4个数来移动平均。就是先用前四个数求平均,来代表第5个值;2: 5求平均代表第6个值;8:11求平均代表第12个值。(个人认为这没啥逻辑性。。。也可能是我理解错了,懂的同学还望指出,这是司守奎168页的内容)。
这里我们选了4和5个数来实验,其评判标准为标准差,越小精度越好、
clc,clear
y=[533.8 574.6 606.9 649.8 705.1 772.0 816.4 892.7 963.9 1015.1 1102.7];
m=length(y);
n=[4,5]; %n为移动平均的项数
for i=1:length(n) %由于n的取值不同,下面使用了细胞数组
for j=1:m-n(i)+1
yhat{i}(j)=sum(y(j:j+n(i)-1))/n(i);
end
y12(i)=yhat{i}(end) %提出第12月份的预测值
s(i)=sqrt(mean((y(n(i)+1:end)-yhat{i}(1:end-1)).^2)) %求预测的标准误差
end
% y12, s %分别显示两种方法的预测值和预测的标准误差
plot([1:11],y,[1:12],[y(1:4) yhat{1}])
legend('原始数据图','预测图')
y12 =
993.6000 958.1600
s =
150.5121 182.3851
993的标准差更小,所以99205更好,但作图看看。。。这是书上的实例可以自行去看

指数平滑法
一次移动平均实际上认为最近 N 期数据对未来值影响相同,都加权
1/N ;而 N 期以前的数据对未来值没有影响,加权为 0。但是,二次及更高次移动平均数的权数却不是 1/N ,且次数越高,权数的结构越复杂,但永远保持对称的权数,即两端项权数小,中间项权数大,不符合一般系统的动态性。一般说来历史数据对未来值的影响是随时间间隔的增长而递减的。所以,更切合实际的方法应是对各期观测值依时间顺序进行加权平均作为预测值。指数平滑法可满足这一要求,而且具有简单的递推形式。指数平滑法根据平滑次数的不同,又分为一次指数平滑法、二次指数平滑法和三次指数平滑法等,分别介绍如下。
一次指数平滑法
和移动平均法差不多,只不过是用了前两次的平均值代表后一个数,然后加了个权重。
还是看例子吧,数学公式写了也看不很明白。
| 例题、某市 1976~1987 年某种电器销售额如表 4 所示。试预测 1988 年该电器销售额。 |
解 采用指数平滑法,并分别取α = 0.2,0.5和0.8进行计算,初始值

 表 4 某种电器销售额及指数平滑预测值计算表 (单位:万元)
表 4 某种电器销售额及指数平滑预测值计算表 (单位:万元)
clc,clear
yt=[50 52 47 51 49 48 51 40 48 52 51 59]'; %实际销售额数据以列向量的方式存放在纯文本文件中
n=length(yt);
alpha=[0.2 0.5 0.8];
m=length(alpha);
yhat(1,[1:m])=(yt(1)+yt(2))/2;
for i=2:n
yhat(i,:)=alpha*yt(i-1)+(1-alpha).*yhat(i-1,:);
end
yhat
err=sqrt(mean((repmat(yt,1,m)-yhat).^2))
xlswrite('dianqi.xls',yhat) %把预测数据写到Excel文件,准备在word表格中使用
yhat1988=alpha*yt(n)+(1-alpha).*yhat(n,:)
yhat =
51.0000 51.0000 51.0000
50.8000 50.5000 50.2000
51.0400 51.2500 51.6400
50.2320 49.1250 47.9280
50.3856 50.0625 50.3856
50.1085 49.5313 49.2771
49.6868 48.7656 48.2554
49.9494 49.8828 50.4511
47.9595 44.9414 42.0902
47.9676 46.4707 46.8180
48.7741 49.2354 50.9636
49.2193 50.1177 50.9927
err =
4.5029 4.5908 4.8426
yhat1988 =
51.1754 54.5588 57.3985
这里三个权值对应的标准差相差并不大,但肯定要取最小的,所以是4.5也就是权值为0.2的那个,计算出值为51.1754,这个数据本身就不是很好,感觉好没有太大的变化规律或者趋势,预测的肯定也不怎么样。
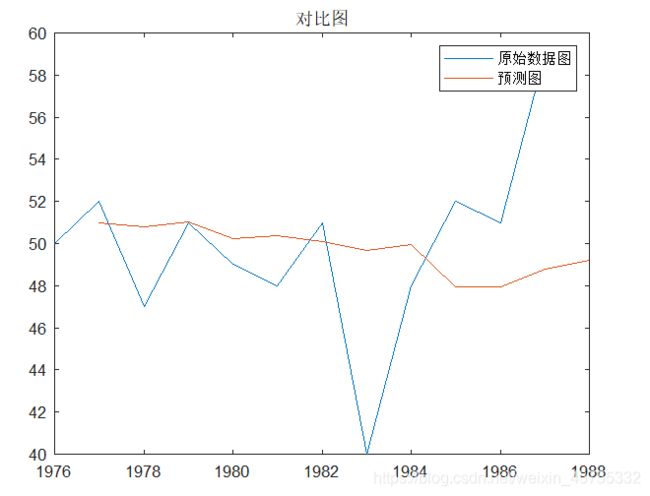
这个模型用于第一个例题试试

相对来说好多了,最终预测值为1082
二次指数平滑法
仍以例 3 我国 1965~1985 年的发电总量资料为例,试用二次指数平滑法预
测 1986 年和 1987 年的发电总量。
 表 6 我国发电总量及一、二次指数平滑值计算表
表 6 我国发电总量及一、二次指数平滑值计算表

clc,clear
yt=[676,825,774,716,940,1159,1384,1524,1668,1688,1958,2031,2234,2566,2820,3006,3093,3277,3514,3770,4107];
n=length(yt), alpha=0.3; st1(1)=yt(1); st2(1)=yt(1);
for i=2:n
st1(i)=alpha*yt(i)+(1-alpha)*st1(i-1);%一次平滑值
st2(i)=alpha*st1(i)+(1-alpha)*st2(i-1);%二次平滑值,和一次一个样,相当于把一次平滑值的结果作为原式数据进行计算
end
xlswrite('fadian.xls',[st1',st2']) %把数据写入表单Sheet1中的前两列
at=2*st1-st2;
bt=alpha/(1-alpha)*(st1-st2);
yhat=at+bt; %最后的一个分量为1986年的预测值
xlswrite('fadian.xls',yhat','Sheet1','C2') %把预测值写入第3列
str=['C',int2str(n+2)] %准备写1987年预测值位置的字符串
xlswrite('fadian.xls',at(n)+2*bt(n),'Sheet1',str)%把1987年预测值写到相应位置
plot([1965:1985],yt,[1966:1986], yhat)
legend('原始数据图','预测图')
title("对比图")
得到86 87两年的数据为
4.2239e+03
4.4342e+03
总体来看效果可以

还是用于第一题的数据
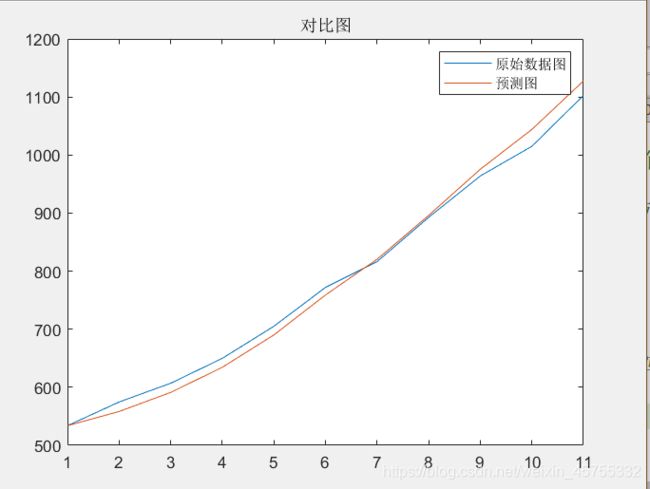
简直翻天覆地啊。这个很可以。
三次指数平滑法
某省 1978~1988 年全民所有制单位固定资产投资总额如表 7 所示,试预测
1989 年和 1990 年固定资产投资总额
 表 7 某省全民所有制单位固定资产投资总额及一、二、三次指数平滑值计算表(单位:亿元)
表 7 某省全民所有制单位固定资产投资总额及一、二、三次指数平滑值计算表(单位:亿元)


clc,clear
yt=load('touzi.txt'); %原始投资总额数据以列向量的方式存放在纯文本文件中
n=length(yt); alpha=0.25; st0=mean(yt(1:3));
st1(1)=alpha*yt(1)+(1-alpha)*st0;
st2(1)=alpha*st1(1)+(1-alpha)*st0;
st3(1)=alpha*st2(1)+(1-alpha)*st0;
for i=2:n
st1(i)=alpha*yt(i)+(1-alpha)*st1(i-1);
st2(i)=alpha*st1(i)+(1-alpha)*st2(i-1);
st3(i)=alpha*st2(i)+(1-alpha)*st3(i-1);
end
xlswrite('touzi.xls',[st1',st2',st3']) %把数据写在前三列
at=3*st1-3*st2+st3;
bt=0.5*alpha/(1-alpha)^2*((6-5*alpha)*st1-2*(5-4*alpha)*st2+(4-3*alpha)*st3);
ct=0.5*alpha^2/(1-alpha)^2*(st1-2*st2+st3);
yhat=at+bt+ct;
xlswrite('touzi.xls',yhat','Sheet1','D2') %把数据写在第4列第2行开始的位置
plot(1:n,yt,'D',2:n,yhat(1:end-1),'*')
legend('实际值','预测值','Location','northwest') %图注显示在左上角
xishu=[ct(end),bt(end),at(end)]; %二次预测多项式的系数向量
yhat1990=polyval(xishu,2) %求预测多项式m=2时的值
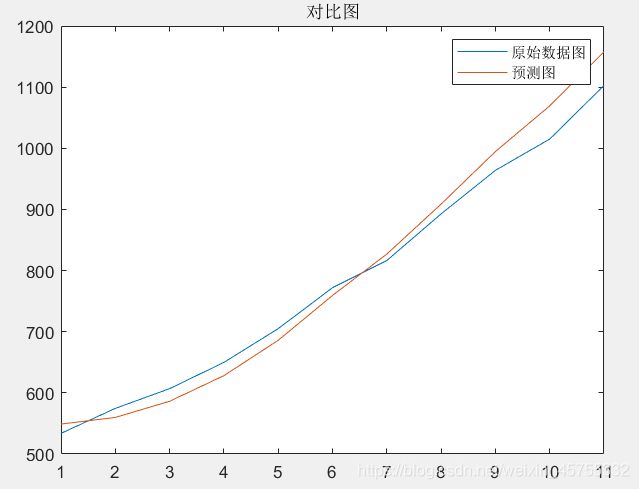
plot([1:11],yt,[1:11], yhat)
legend('原始数据图','预测图')
title("对比图")
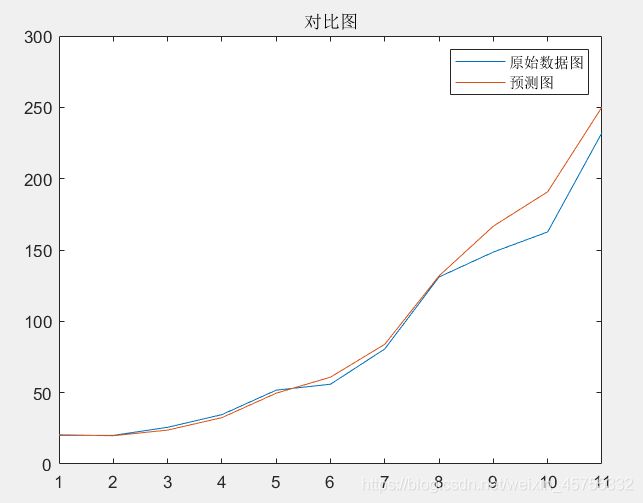
用于第一题,看起来也不错。
后面的有点难,自己没怎么看懂,先不写了吧